 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiME: Multilevel Medical Embedding of Electronic Health Records for Predictive Healthcare
Oct 22, 2018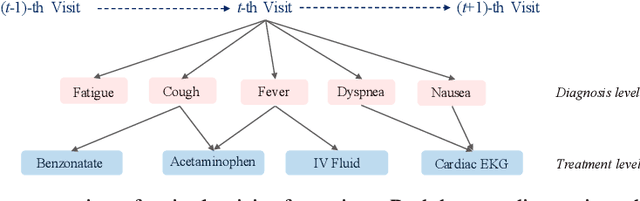

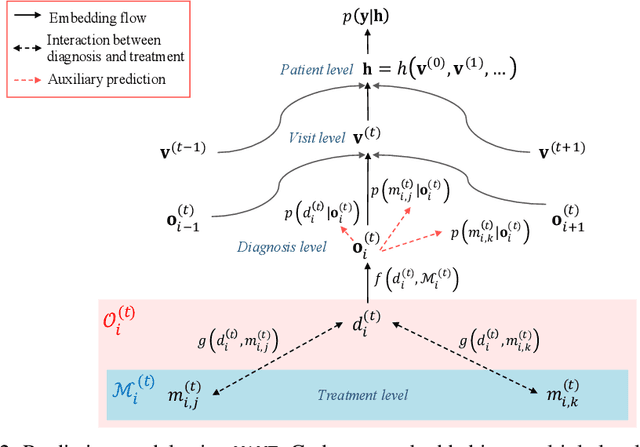
Deep learning models exhibit state-of-the-art performance for many predictive healthcare tasks using electronic health records (EHR) data, but these models typically require training data volume that exceeds the capacity of most healthcare systems. External resources such as medical ontologies are used to bridge the data volume constraint, but this approach is often not directly applicable or useful because of inconsistencies with terminology. To solve the data insufficiency challenge, we leverage the inherent multilevel structure of EHR data and, in particular, the encoded relationships among medical codes. We propose Multilevel Medical Embedding (MiME) which learns the multilevel embedding of EHR data while jointly performing auxiliary prediction tasks that rely on this inherent EHR structure without the need for external labels. We conducted two prediction tasks, heart failure prediction and sequential disease prediction, where MiME outperformed baseline methods in diverse evaluation settings. In particular, MiME consistently outperformed all baselines when predicting heart failure on datasets of different volumes, especially demonstrating the greatest performance improvement (15% relative gain in PR-AUC over the best baseline) on the smallest dataset, demonstrating its ability to effectively model the multilevel structure of EHR data.
SUSTain: Scalable Unsupervised Scoring for Tensors and its Application to Phenotyping
Mar 14, 2018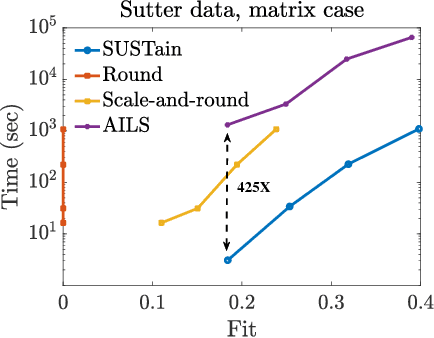

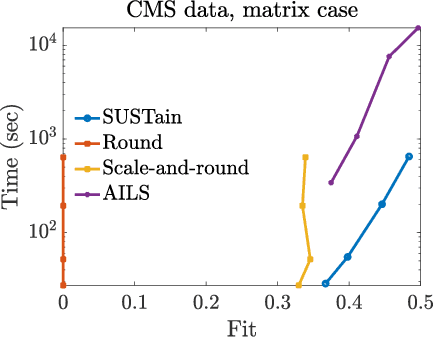
This paper presents a new method, which we call SUSTain, that extends real-valued matrix and tensor factorizations to data where values are integers. Such data are common when the values correspond to event counts or ordinal measures. The conventional approach is to treat integer data as real, and then apply real-valued factorizations. However, doing so fails to preserve important characteristics of the original data, thereby making it hard to interpret the results. Instead, our approach extracts factor values from integer datasets as scores that are constrained to take values from a small integer set. These scores are easy to interpret: a score of zero indicates no feature contribution and higher scores indicate distinct levels of feature importance. At its core, SUSTain relies on: a) a problem partitioning into integer-constrained subproblems, so that they can be optimally solved in an efficient manner; and b) organizing the order of the subproblems' solution, to promote reuse of shared intermediate results. We propose two variants, SUSTain_M and SUSTain_T, to handle both matrix and tensor inputs, respectively. We evaluate SUSTain against several state-of-the-art baselines on both synthetic and real Electronic Health Record (EHR) datasets. Comparing to those baselines, SUSTain shows either significantly better fit or orders of magnitude speedups that achieve a comparable fit (up to 425X faster). We apply SUSTain to EHR datasets to extract patient phenotypes (i.e., clinically meaningful patient clusters). Furthermore, 87% of them were validated as clinically meaningful phenotypes related to heart failure by a cardiologist.
Generating Multi-label Discrete Patient Records using Generative Adversarial Networks
Jan 11, 2018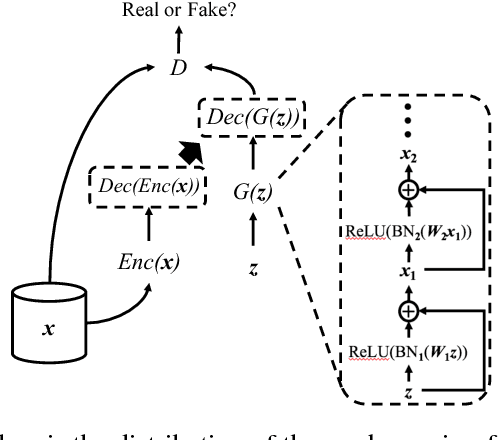
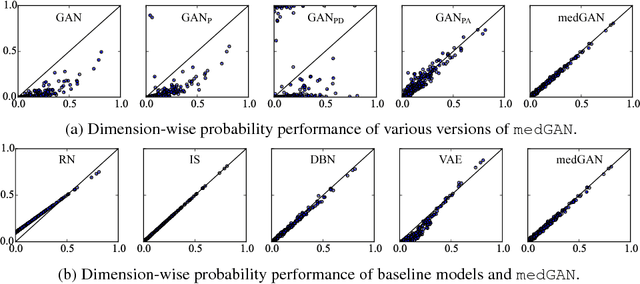
Access to electronic health record (EHR) data has motivated computational advances in medical research. However, various concerns, particularly over privacy, can limit access to and collaborative use of EHR data. Sharing synthetic EHR data could mitigate risk. In this paper, we propose a new approach, medical Generative Adversarial Network (medGAN), to generate realistic synthetic patient records. Based on input real patient records, medGAN can generate high-dimensional discrete variables (e.g., binary and count features) via a combination of an autoencoder and generative adversarial networks. We also propose minibatch averaging to efficiently avoid mode collapse, and increase the learning efficiency with batch normalization and shortcut connections. To demonstrate feasibility, we showed that medGAN generates synthetic patient records that achieve comparable performance to real data on many experiments including distribution statistics, predictive modeling tasks and a medical expert review. We also empirically observe a limited privacy risk in both identity and attribute disclosure using medGAN.
Medical Concept Representation Learning from Electronic Health Records and its Application on Heart Failure Prediction
Jun 20, 2017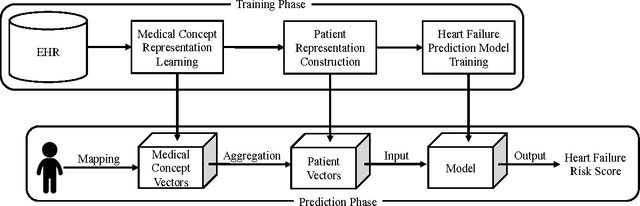
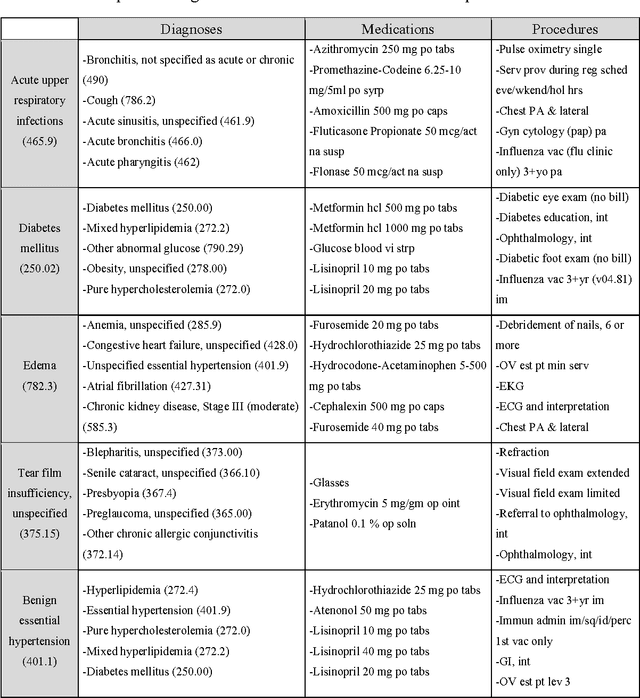
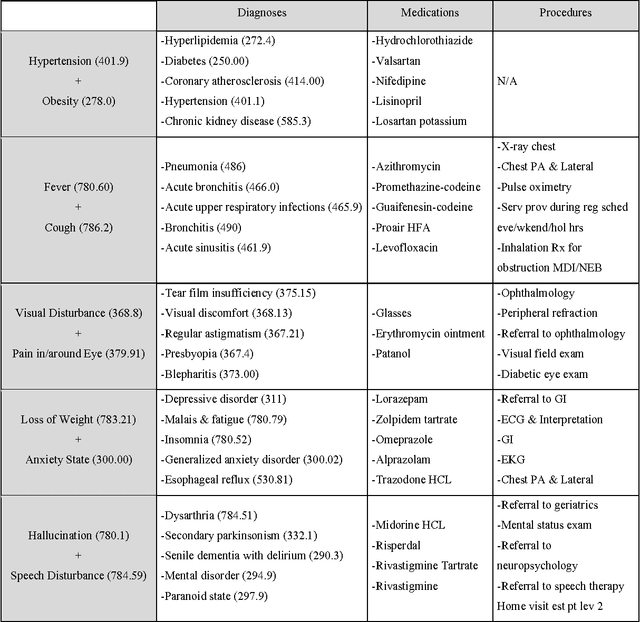
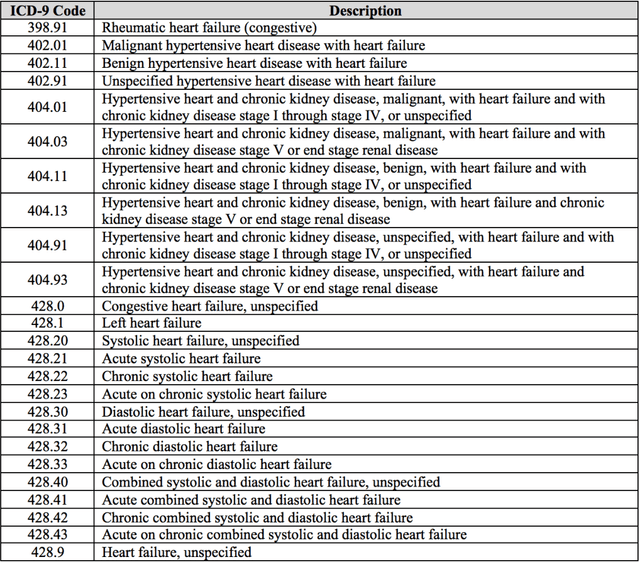
Objective: To transform heterogeneous clinical data from electronic health records into clinically meaningful constructed features using data driven method that rely, in part, on temporal relations among data. Materials and Methods: The clinically meaningful representations of medical concepts and patients are the key for health analytic applications. Most of existing approaches directly construct features mapped to raw data (e.g., ICD or CPT codes), or utilize some ontology mapping such as SNOMED codes. However, none of the existing approaches leverage EHR data directly for learning such concept representation. We propose a new way to represent heterogeneous medical concepts (e.g., diagnoses, medications and procedures) based on co-occurrence patterns in longitudinal electronic health records. The intuition behind the method is to map medical concepts that are co-occuring closely in time to similar concept vectors so that their distance will be small. We also derive a simple method to construct patient vectors from the related medical concept vectors. Results: For qualitative evaluation, we study similar medical concepts across diagnosis, medication and procedure. In quantitative evaluation, our proposed representation significantly improves the predictive modeling performance for onset of heart failure (HF), where classification methods (e.g. logistic regression, neural network, support vector machine and K-nearest neighbors) achieve up to 23% improvement in area under the ROC curve (AUC) using this proposed representation. Conclusion: We proposed an effective method for patient and medical concept representation learning. The resulting representation can map relevant concepts together and also improves predictive modeling performance.
GRAM: Graph-based Attention Model for Healthcare Representation Learning
Apr 01, 2017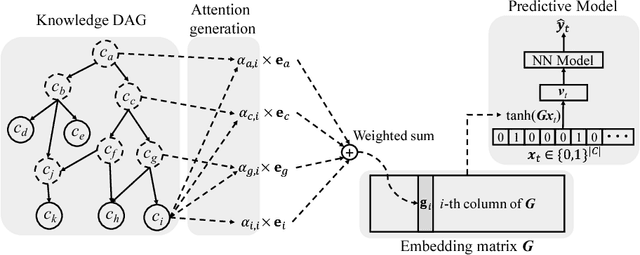
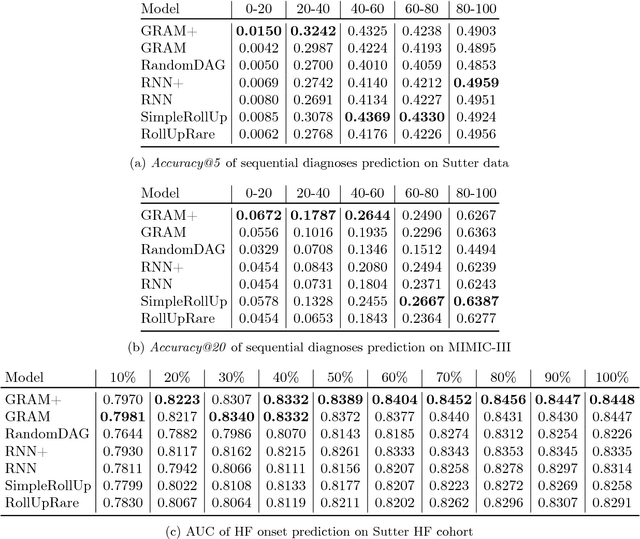

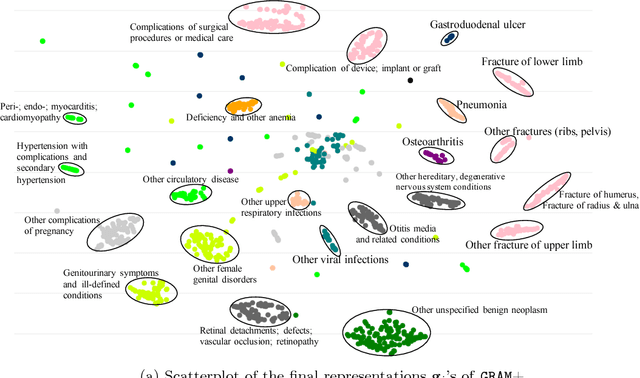
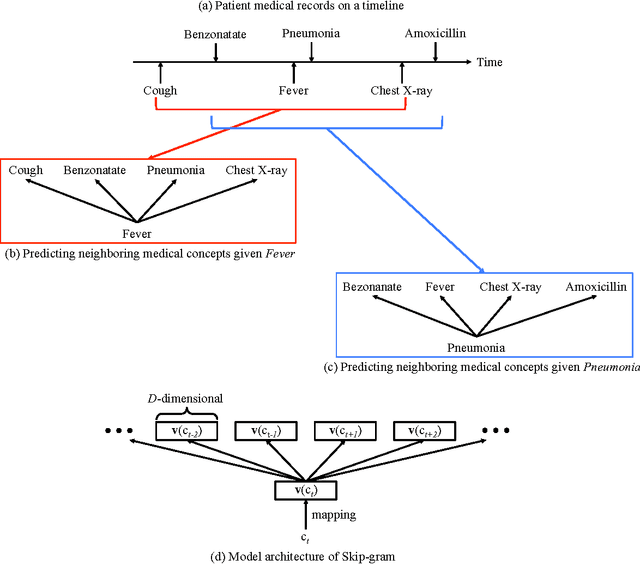
Deep learning methods exhibit promising performance for predictive modeling in healthcare, but two important challenges remain: -Data insufficiency:Often in healthcare predictive modeling, the sample size is insufficient for deep learning methods to achieve satisfactory results. -Interpretation:The representations learned by deep learning methods should align with medical knowledge. To address these challenges, we propose a GRaph-based Attention Model, GRAM that supplements electronic health records (EHR) with hierarchical information inherent to medical ontologies. Based on the data volume and the ontology structure, GRAM represents a medical concept as a combination of its ancestors in the ontology via an attention mechanism. We compared predictive performance (i.e. accuracy, data needs, interpretability) of GRAM to various methods including the recurrent neural network (RNN) in two sequential diagnoses prediction tasks and one heart failure prediction task. Compared to the basic RNN, GRAM achieved 10% higher accuracy for predicting diseases rarely observed in the training data and 3% improved area under the ROC curve for predicting heart failure using an order of magnitude less training data. Additionally, unlike other methods, the medical concept representations learned by GRAM are well aligned with the medical ontology. Finally, GRAM exhibits intuitive attention behaviors by adaptively generalizing to higher level concepts when facing data insufficiency at the lower level concepts.
RETAIN: An Interpretable Predictive Model for Healthcare using Reverse Time Attention Mechanism
Feb 26, 2017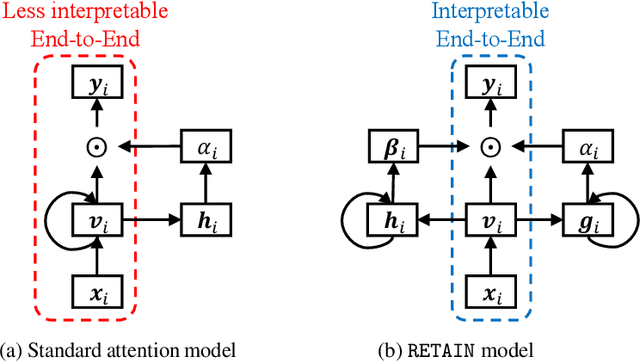

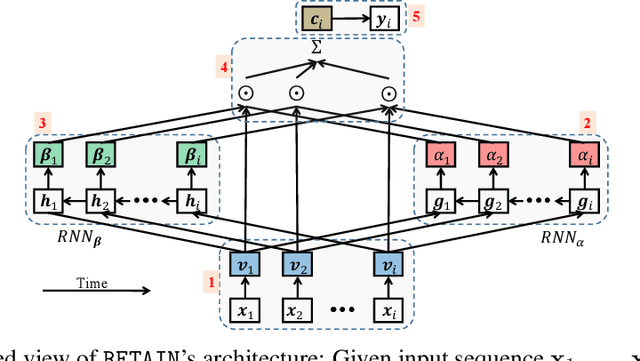
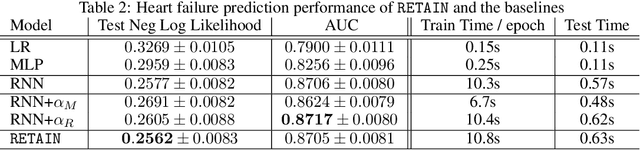
Accuracy and interpretability are two dominant features of successful predictive models. Typically, a choice must be made in favor of complex black box models such as recurrent neural networks (RNN) for accuracy versus less accurate but more interpretable traditional models such as logistic regression. This tradeoff poses challenges in medicine where both accuracy and interpretability are important. We addressed this challenge by developing the REverse Time AttentIoN model (RETAIN) for application to Electronic Health Records (EHR) data. RETAIN achieves high accuracy while remaining clinically interpretable and is based on a two-level neural attention model that detects influential past visits and significant clinical variables within those visits (e.g. key diagnoses). RETAIN mimics physician practice by attending the EHR data in a reverse time order so that recent clinical visits are likely to receive higher attention. RETAIN was tested on a large health system EHR dataset with 14 million visits completed by 263K patients over an 8 year period and demonstrated predictive accuracy and computational scalability comparable to state-of-the-art methods such as RNN, and ease of interpretability comparable to traditional models.
Causal Regularization
Feb 23, 2017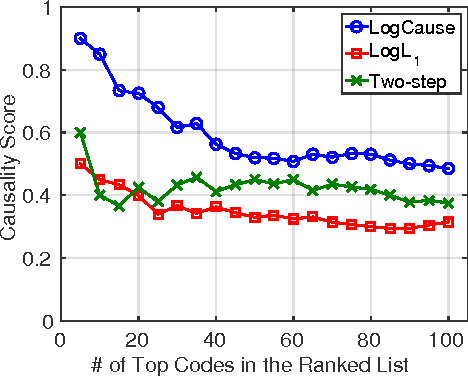

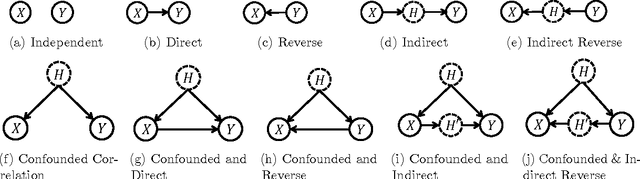

In application domains such as healthcare, we want accurate predictive models that are also causally interpretable. In pursuit of such models, we propose a causal regularizer to steer predictive models towards causally-interpretable solutions and theoretically study its properties. In a large-scale analysis of Electronic Health Records (EHR), our causally-regularized model outperforms its L1-regularized counterpart in causal accuracy and is competitive in predictive performance. We perform non-linear causality analysis by causally regularizing a special neural network architecture. We also show that the proposed causal regularizer can be used together with neural representation learning algorithms to yield up to 20% improvement over multilayer perceptron in detecting multivariate causation, a situation common in healthcare, where many causal factors should occur simultaneously to have an effect on the target variable.
Doctor AI: Predicting Clinical Events via Recurrent Neural Networks
Sep 28, 2016
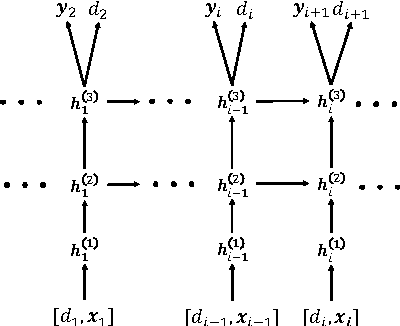
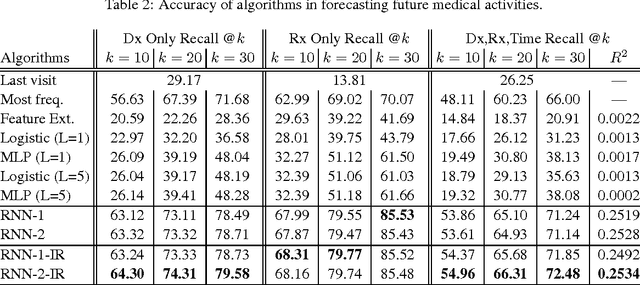
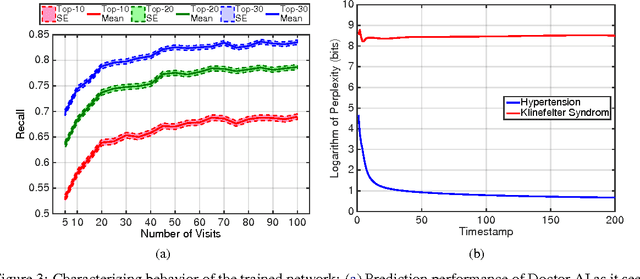
Leveraging large historical data in electronic health record (EHR), we developed Doctor AI, a generic predictive model that covers observed medical conditions and medication uses. Doctor AI is a temporal model using recurrent neural networks (RNN) and was developed and applied to longitudinal time stamped EHR data from 260K patients over 8 years. Encounter records (e.g. diagnosis codes, medication codes or procedure codes) were input to RNN to predict (all) the diagnosis and medication categories for a subsequent visit. Doctor AI assesses the history of patients to make multilabel predictions (one label for each diagnosis or medication category). Based on separate blind test set evaluation, Doctor AI can perform differential diagnosis with up to 79% recall@30, significantly higher than several baselines. Moreover, we demonstrate great generalizability of Doctor AI by adapting the resulting models from one institution to another without losing substantial accuracy.