 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Zero-shot Video Classification: End-to-end Training for Realistic Applications
Mar 10, 2020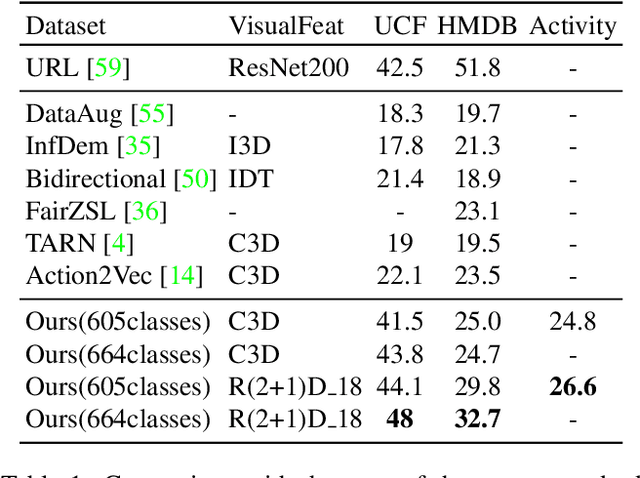
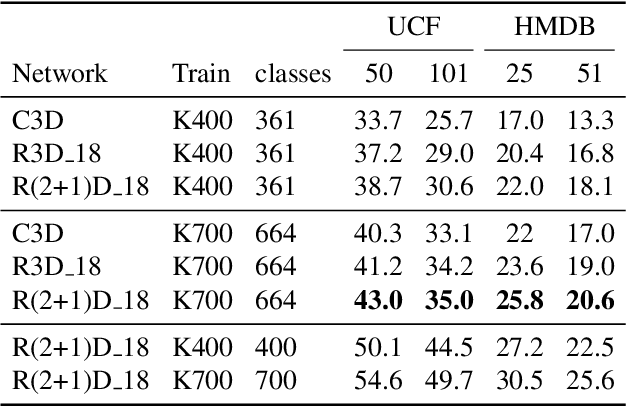
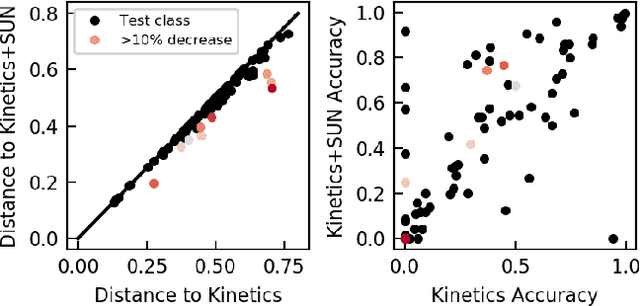
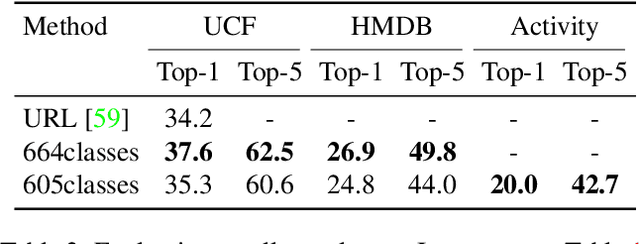
Trained on large datasets, deep learning (DL) can accurately classify videos into hundreds of diverse classes. However, video data is expensive to annotate. Zero-shot learning (ZSL) proposes one solution to this problem. ZSL trains a model once, and generalizes to new tasks whose classes are not present in the training dataset. We propose the first end-to-end algorithm for ZSL in video classification. Our training procedure builds on insights from recent video classification literature and uses a trainable 3D CNN to learn the visual features. This is in contrast to previous video ZSL methods, which use pretrained feature extractors. We also extend the current benchmarking paradigm: Previous techniques aim to make the test task unknown at training time but fall short of this goal. We encourage domain shift across training and test data and disallow tailoring a ZSL model to a specific test dataset. We outperform the state-of-the-art by a wide margin. Our code, evaluation procedure and model weights are available at github.com/bbrattoli/ZeroShotVideoClassification.
Fast Conditional Independence Test for Vector Variables with Large Sample Sizes
Apr 08, 2018
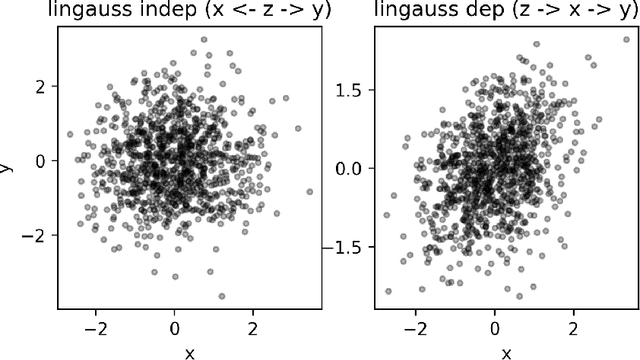

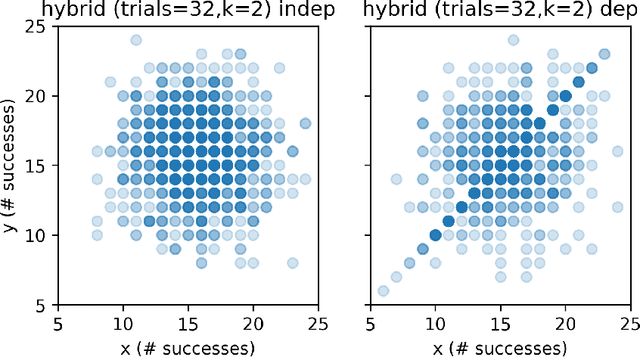
We present and evaluate the Fast (conditional) Independence Test (FIT) -- a nonparametric conditional independence test. The test is based on the idea that when $P(X \mid Y, Z) = P(X \mid Y)$, $Z$ is not useful as a feature to predict $X$, as long as $Y$ is also a regressor. On the contrary, if $P(X \mid Y, Z) \neq P(X \mid Y)$, $Z$ might improve prediction results. FIT applies to thousand-dimensional random variables with a hundred thousand samples in a fraction of the time required by alternative methods. We provide an extensive evaluation that compares FIT to six extant nonparametric independence tests. The evaluation shows that FIT has low probability of making both Type I and Type II errors compared to other tests, especially as the number of available samples grows. Our implementation of FIT is publicly available.
Causal Regularization
Feb 23, 2017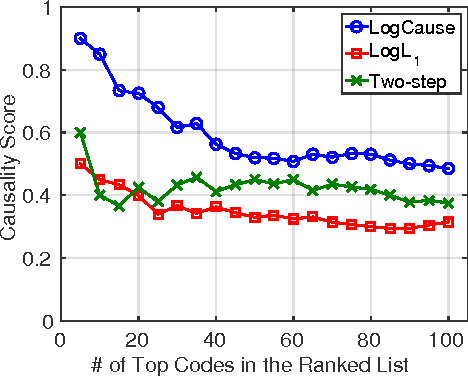

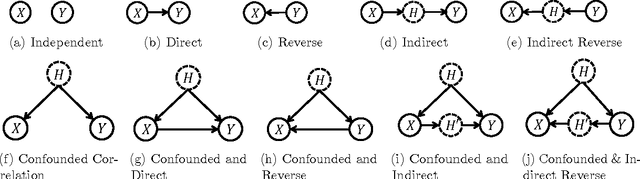

In application domains such as healthcare, we want accurate predictive models that are also causally interpretable. In pursuit of such models, we propose a causal regularizer to steer predictive models towards causally-interpretable solutions and theoretically study its properties. In a large-scale analysis of Electronic Health Records (EHR), our causally-regularized model outperforms its L1-regularized counterpart in causal accuracy and is competitive in predictive performance. We perform non-linear causality analysis by causally regularizing a special neural network architecture. We also show that the proposed causal regularizer can be used together with neural representation learning algorithms to yield up to 20% improvement over multilayer perceptron in detecting multivariate causation, a situation common in healthcare, where many causal factors should occur simultaneously to have an effect on the target variable.
Estimating Causal Direction and Confounding of Two Discrete Variables
Nov 04, 2016


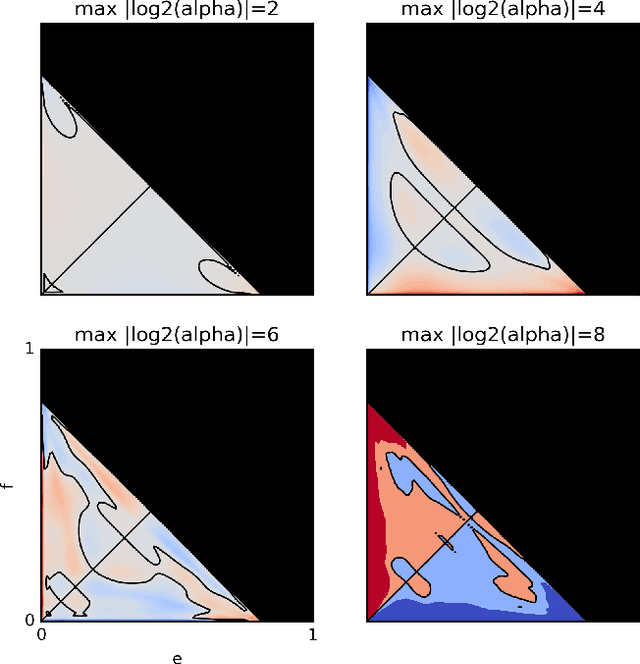
We propose a method to classify the causal relationship between two discrete variables given only the joint distribution of the variables, acknowledging that the method is subject to an inherent baseline error. We assume that the causal system is acyclicity, but we do allow for hidden common causes. Our algorithm presupposes that the probability distributions $P(C)$ of a cause $C$ is independent from the probability distribution $P(E\mid C)$ of the cause-effect mechanism. While our classifier is trained with a Bayesian assumption of flat hyperpriors, we do not make this assumption about our test data. This work connects to recent developments on the identifiability of causal models over continuous variables under the assumption of "independent mechanisms". Carefully-commented Python notebooks that reproduce all our experiments are available online at http://vision.caltech.edu/~kchalupk/code.html.
Unsupervised Discovery of El Nino Using Causal Feature Learning on Microlevel Climate Data
May 30, 2016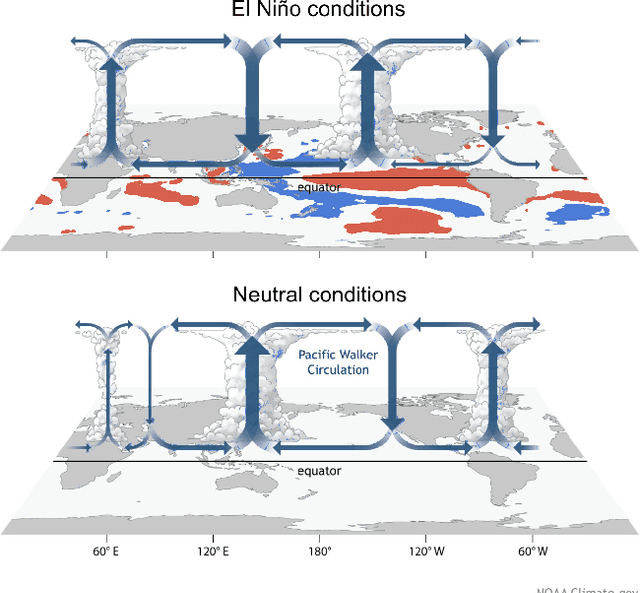
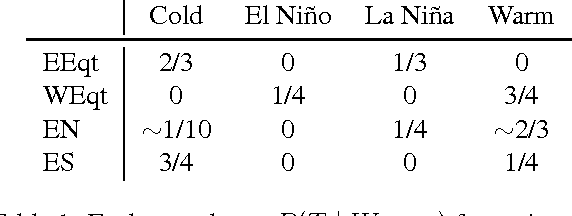
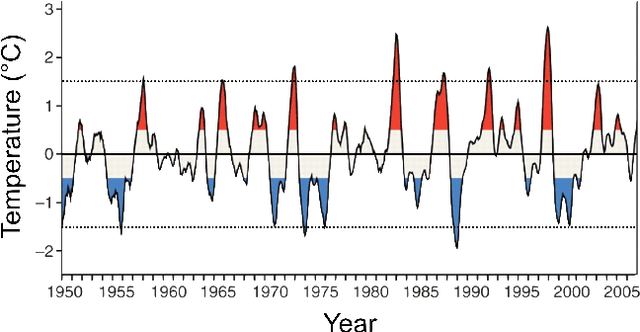
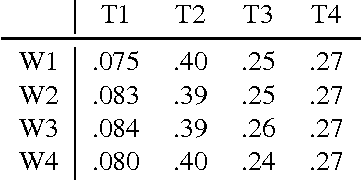
We show that the climate phenomena of El Nino and La Nina arise naturally as states of macro-variables when our recent causal feature learning framework (Chalupka 2015, Chalupka 2016) is applied to micro-level measures of zonal wind (ZW) and sea surface temperatures (SST) taken over the equatorial band of the Pacific Ocean. The method identifies these unusual climate states on the basis of the relation between ZW and SST patterns without any input about past occurrences of El Nino or La Nina. The simpler alternatives of (i) clustering the SST fields while disregarding their relationship with ZW patterns, or (ii) clustering the joint ZW-SST patterns, do not discover El Nino. We discuss the degree to which our method supports a causal interpretation and use a low-dimensional toy example to explain its success over other clustering approaches. Finally, we propose a new robust and scalable alternative to our original algorithm (Chalupka 2016), which circumvents the need for high-dimensional density learning.
Multi-Level Cause-Effect Systems
Dec 25, 2015



We present a domain-general account of causation that applies to settings in which macro-level causal relations between two systems are of interest, but the relevant causal features are poorly understood and have to be aggregated from vast arrays of micro-measurements. Our approach generalizes that of Chalupka et al. (2015) to the setting in which the macro-level effect is not specified. We formalize the connection between micro- and macro-variables in such situations and provide a coherent framework describing causal relations at multiple levels of analysis. We present an algorithm that discovers macro-variable causes and effects from micro-level measurements obtained from an experiment. We further show how to design experiments to discover macro-variables from observational micro-variable data. Finally, we show that under specific conditions, one can identify multiple levels of causal structure. Throughout the article, we use a simulated neuroscience multi-unit recording experiment to illustrate the ideas and the algorithms.
Generalized Regressive Motion: a Visual Cue to Collision
Oct 26, 2015
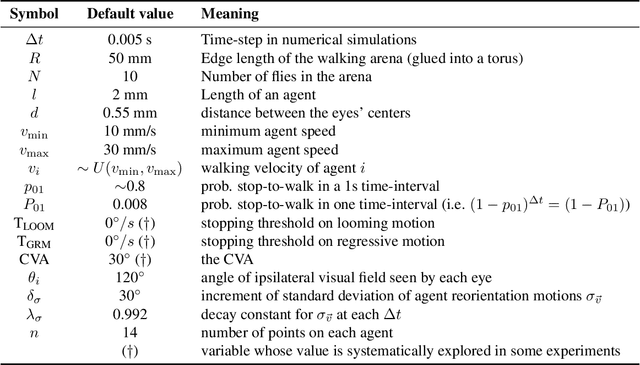


Brains and sensory systems evolved to guide motion. Central to this task is controlling the approach to stationary obstacles and detecting moving organisms. Looming has been proposed as the main monocular visual cue for detecting the approach of other animals and avoiding collisions with stationary obstacles. Elegant neural mechanisms for looming detection have been found in the brain of insects and vertebrates. However, looming has not been analyzed in the context of collisions between two moving animals. We propose an alternative strategy, Generalized Regressive Motion (GRM), which is consistent with recently observed behavior in fruit flies. Geometric analysis proves that GRM is a reliable cue to collision among conspecifics, whereas agent-based modeling suggests that GRM is a better cue than looming as a means to detect approach, prevent collisions and maintain mobility.
Visual Causal Feature Learning
Jun 04, 2015

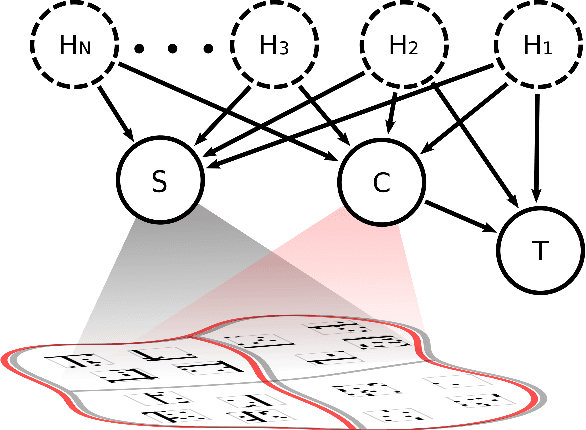
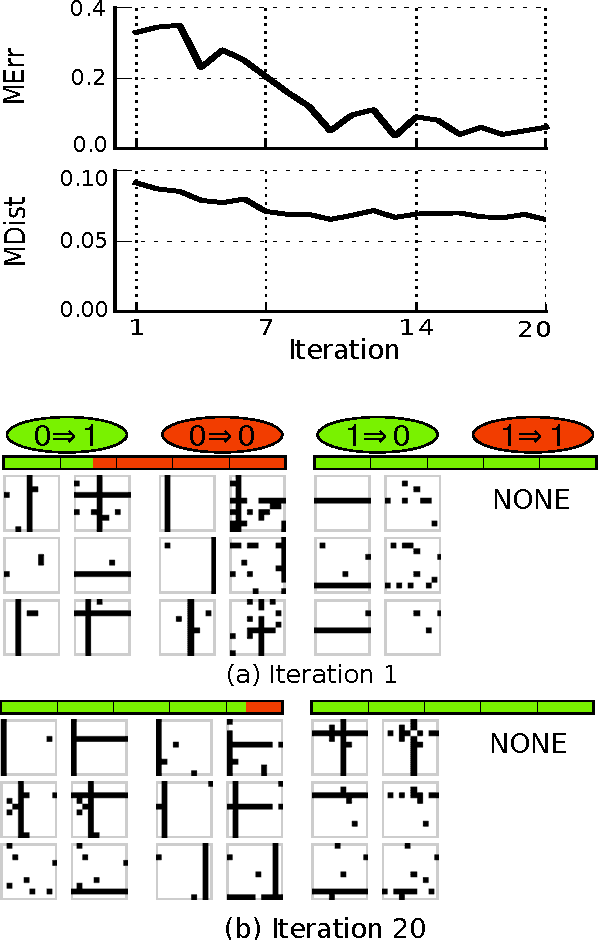
We provide a rigorous definition of the visual cause of a behavior that is broadly applicable to the visually driven behavior in humans, animals, neurons, robots and other perceiving systems. Our framework generalizes standard accounts of causal learning to settings in which the causal variables need to be constructed from micro-variables. We prove the Causal Coarsening Theorem, which allows us to gain causal knowledge from observational data with minimal experimental effort. The theorem provides a connection to standard inference techniques in machine learning that identify features of an image that correlate with, but may not cause, the target behavior. Finally, we propose an active learning scheme to learn a manipulator function that performs optimal manipulations on the image to automatically identify the visual cause of a target behavior. We illustrate our inference and learning algorithms in experiments based on both synthetic and real data.
A Framework for Evaluating Approximation Methods for Gaussian Process Regression
Nov 05, 2012
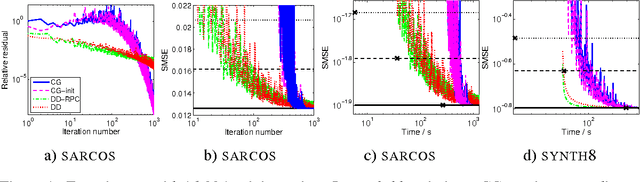

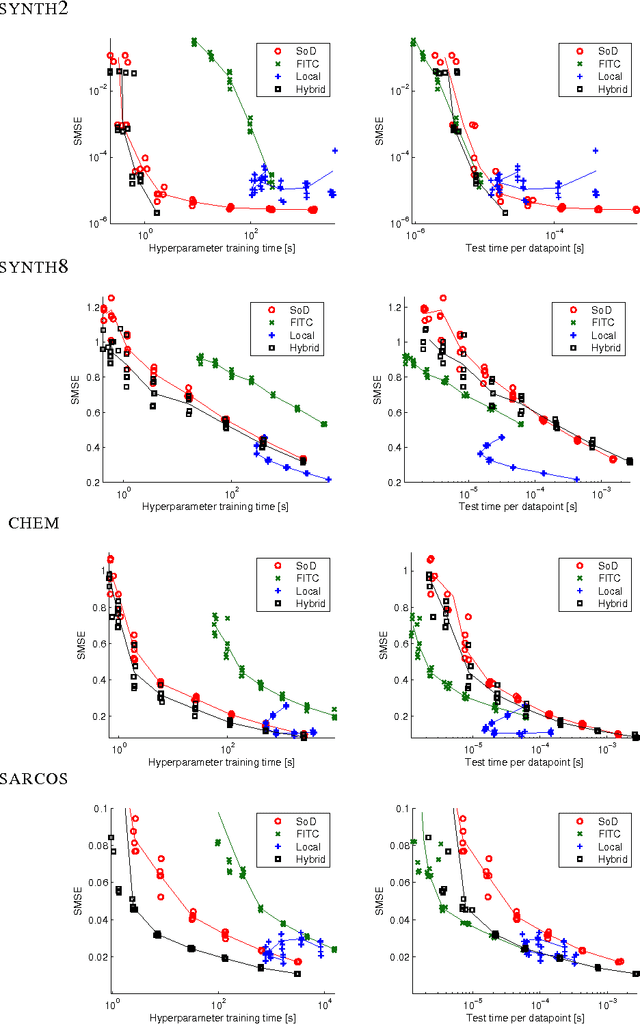
Gaussian process (GP) predictors are an important component of many Bayesian approaches to machine learning. However, even a straightforward implementation of Gaussian process regression (GPR) requires O(n^2) space and O(n^3) time for a dataset of n examples. Several approximation methods have been proposed, but there is a lack of understanding of the relative merits of the different approximations, and in what situations they are most useful. We recommend assessing the quality of the predictions obtained as a function of the compute time taken, and comparing to standard baselines (e.g., Subset of Data and FITC). We empirically investigate four different approximation algorithms on four different prediction problems, and make our code available to encourage future comparisons.