 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing Foveal Fixations Using Linear Retinal Transformations and Bayesian Experimental Design
May 02, 2025Humans (and many vertebrates) face the problem of fusing together multiple fixations of a scene in order to obtain a representation of the whole, where each fixation uses a high-resolution fovea and decreasing resolution in the periphery. In this paper we explicitly represent the retinal transformation of a fixation as a linear downsampling of a high-resolution latent image of the scene, exploiting the known geometry. This linear transformation allows us to carry out exact inference for the latent variables in factor analysis (FA) and mixtures of FA models of the scene. Further, this allows us to formulate and solve the choice of "where to look next" as a Bayesian experimental design problem using the Expected Information Gain criterion. Experiments on the Frey faces and MNIST datasets demonstrate the effectiveness of our models.
Naive Bayes Classifiers and One-hot Encoding of Categorical Variables
Apr 28, 2024This paper investigates the consequences of encoding a $K$-valued categorical variable incorrectly as $K$ bits via one-hot encoding, when using a Na\"{\i}ve Bayes classifier. This gives rise to a product-of-Bernoullis (PoB) assumption, rather than the correct categorical Na\"{\i}ve Bayes classifier. The differences between the two classifiers are analysed mathematically and experimentally. In our experiments using probability vectors drawn from a Dirichlet distribution, the two classifiers are found to agree on the maximum a posteriori class label for most cases, although the posterior probabilities are usually greater for the PoB case.
The Future of Fundamental Science Led by Generative Closed-Loop Artificial Intelligence
Jul 09, 2023



Recent advances in machine learning and AI, including Generative AI and LLMs, are disrupting technological innovation, product development, and society as a whole. AI's contribution to technology can come from multiple approaches that require access to large training data sets and clear performance evaluation criteria, ranging from pattern recognition and classification to generative models. Yet, AI has contributed less to fundamental science in part because large data sets of high-quality data for scientific practice and model discovery are more difficult to access. Generative AI, in general, and Large Language Models in particular, may represent an opportunity to augment and accelerate the scientific discovery of fundamental deep science with quantitative models. Here we explore and investigate aspects of an AI-driven, automated, closed-loop approach to scientific discovery, including self-driven hypothesis generation and open-ended autonomous exploration of the hypothesis space. Integrating AI-driven automation into the practice of science would mitigate current problems, including the replication of findings, systematic production of data, and ultimately democratisation of the scientific process. Realising these possibilities requires a vision for augmented AI coupled with a diversity of AI approaches able to deal with fundamental aspects of causality analysis and model discovery while enabling unbiased search across the space of putative explanations. These advances hold the promise to unleash AI's potential for searching and discovering the fundamental structure of our world beyond what human scientists have been able to achieve. Such a vision would push the boundaries of new fundamental science rather than automatize current workflows and instead open doors for technological innovation to tackle some of the greatest challenges facing humanity today.
Of Mice and Mates: Automated Classification and Modelling of Mouse Behaviour in Groups using a Single Model across Cages
Jun 05, 2023Behavioural experiments often happen in specialised arenas, but this may confound the analysis. To address this issue, we provide tools to study mice in the homecage environment, equipping biologists with the possibility to capture the temporal aspect of the individual's behaviour and model the interaction and interdependence between cage-mates with minimal human intervention. We develop the Activity Labelling Module (ALM) to automatically classify mouse behaviour from video, and a novel Group Behaviour Model (GBM) for summarising their joint behaviour across cages, using a permutation matrix to match the mouse identities in each cage to the model. We also release two datasets, ABODe for training behaviour classifiers and IMADGE for modelling behaviour.
Structured Generative Models for Scene Understanding
Feb 07, 2023This position paper argues for the use of \emph{structured generative models} (SGMs) for scene understanding. This requires the reconstruction of a 3D scene from an input image, whereby the contents of the image are causally explained in terms of models of instantiated objects, each with their own type, shape, appearance and pose, along with global variables like scene lighting and camera parameters. This approach also requires scene models which account for the co-occurrences and inter-relationships of objects in a scene. The SGM approach has the merits that it is compositional and generative, which lead to interpretability. To pursue the SGM agenda, we need models for objects and scenes, and approaches to carry out inference. We first review models for objects, which include ``things'' (object categories that have a well defined shape), and ``stuff'' (categories which have amorphous spatial extent). We then move on to review \emph{scene models} which describe the inter-relationships of objects. Perhaps the most challenging problem for SGMs is \emph{inference} of the objects, lighting and camera parameters, and scene inter-relationships from input consisting of a single or multiple images. We conclude with a discussion of issues that need addressing to advance the SGM agenda.
Multi-Task Dynamical Systems
Oct 08, 2022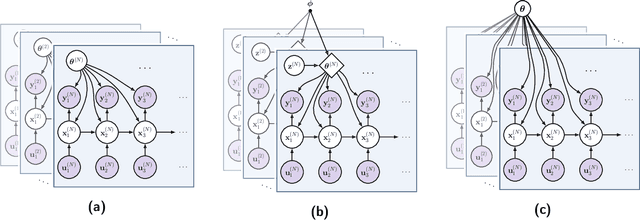
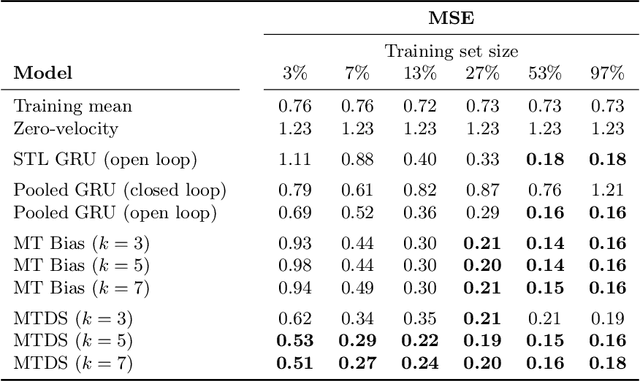
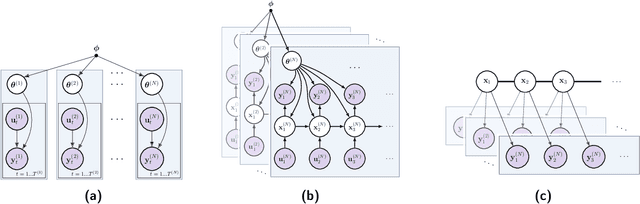
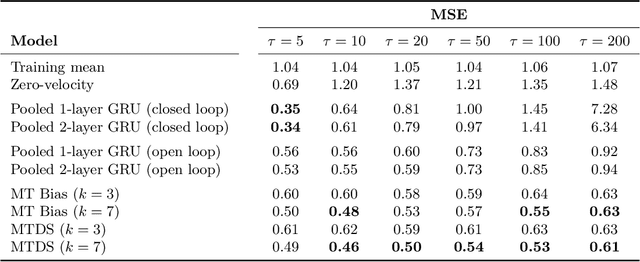
Time series datasets are often composed of a variety of sequences from the same domain, but from different entities, such as individuals, products, or organizations. We are interested in how time series models can be specialized to individual sequences (capturing the specific characteristics) while still retaining statistical power by sharing commonalities across the sequences. This paper describes the multi-task dynamical system (MTDS); a general methodology for extending multi-task learning (MTL) to time series models. Our approach endows dynamical systems with a set of hierarchical latent variables which can modulate all model parameters. To our knowledge, this is a novel development of MTL, and applies to time series both with and without control inputs. We apply the MTDS to motion-capture data of people walking in various styles using a multi-task recurrent neural network (RNN), and to patient drug-response data using a multi-task pharmacodynamic model.
* 52 pages, 17 figures
Inference and Learning for Generative Capsule Models
Sep 07, 2022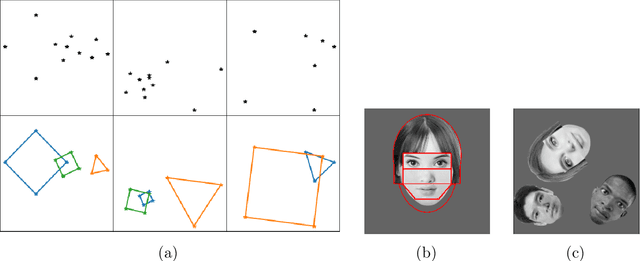
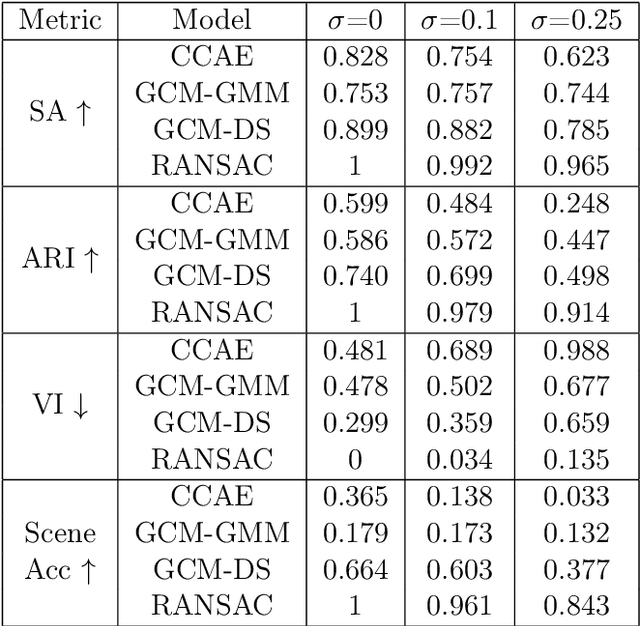

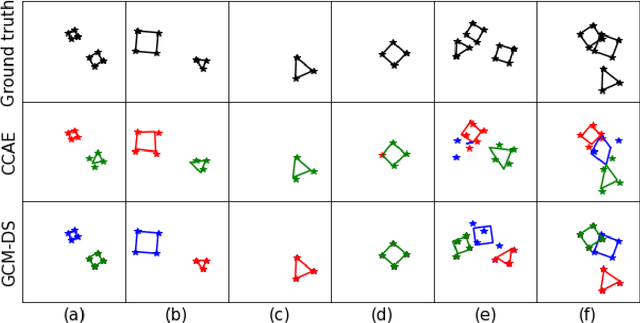
Capsule networks (see e.g. Hinton et al., 2018) aim to encode knowledge of and reason about the relationship between an object and its parts. In this paper we specify a generative model for such data, and derive a variational algorithm for inferring the transformation of each model object in a scene, and the assignments of observed parts to the objects. We derive a learning algorithm for the object models, based on variational expectation maximization (Jordan et al., 1999). We also study an alternative inference algorithm based on the RANSAC method of Fischler and Bolles (1981). We apply these inference methods to (i) data generated from multiple geometric objects like squares and triangles ("constellations"), and (ii) data from a parts-based model of faces. Recent work by Kosiorek et al. (2019) has used amortized inference via stacked capsule autoencoders (SCAEs) to tackle this problem -- our results show that we significantly outperform them where we can make comparisons (on the constellations data).
On Suspicious Coincidences and Pointwise Mutual Information
Mar 15, 2022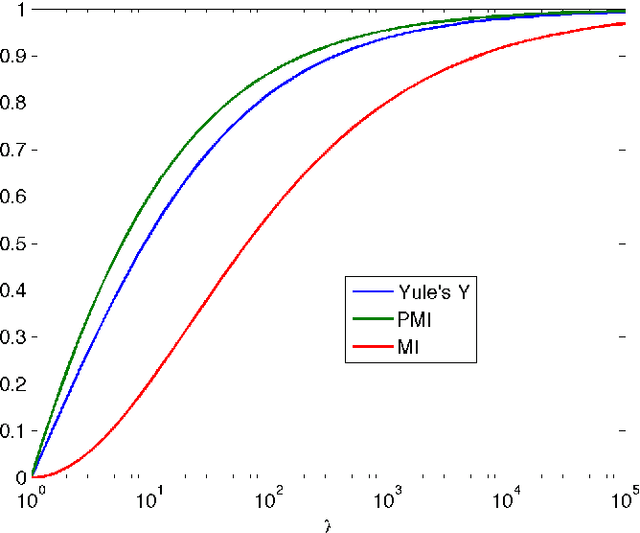
Barlow (1985) hypothesized that the co-occurrence of two events $A$ and $B$ is "suspicious" if $P(A,B) \gg P(A) P(B)$. We first review classical measures of association for $2 \times 2$ contingency tables, including Yule's $Y$ (Yule, 1912), which depends only on the odds ratio $\lambda$, and is independent of the marginal probabilities of the table. We then discuss the mutual information (MI) and pointwise mutual information (PMI), which depend on the ratio $P(A,B)/P(A)P(B)$, as measures of association. We show that, once the effect of the marginals is removed, MI and PMI behave similarly to $Y$ as functions of $\lambda$. The pointwise mutual information is used extensively in some research communities for flagging suspicious coincidences, but it is important to bear in mind the sensitivity of the PMI to the marginals, with increased scores for sparser events.
Align-Deform-Subtract: An Interventional Framework for Explaining Object Differences
Mar 09, 2022



Given two object images, how can we explain their differences in terms of the underlying object properties? To address this question, we propose Align-Deform-Subtract (ADS) -- an interventional framework for explaining object differences. By leveraging semantic alignments in image-space as counterfactual interventions on the underlying object properties, ADS iteratively quantifies and removes differences in object properties. The result is a set of "disentangled" error measures which explain object differences in terms of their underlying properties. Experiments on real and synthetic data illustrate the efficacy of the framework.
Tracking and Long-Term Identification Using Non-Visual Markers
Dec 20, 2021
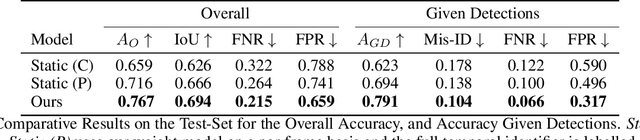
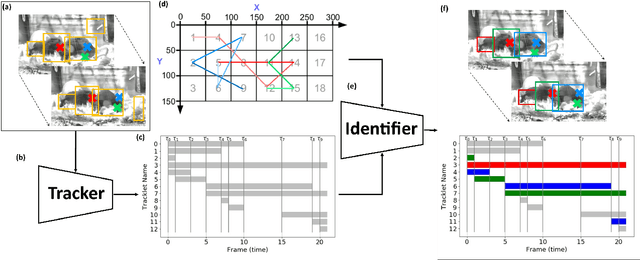

Our objective is to track and identify mice in a cluttered home-cage environment, as a precursor to automated behaviour recognition for biological research. This is a very challenging problem due to (i) the lack of distinguishing visual features for each mouse, and (ii) the close confines of the scene with constant occlusion, making standard visual tracking approaches unusable. However, a coarse estimate of each mouse's location is available from a unique RFID implant, so there is the potential to optimally combine information from (weak) tracking with coarse information on identity. To achieve our objective, we make the following key contributions: (a) the formulation of the identification problem as an assignment problem (solved using Integer Linear Programming), and (b) a novel probabilistic model of the affinity between tracklets and RFID data. The latter is a crucial part of the model, as it provides a principled probabilistic treatment of object detections given coarse localisation. Our approach achieves 77% accuracy on this identification problem, and is able to reject spurious detections when the animals are hidden.