 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOf Mice and Mates: Automated Classification and Modelling of Mouse Behaviour in Groups using a Single Model across Cages
Jun 05, 2023Behavioural experiments often happen in specialised arenas, but this may confound the analysis. To address this issue, we provide tools to study mice in the homecage environment, equipping biologists with the possibility to capture the temporal aspect of the individual's behaviour and model the interaction and interdependence between cage-mates with minimal human intervention. We develop the Activity Labelling Module (ALM) to automatically classify mouse behaviour from video, and a novel Group Behaviour Model (GBM) for summarising their joint behaviour across cages, using a permutation matrix to match the mouse identities in each cage to the model. We also release two datasets, ABODe for training behaviour classifiers and IMADGE for modelling behaviour.
Tracking and Long-Term Identification Using Non-Visual Markers
Dec 20, 2021
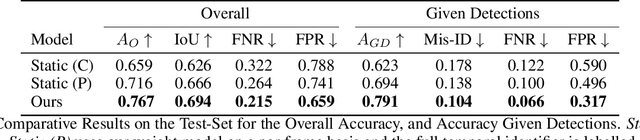
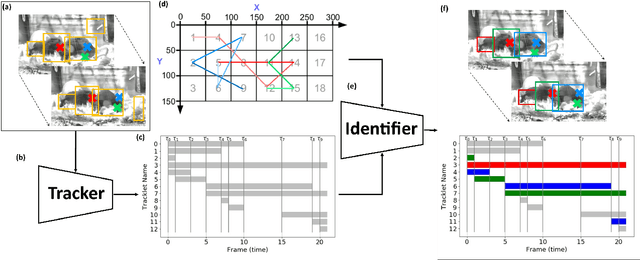

Our objective is to track and identify mice in a cluttered home-cage environment, as a precursor to automated behaviour recognition for biological research. This is a very challenging problem due to (i) the lack of distinguishing visual features for each mouse, and (ii) the close confines of the scene with constant occlusion, making standard visual tracking approaches unusable. However, a coarse estimate of each mouse's location is available from a unique RFID implant, so there is the potential to optimally combine information from (weak) tracking with coarse information on identity. To achieve our objective, we make the following key contributions: (a) the formulation of the identification problem as an assignment problem (solved using Integer Linear Programming), and (b) a novel probabilistic model of the affinity between tracklets and RFID data. The latter is a crucial part of the model, as it provides a principled probabilistic treatment of object detections given coarse localisation. Our approach achieves 77% accuracy on this identification problem, and is able to reject spurious detections when the animals are hidden.
The Extended Dawid-Skene Model: Fusing Information from Multiple Data Schemas
Jun 04, 2019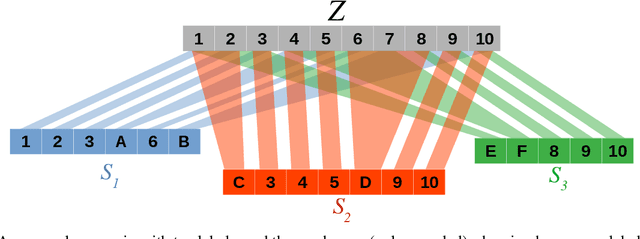

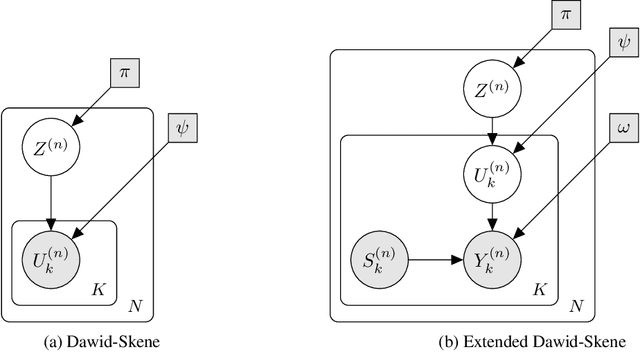

While label fusion from multiple noisy annotations is a well understood concept in data wrangling (tackled for example by the Dawid-Skene (DS) model), we consider the extended problem of carrying out learning when the labels themselves are not consistently annotated with the same schema. We show that even if annotators use disparate, albeit related, label-sets, we can still draw inferences for the underlying full label-set. We propose the Inter-Schema AdapteR (ISAR) to translate the fully-specified label-set to the one used by each annotator, enabling learning under such heterogeneous schemas, without the need to re-annotate the data. We apply our method to a mouse behavioural dataset, achieving significant gains (compared with DS) in out-of-sample log-likelihood (-3.40 to -2.39) and F1-score (0.785 to 0.864).