 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuxley-Gödel Machine: Human-Level Coding Agent Development by an Approximation of the Optimal Self-Improving Machine
Oct 24, 2025Recent studies operationalize self-improvement through coding agents that edit their own codebases. They grow a tree of self-modifications through expansion strategies that favor higher software engineering benchmark performance, assuming that this implies more promising subsequent self-modifications. However, we identify a mismatch between the agent's self-improvement potential (metaproductivity) and its coding benchmark performance, namely the Metaproductivity-Performance Mismatch. Inspired by Huxley's concept of clade, we propose a metric ($\mathrm{CMP}$) that aggregates the benchmark performances of the descendants of an agent as an indicator of its potential for self-improvement. We show that, in our self-improving coding agent development setting, access to the true $\mathrm{CMP}$ is sufficient to simulate how the G\"odel Machine would behave under certain assumptions. We introduce the Huxley-G\"odel Machine (HGM), which, by estimating $\mathrm{CMP}$ and using it as guidance, searches the tree of self-modifications. On SWE-bench Verified and Polyglot, HGM outperforms prior self-improving coding agent development methods while using less wall-clock time. Last but not least, HGM demonstrates strong transfer to other coding datasets and large language models. The agent optimized by HGM on SWE-bench Verified with GPT-5-mini and evaluated on SWE-bench Lite with GPT-5 achieves human-level performance, matching the best officially checked results of human-engineered coding agents. Our code is available at https://github.com/metauto-ai/HGM.
FACTS: A Factored State-Space Framework For World Modelling
Oct 28, 2024



World modelling is essential for understanding and predicting the dynamics of complex systems by learning both spatial and temporal dependencies. However, current frameworks, such as Transformers and selective state-space models like Mambas, exhibit limitations in efficiently encoding spatial and temporal structures, particularly in scenarios requiring long-term high-dimensional sequence modelling. To address these issues, we propose a novel recurrent framework, the \textbf{FACT}ored \textbf{S}tate-space (\textbf{FACTS}) model, for spatial-temporal world modelling. The FACTS framework constructs a graph-structured memory with a routing mechanism that learns permutable memory representations, ensuring invariance to input permutations while adapting through selective state-space propagation. Furthermore, FACTS supports parallel computation of high-dimensional sequences. We empirically evaluate FACTS across diverse tasks, including multivariate time series forecasting and object-centric world modelling, demonstrating that it consistently outperforms or matches specialised state-of-the-art models, despite its general-purpose world modelling design.
Align-Deform-Subtract: An Interventional Framework for Explaining Object Differences
Mar 09, 2022



Given two object images, how can we explain their differences in terms of the underlying object properties? To address this question, we propose Align-Deform-Subtract (ADS) -- an interventional framework for explaining object differences. By leveraging semantic alignments in image-space as counterfactual interventions on the underlying object properties, ADS iteratively quantifies and removes differences in object properties. The result is a set of "disentangled" error measures which explain object differences in terms of their underlying properties. Experiments on real and synthetic data illustrate the efficacy of the framework.
Learning Object-Centric Representations of Multi-Object Scenes from Multiple Views
Nov 13, 2021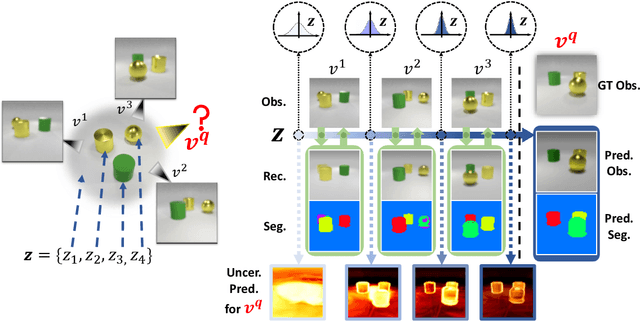
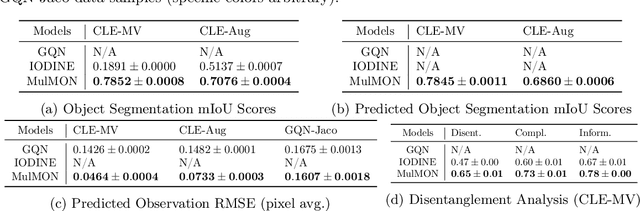

Learning object-centric representations of multi-object scenes is a promising approach towards machine intelligence, facilitating high-level reasoning and control from visual sensory data. However, current approaches for unsupervised object-centric scene representation are incapable of aggregating information from multiple observations of a scene. As a result, these "single-view" methods form their representations of a 3D scene based only on a single 2D observation (view). Naturally, this leads to several inaccuracies, with these methods falling victim to single-view spatial ambiguities. To address this, we propose The Multi-View and Multi-Object Network (MulMON) -- a method for learning accurate, object-centric representations of multi-object scenes by leveraging multiple views. In order to sidestep the main technical difficulty of the multi-object-multi-view scenario -- maintaining object correspondences across views -- MulMON iteratively updates the latent object representations for a scene over multiple views. To ensure that these iterative updates do indeed aggregate spatial information to form a complete 3D scene understanding, MulMON is asked to predict the appearance of the scene from novel viewpoints during training. Through experiments, we show that MulMON better-resolves spatial ambiguities than single-view methods -- learning more accurate and disentangled object representations -- and also achieves new functionality in predicting object segmentations for novel viewpoints.
Object-Centric Representation Learning with Generative Spatial-Temporal Factorization
Nov 09, 2021
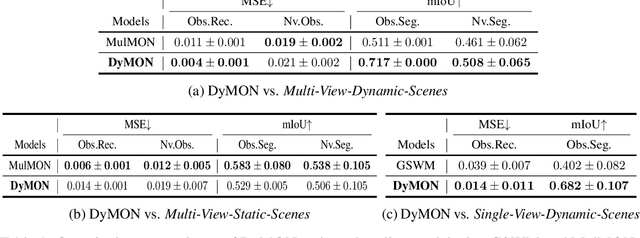
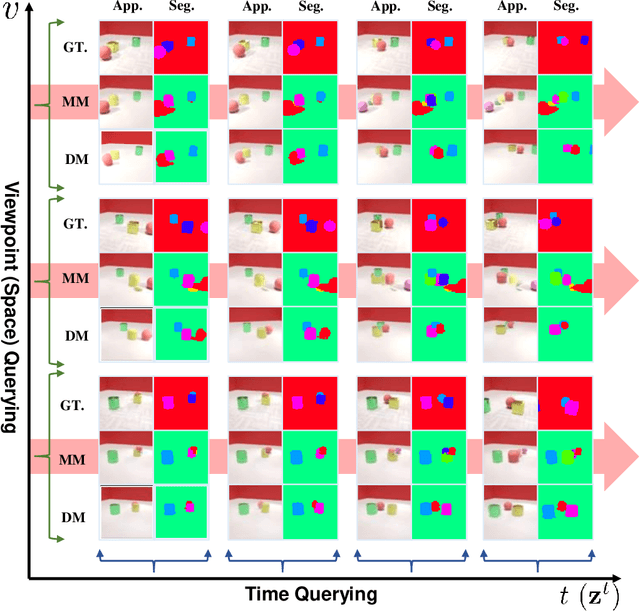

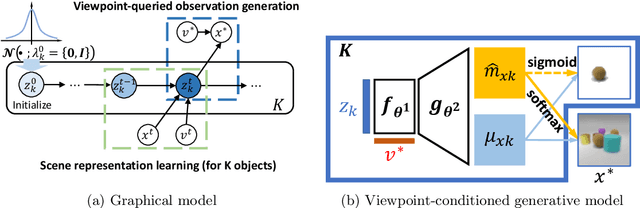
Learning object-centric scene representations is essential for attaining structural understanding and abstraction of complex scenes. Yet, as current approaches for unsupervised object-centric representation learning are built upon either a stationary observer assumption or a static scene assumption, they often: i) suffer single-view spatial ambiguities, or ii) infer incorrectly or inaccurately object representations from dynamic scenes. To address this, we propose Dynamics-aware Multi-Object Network (DyMON), a method that broadens the scope of multi-view object-centric representation learning to dynamic scenes. We train DyMON on multi-view-dynamic-scene data and show that DyMON learns -- without supervision -- to factorize the entangled effects of observer motions and scene object dynamics from a sequence of observations, and constructs scene object spatial representations suitable for rendering at arbitrary times (querying across time) and from arbitrary viewpoints (querying across space). We also show that the factorized scene representations (w.r.t. objects) support querying about a single object by space and time independently.