 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnobtrusive Monitoring of Physical Weakness: A Simulated Approach
Jun 14, 2024Aging and chronic conditions affect older adults' daily lives, making early detection of developing health issues crucial. Weakness, common in many conditions, alters physical movements and daily activities subtly. However, detecting such changes can be challenging due to their subtle and gradual nature. To address this, we employ a non-intrusive camera sensor to monitor individuals' daily sitting and relaxing activities for signs of weakness. We simulate weakness in healthy subjects by having them perform physical exercise and observing the behavioral changes in their daily activities before and after workouts. The proposed system captures fine-grained features related to body motion, inactivity, and environmental context in real-time while prioritizing privacy. A Bayesian Network is used to model the relationships between features, activities, and health conditions. We aim to identify specific features and activities that indicate such changes and determine the most suitable time scale for observing the change. Results show 0.97 accuracy in distinguishing simulated weakness at the daily level. Fine-grained behavioral features, including non-dominant upper body motion speed and scale, and inactivity distribution, along with a 300-second window, are found most effective. However, individual-specific models are recommended as no universal set of optimal features and activities was identified across all participants.
Object-Centric Representation Learning with Generative Spatial-Temporal Factorization
Nov 09, 2021
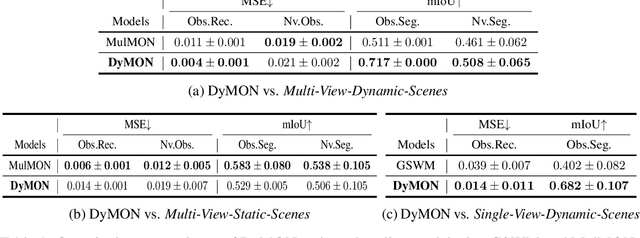
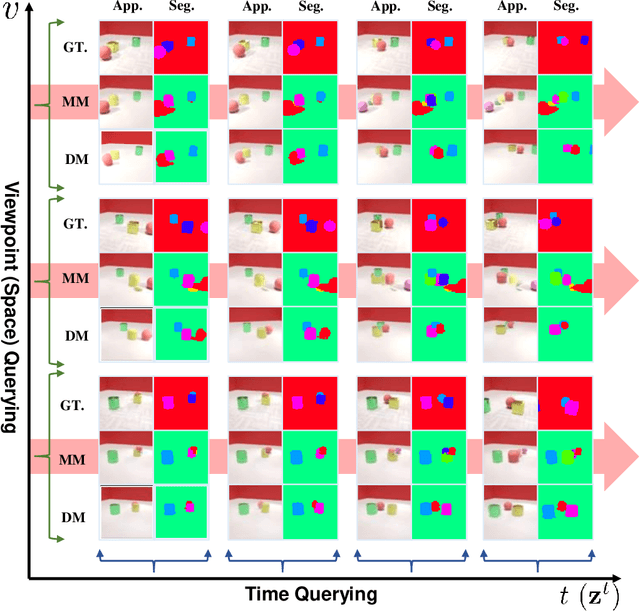

Learning object-centric scene representations is essential for attaining structural understanding and abstraction of complex scenes. Yet, as current approaches for unsupervised object-centric representation learning are built upon either a stationary observer assumption or a static scene assumption, they often: i) suffer single-view spatial ambiguities, or ii) infer incorrectly or inaccurately object representations from dynamic scenes. To address this, we propose Dynamics-aware Multi-Object Network (DyMON), a method that broadens the scope of multi-view object-centric representation learning to dynamic scenes. We train DyMON on multi-view-dynamic-scene data and show that DyMON learns -- without supervision -- to factorize the entangled effects of observer motions and scene object dynamics from a sequence of observations, and constructs scene object spatial representations suitable for rendering at arbitrary times (querying across time) and from arbitrary viewpoints (querying across space). We also show that the factorized scene representations (w.r.t. objects) support querying about a single object by space and time independently.