 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransEDRP: Dual Transformer model with Edge Emdedded for Drug Respond Prediction
Oct 23, 2022GNN-based methods have achieved excellent results as a mainstream task in drug response prediction tasks in recent years. Traditional GNN methods use only the atoms in a drug molecule as nodes to obtain the representation of the molecular graph through node information passing, whereas the method using the transformer can only extract information about the nodes. However, the covalent bonding and chirality of a drug molecule have a great influence on the pharmacological properties of the molecule, and these information are implied in the chemical bonds formed by the edges between the atoms. In addition, CNN methods for modelling cell lines genomics sequences can only perceive local rather than global information about the sequence. In order to solve the above problems, we propose the decoupled dual transformer structure with edge embedded for drug respond prediction (TransEDRP), which is used for the representation of cell line genomics and drug respectively. For the drug branch, we encoded the chemical bond information within the molecule as the embedding of the edge in the molecular graph, extracted the global structural and biochemical information of the drug molecule using graph transformer. For the branch of cell lines genomics, we use the multi-headed attention mechanism to globally represent the genomics sequence. Finally, the drug and genomics branches are fused to predict IC50 values through the transformer layer and the fully connected layer, which two branches are different modalities. Extensive experiments have shown that our method is better than the current mainstream approach in all evaluation indicators.
Object-Centric Representation Learning with Generative Spatial-Temporal Factorization
Nov 09, 2021
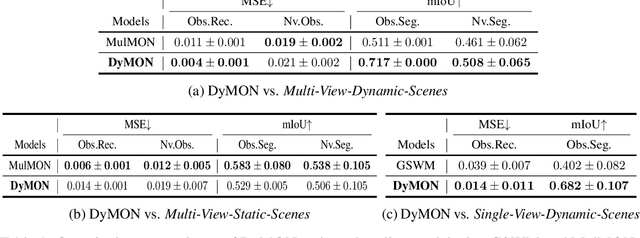
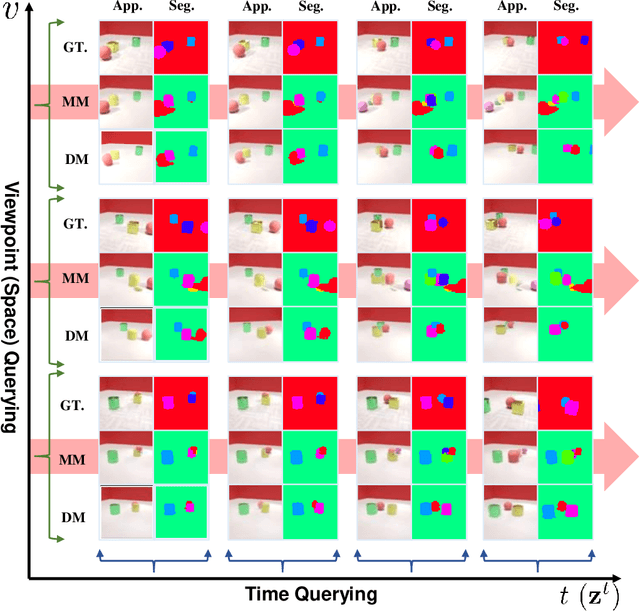

Learning object-centric scene representations is essential for attaining structural understanding and abstraction of complex scenes. Yet, as current approaches for unsupervised object-centric representation learning are built upon either a stationary observer assumption or a static scene assumption, they often: i) suffer single-view spatial ambiguities, or ii) infer incorrectly or inaccurately object representations from dynamic scenes. To address this, we propose Dynamics-aware Multi-Object Network (DyMON), a method that broadens the scope of multi-view object-centric representation learning to dynamic scenes. We train DyMON on multi-view-dynamic-scene data and show that DyMON learns -- without supervision -- to factorize the entangled effects of observer motions and scene object dynamics from a sequence of observations, and constructs scene object spatial representations suitable for rendering at arbitrary times (querying across time) and from arbitrary viewpoints (querying across space). We also show that the factorized scene representations (w.r.t. objects) support querying about a single object by space and time independently.