 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemoBot: Efficient Learning of Bimanual Manipulation with Dexterous Hands From Third-Person Human Videos
Jan 04, 2026This work presents DemoBot, a learning framework that enables a dual-arm, multi-finger robotic system to acquire complex manipulation skills from a single unannotated RGB-D video demonstration. The method extracts structured motion trajectories of both hands and objects from raw video data. These trajectories serve as motion priors for a novel reinforcement learning (RL) pipeline that learns to refine them through contact-rich interactions, thereby eliminating the need to learn from scratch. To address the challenge of learning long-horizon manipulation skills, we introduce: (1) Temporal-segment based RL to enforce temporal alignment of the current state with demonstrations; (2) Success-Gated Reset strategy to balance the refinement of readily acquired skills and the exploration of subsequent task stages; and (3) Event-Driven Reward curriculum with adaptive thresholding to guide the RL learning of high-precision manipulation. The novel video processing and RL framework successfully achieved long-horizon synchronous and asynchronous bimanual assembly tasks, offering a scalable approach for direct skill acquisition from human videos.
Learning Long-Horizon Robot Manipulation Skills via Privileged Action
Feb 21, 2025



Long-horizon contact-rich tasks are challenging to learn with reinforcement learning, due to ineffective exploration of high-dimensional state spaces with sparse rewards. The learning process often gets stuck in local optimum and demands task-specific reward fine-tuning for complex scenarios. In this work, we propose a structured framework that leverages privileged actions with curriculum learning, enabling the policy to efficiently acquire long-horizon skills without relying on extensive reward engineering or reference trajectories. Specifically, we use privileged actions in simulation with a general training procedure that would be infeasible to implement in real-world scenarios. These privileges include relaxed constraints and virtual forces that enhance interaction and exploration with objects. Our results successfully achieve complex multi-stage long-horizon tasks that naturally combine non-prehensile manipulation with grasping to lift objects from non-graspable poses. We demonstrate generality by maintaining a parsimonious reward structure and showing convergence to diverse and robust behaviors across various environments. Additionally, real-world experiments further confirm that the skills acquired using our approach are transferable to real-world environments, exhibiting robust and intricate performance. Our approach outperforms state-of-the-art methods in these tasks, converging to solutions where others fail.
FACTS: A Factored State-Space Framework For World Modelling
Oct 28, 2024



World modelling is essential for understanding and predicting the dynamics of complex systems by learning both spatial and temporal dependencies. However, current frameworks, such as Transformers and selective state-space models like Mambas, exhibit limitations in efficiently encoding spatial and temporal structures, particularly in scenarios requiring long-term high-dimensional sequence modelling. To address these issues, we propose a novel recurrent framework, the \textbf{FACT}ored \textbf{S}tate-space (\textbf{FACTS}) model, for spatial-temporal world modelling. The FACTS framework constructs a graph-structured memory with a routing mechanism that learns permutable memory representations, ensuring invariance to input permutations while adapting through selective state-space propagation. Furthermore, FACTS supports parallel computation of high-dimensional sequences. We empirically evaluate FACTS across diverse tasks, including multivariate time series forecasting and object-centric world modelling, demonstrating that it consistently outperforms or matches specialised state-of-the-art models, despite its general-purpose world modelling design.
Dual Advancement of Representation Learning and Clustering for Sparse and Noisy Images
Sep 03, 2024



Sparse and noisy images (SNIs), like those in spatial gene expression data, pose significant challenges for effective representation learning and clustering, which are essential for thorough data analysis and interpretation. In response to these challenges, we propose Dual Advancement of Representation Learning and Clustering (DARLC), an innovative framework that leverages contrastive learning to enhance the representations derived from masked image modeling. Simultaneously, DARLC integrates cluster assignments in a cohesive, end-to-end approach. This integrated clustering strategy addresses the "class collision problem" inherent in contrastive learning, thus improving the quality of the resulting representations. To generate more plausible positive views for contrastive learning, we employ a graph attention network-based technique that produces denoised images as augmented data. As such, our framework offers a comprehensive approach that improves the learning of representations by enhancing their local perceptibility, distinctiveness, and the understanding of relational semantics. Furthermore, we utilize a Student's t mixture model to achieve more robust and adaptable clustering of SNIs. Extensive experiments, conducted across 12 different types of datasets consisting of SNIs, demonstrate that DARLC surpasses the state-of-the-art methods in both image clustering and generating image representations that accurately capture gene interactions. Code is available at https://github.com/zipging/DARLC.
3D Feature Distillation with Object-Centric Priors
Jun 26, 2024



Grounding natural language to the physical world is a ubiquitous topic with a wide range of applications in computer vision and robotics. Recently, 2D vision-language models such as CLIP have been widely popularized, due to their impressive capabilities for open-vocabulary grounding in 2D images. Recent works aim to elevate 2D CLIP features to 3D via feature distillation, but either learn neural fields that are scene-specific and hence lack generalization, or focus on indoor room scan data that require access to multiple camera views, which is not practical in robot manipulation scenarios. Additionally, related methods typically fuse features at pixel-level and assume that all camera views are equally informative. In this work, we show that this approach leads to sub-optimal 3D features, both in terms of grounding accuracy, as well as segmentation crispness. To alleviate this, we propose a multi-view feature fusion strategy that employs object-centric priors to eliminate uninformative views based on semantic information, and fuse features at object-level via instance segmentation masks. To distill our object-centric 3D features, we generate a large-scale synthetic multi-view dataset of cluttered tabletop scenes, spawning 15k scenes from over 3300 unique object instances, which we make publicly available. We show that our method reconstructs 3D CLIP features with improved grounding capacity and spatial consistency, while doing so from single-view RGB-D, thus departing from the assumption of multiple camera views at test time. Finally, we show that our approach can generalize to novel tabletop domains and be re-purposed for 3D instance segmentation without fine-tuning, and demonstrate its utility for language-guided robotic grasping in clutter
DHP-Mapping: A Dense Panoptic Mapping System with Hierarchical World Representation and Label Optimization Techniques
Mar 25, 2024
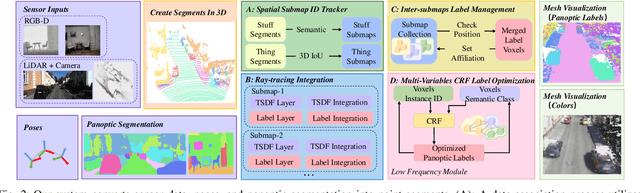
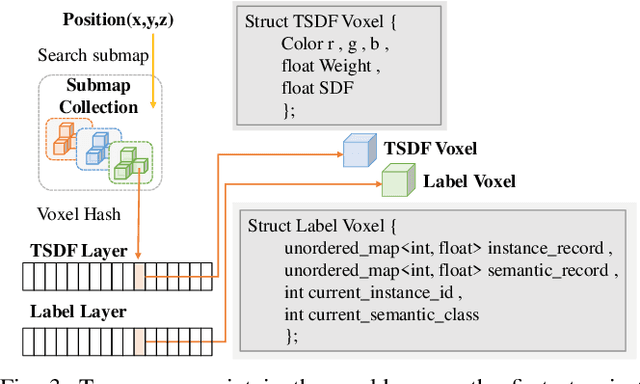
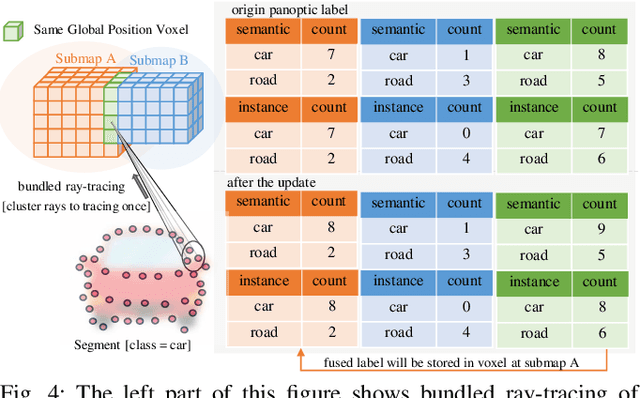
Maps provide robots with crucial environmental knowledge, thereby enabling them to perform interactive tasks effectively. Easily accessing accurate abstract-to-detailed geometric and semantic concepts from maps is crucial for robots to make informed and efficient decisions. To comprehensively model the environment and effectively manage the map data structure, we propose DHP-Mapping, a dense mapping system that utilizes multiple Truncated Signed Distance Field (TSDF) submaps and panoptic labels to hierarchically model the environment. The output map is able to maintain both voxel- and submap-level metric and semantic information. Two modules are presented to enhance the mapping efficiency and label consistency: (1) an inter-submaps label fusion strategy to eliminate duplicate points across submaps and (2) a conditional random field (CRF) based approach to enhance panoptic labels through object label comprehension and contextual information. We conducted experiments with two public datasets including indoor and outdoor scenarios. Our system performs comparably to state-of-the-art (SOTA) methods across geometry and label accuracy evaluation metrics. The experiment results highlight the effectiveness and scalability of our system, as it is capable of constructing precise geometry and maintaining consistent panoptic labels. Our code is publicly available at https://github.com/hutslib/DHP-Mapping.
Language-guided Robot Grasping: CLIP-based Referring Grasp Synthesis in Clutter
Nov 09, 2023
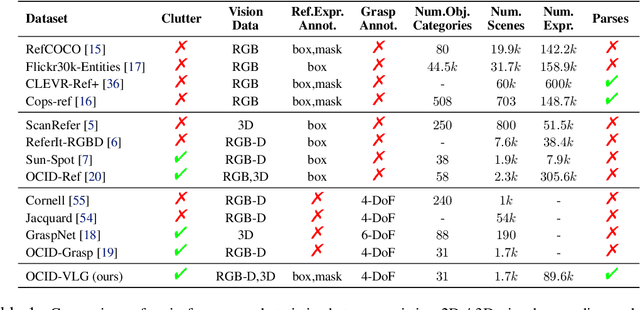
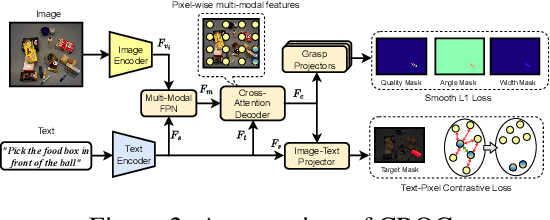
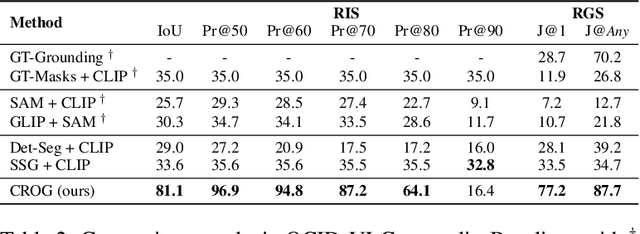
Robots operating in human-centric environments require the integration of visual grounding and grasping capabilities to effectively manipulate objects based on user instructions. This work focuses on the task of referring grasp synthesis, which predicts a grasp pose for an object referred through natural language in cluttered scenes. Existing approaches often employ multi-stage pipelines that first segment the referred object and then propose a suitable grasp, and are evaluated in private datasets or simulators that do not capture the complexity of natural indoor scenes. To address these limitations, we develop a challenging benchmark based on cluttered indoor scenes from OCID dataset, for which we generate referring expressions and connect them with 4-DoF grasp poses. Further, we propose a novel end-to-end model (CROG) that leverages the visual grounding capabilities of CLIP to learn grasp synthesis directly from image-text pairs. Our results show that vanilla integration of CLIP with pretrained models transfers poorly in our challenging benchmark, while CROG achieves significant improvements both in terms of grounding and grasping. Extensive robot experiments in both simulation and hardware demonstrate the effectiveness of our approach in challenging interactive object grasping scenarios that include clutter.
NoteChat: A Dataset of Synthetic Doctor-Patient Conversations Conditioned on Clinical Notes
Oct 24, 2023



The detailed clinical records drafted by doctors after each patient's visit are crucial for medical practitioners and researchers. Automating the creation of these notes with language models can reduce the workload of doctors. However, training such models can be difficult due to the limited public availability of conversations between patients and doctors. In this paper, we introduce NoteChat, a cooperative multi-agent framework leveraging Large Language Models (LLMs) for generating synthetic doctor-patient conversations conditioned on clinical notes. NoteChat consists of Planning, Roleplay, and Polish modules. We provide a comprehensive automatic and human evaluation of NoteChat, comparing it with state-of-the-art models, including OpenAI's ChatGPT and GPT-4. Results demonstrate that NoteChat facilitates high-quality synthetic doctor-patient conversations, underscoring the untapped potential of LLMs in healthcare. This work represents the first instance of multiple LLMs cooperating to complete a doctor-patient conversation conditioned on clinical notes, offering promising avenues for the intersection of AI and healthcare
Learning Fine Pinch-Grasp Skills using Tactile Sensing from Real Demonstration Data
Jul 10, 2023
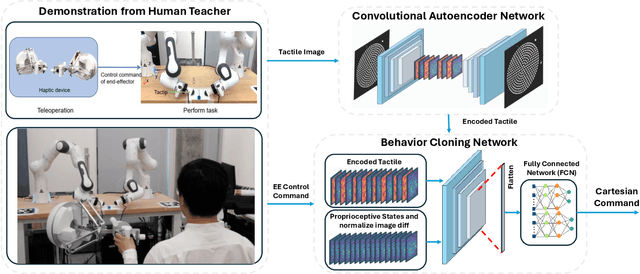


This work develops a data-efficient learning from demonstration framework which exploits the use of rich tactile sensing and achieves fine dexterous bimanual manipulation. Specifically, we formulated a convolutional autoencoder network that can effectively extract and encode high-dimensional tactile information. Further, we developed a behaviour cloning network that can learn human-like sensorimotor skills demonstrated directly on the robot hardware in the task space by fusing both proprioceptive and tactile feedback. Our comparison study with the baseline method revealed the effectiveness of the contact information, which enabled successful extraction and replication of the demonstrated motor skills. Extensive experiments on real dual-arm robots demonstrated the robustness and effectiveness of the fine pinch grasp policy directly learned from one-shot demonstration, including grasping of the same object with different initial poses, generalizing to ten unseen new objects, robust and firm grasping against external pushes, as well as contact-aware and reactive re-grasping in case of dropping objects under very large perturbations. Moreover, the saliency map method is employed to describe the weight distribution across various modalities during pinch grasping. The video is available online at: \href{https://youtu.be/4Pg29bUBKqs}{https://youtu.be/4Pg29bUBKqs}.
IDToolkit: A Toolkit for Benchmarking and Developing Inverse Design Algorithms in Nanophotonics
May 31, 2023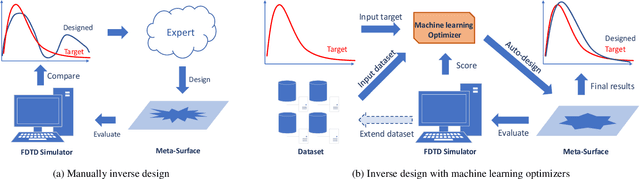

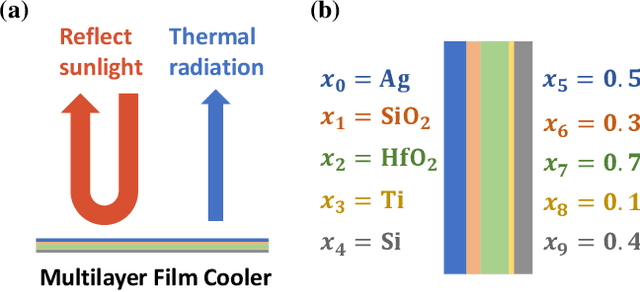
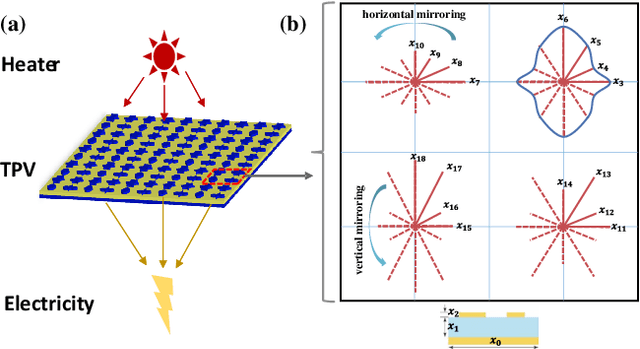
Aiding humans with scientific designs is one of the most exciting of artificial intelligence (AI) and machine learning (ML), due to their potential for the discovery of new drugs, design of new materials and chemical compounds, etc. However, scientific design typically requires complex domain knowledge that is not familiar to AI researchers. Further, scientific studies involve professional skills to perform experiments and evaluations. These obstacles prevent AI researchers from developing specialized methods for scientific designs. To take a step towards easy-to-understand and reproducible research of scientific design, we propose a benchmark for the inverse design of nanophotonic devices, which can be verified computationally and accurately. Specifically, we implemented three different nanophotonic design problems, namely a radiative cooler, a selective emitter for thermophotovoltaics, and structural color filters, all of which are different in design parameter spaces, complexity, and design targets. The benchmark environments are implemented with an open-source simulator. We further implemented 10 different inverse design algorithms and compared them in a reproducible and fair framework. The results revealed the strengths and weaknesses of existing methods, which shed light on several future directions for developing more efficient inverse design algorithms. Our benchmark can also serve as the starting point for more challenging scientific design problems. The code of IDToolkit is available at https://github.com/ThyrixYang/IDToolkit.