 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Long-Horizon Robot Manipulation Skills via Privileged Action
Feb 21, 2025



Long-horizon contact-rich tasks are challenging to learn with reinforcement learning, due to ineffective exploration of high-dimensional state spaces with sparse rewards. The learning process often gets stuck in local optimum and demands task-specific reward fine-tuning for complex scenarios. In this work, we propose a structured framework that leverages privileged actions with curriculum learning, enabling the policy to efficiently acquire long-horizon skills without relying on extensive reward engineering or reference trajectories. Specifically, we use privileged actions in simulation with a general training procedure that would be infeasible to implement in real-world scenarios. These privileges include relaxed constraints and virtual forces that enhance interaction and exploration with objects. Our results successfully achieve complex multi-stage long-horizon tasks that naturally combine non-prehensile manipulation with grasping to lift objects from non-graspable poses. We demonstrate generality by maintaining a parsimonious reward structure and showing convergence to diverse and robust behaviors across various environments. Additionally, real-world experiments further confirm that the skills acquired using our approach are transferable to real-world environments, exhibiting robust and intricate performance. Our approach outperforms state-of-the-art methods in these tasks, converging to solutions where others fail.
Neural Lyapunov and Optimal Control
May 24, 2023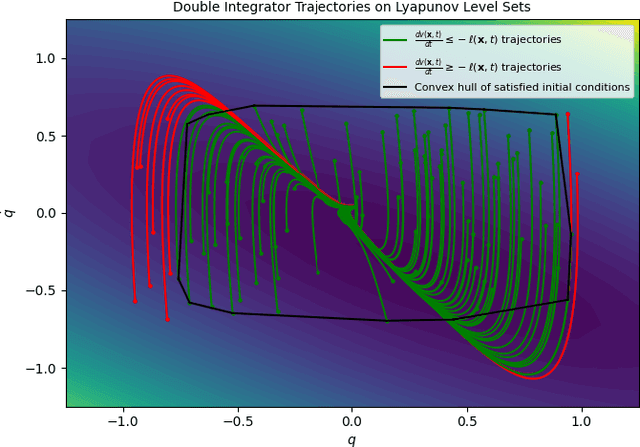
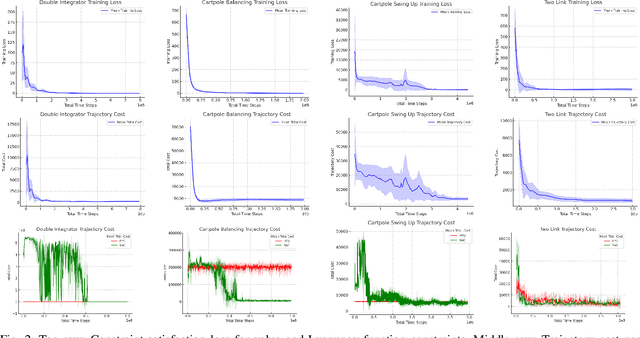
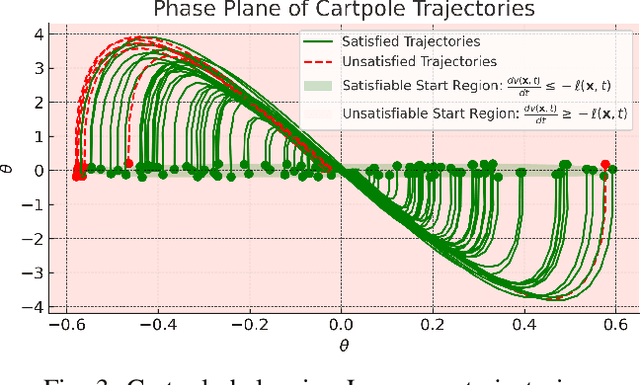

Optimal control (OC) is an effective approach to controlling complex dynamical systems. However, traditional approaches to parameterising and learning controllers in optimal control have been ad-hoc, collecting data and fitting it to neural networks. However, this can lead to learnt controllers ignoring constraints like optimality and time variability. We introduce a unified framework that simultaneously solves control problems while learning corresponding Lyapunov or value functions. Our method formulates OC-like mathematical programs based on the Hamilton-Jacobi-Bellman (HJB) equation. We leverage the HJB optimality constraint and its relaxation to learn time-varying value and Lyapunov functions, implicitly ensuring the inclusion of constraints. We show the effectiveness of our approach on linear and nonlinear control-affine problems. Additionally, we demonstrate significant reductions in planning horizons (up to a factor of 25) when incorporating the learnt functions into Model Predictive Controllers.
Optimal Control via Combined Inference and Numerical Optimization
Sep 23, 2021

Derivative based optimization methods are efficient at solving optimal control problems near local optima. However, their ability to converge halts when derivative information vanishes. The inference approach to optimal control does not have strict requirements on the objective landscape. However, sampling, the primary tool for solving such problems, tends to be much slower in computation time. We propose a new method that combines second order methods with inference. We utilise the Kullback Leibler (KL) control framework to formulate an inference problem that computes the optimal controls from an adaptive distribution approximating the solution of the second order method. Our method allows for combining simple convex and non convex cost functions. This simplifies the process of cost function design and leverages the strengths of both inference and second order optimization. We compare our method to Model Predictive Path Integral (MPPI) and iterative Linear Quadratic Regulator (iLQG), outperforming both in sample efficiency and quality on manipulation and obstacle avoidance tasks.