 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Video Generation by Learning the Underlying Dynamical System with Neural ODE
Mar 09, 2023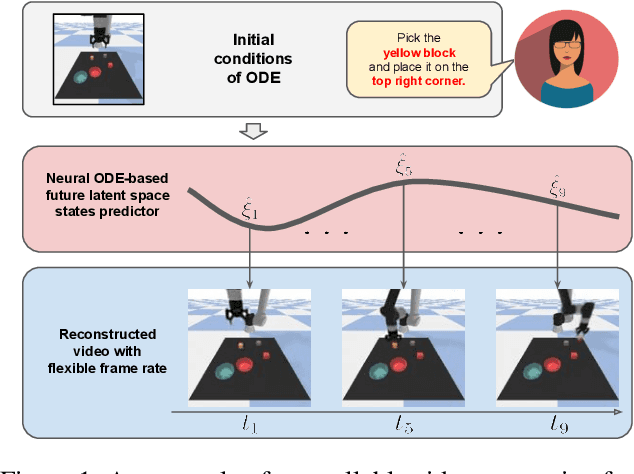
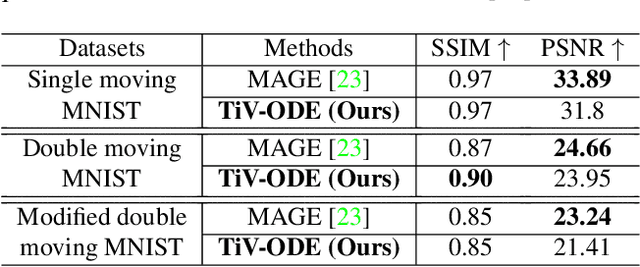
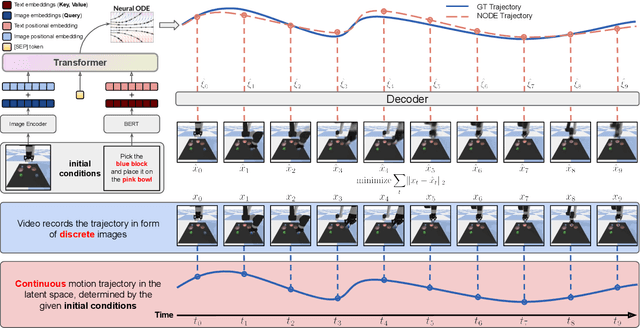
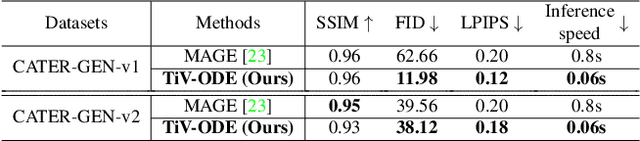
Videos depict the change of complex dynamical systems over time in the form of discrete image sequences. Generating controllable videos by learning the dynamical system is an important yet underexplored topic in the computer vision community. This paper presents a novel framework, TiV-ODE, to generate highly controllable videos from a static image and a text caption. Specifically, our framework leverages the ability of Neural Ordinary Differential Equations~(Neural ODEs) to represent complex dynamical systems as a set of nonlinear ordinary differential equations. The resulting framework is capable of generating videos with both desired dynamics and content. Experiments demonstrate the ability of the proposed method in generating highly controllable and visually consistent videos, and its capability of modeling dynamical systems. Overall, this work is a significant step towards developing advanced controllable video generation models that can handle complex and dynamic scenes.
DUGMA: Dynamic Uncertainty-Based Gaussian Mixture Alignment
Aug 02, 2018


Registering accurately point clouds from a cheap low-resolution sensor is a challenging task. Existing rigid registration methods failed to use the physical 3D uncertainty distribution of each point from a real sensor in the dynamic alignment process mainly because the uncertainty model for a point is static and invariant and it is hard to describe the change of these physical uncertainty models in the registration process. Additionally, the existing Gaussian mixture alignment architecture cannot be efficiently implement these dynamic changes. This paper proposes a simple architecture combining error estimation from sample covariances and dual dynamic global probability alignment using the convolution of uncertainty-based Gaussian Mixture Models (GMM) from point clouds. Firstly, we propose an efficient way to describe the change of each 3D uncertainty model, which represents the structure of the point cloud much better. Unlike the invariant GMM (representing a fixed point cloud) in traditional Gaussian mixture alignment, we use two uncertainty-based GMMs that change and interact with each other in each iteration. In order to have a wider basin of convergence than other local algorithms, we design a more robust energy function by convolving efficiently the two GMMs over the whole 3D space. Tens of thousands of trials have been conducted on hundreds of models from multiple datasets to demonstrate the proposed method's superior performance compared with the current state-of-the-art methods. The new dataset and code is available from https://github.com/Canpu999
Hybrid Multi-camera Visual Servoing to Moving Target
Aug 02, 2018
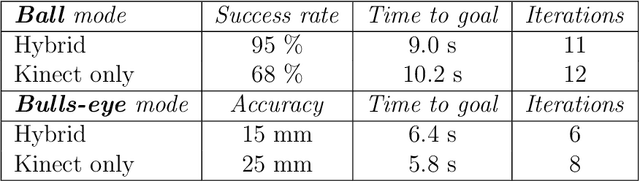
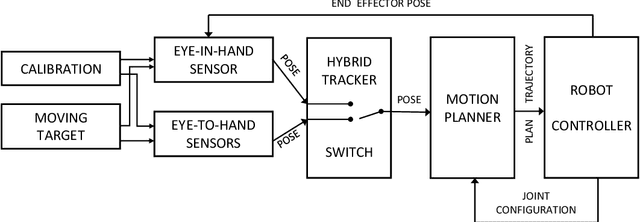
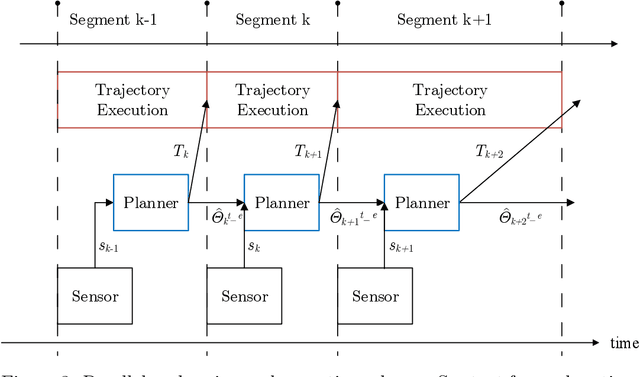
Visual servoing is a well-known task in robotics. However, there are still challenges when multiple visual sources are combined to accurately guide the robot or occlusions appear. In this paper we present a novel visual servoing approach using hybrid multi-camera input data to lead a robot arm accurately to dynamically moving target points in the presence of partial occlusions. The approach uses four RGBD sensors as Eye-to-Hand (EtoH) visual input, and an arm-mounted stereo camera as Eye-in-Hand (EinH). A Master supervisor task selects between using the EtoH or the EinH, depending on the distance between the robot and target. The Master also selects the subset of EtoH cameras that best perceive the target. When the EinH sensor is used, if the target becomes occluded or goes out of the sensor's view-frustum, the Master switches back to the EtoH sensors to re-track the object. Using this adaptive visual input data, the robot is then controlled using an iterative planner that uses position, orientation and joint configuration to estimate the trajectory. Since the target is dynamic, this trajectory is updated every time-step. Experiments show good performance in four different situations: tracking a ball, targeting a bulls-eye, guiding a straw to a mouth and delivering an item to a moving hand. The experiments cover both simple situations such as a ball that is mostly visible from all cameras, and more complex situations such as the mouth which is partially occluded from some of the sensors.
Sdf-GAN: Semi-supervised Depth Fusion with Multi-scale Adversarial Networks
Mar 18, 2018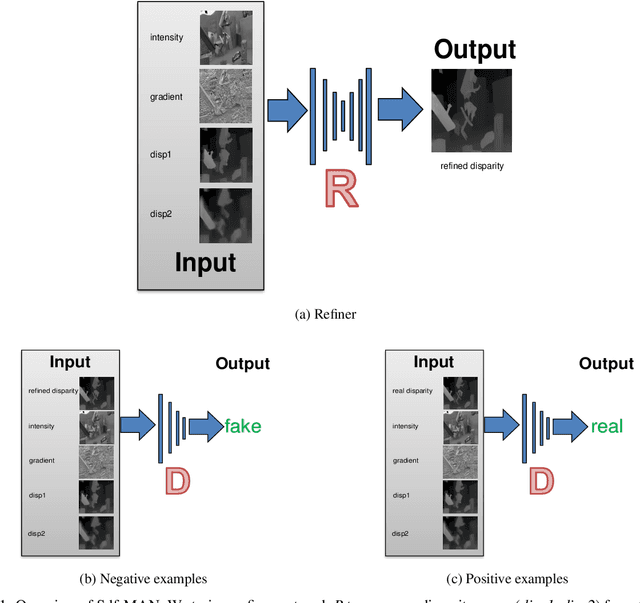
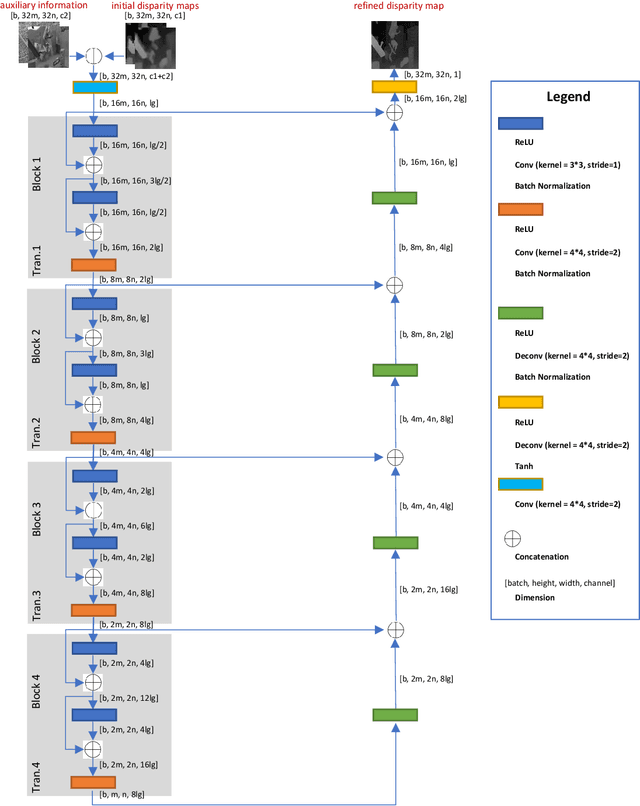
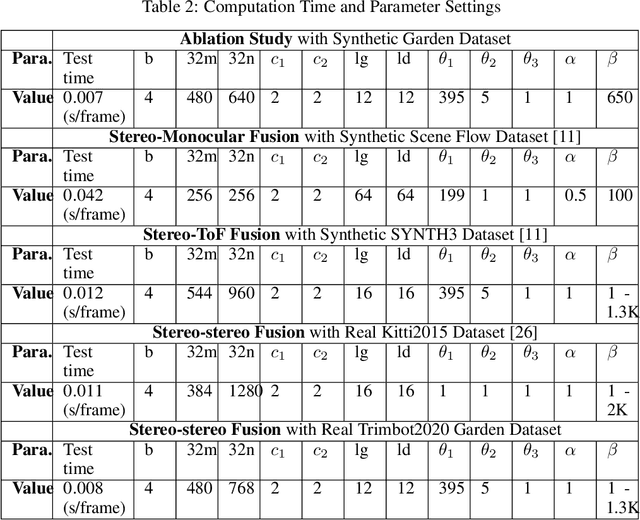
Fusing disparity maps from different algorithms to exploit their complementary advantages is still challenging. Uncertainty estimation and complex disparity relationships between neighboring pixels limit the accuracy and robustness of the existing methods and there is no common method for depth fusion of different kind of data. In this paper, we introduce a method to incorporate supplementary information (intensity, gradient constraints etc.) into a Generative Adversarial Network to better refine each input disparity value. By adopting a multi-scale strategy, the disparity relationship in the fused disparity map is a better estimate of the real distribution. The approach includes a more robust object function to avoid blurry edges, impaints invalid disparity values and requires much fewer ground data to train. The algorithm can be generalized to different kinds of depth fusion. The experiments were conducted through simulation and real data, exploring different fusion opportunities: stereo-monocular fusion from coarse input, stereo-stereo fusion from moderately accurate input, fusion from accurate binocular input and Time of Flight sensor. The experiments show the superiority of the proposed algorithm compared with the most recent algorithms on the public Scene Flow and SYNTH3 datasets. The code is available from https://github.com/Canpu999
Robust Rigid Point Registration based on Convolution of Adaptive Gaussian Mixture Models
Jul 26, 2017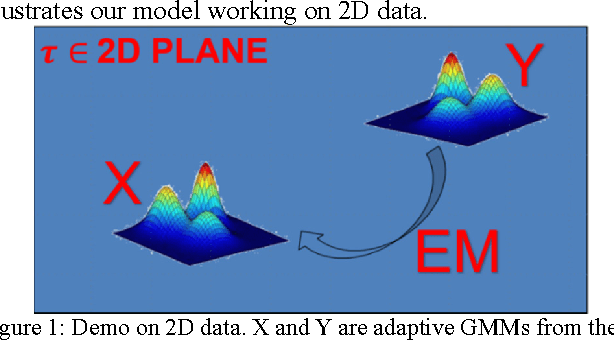
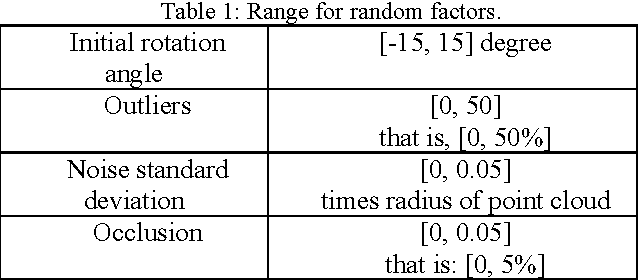

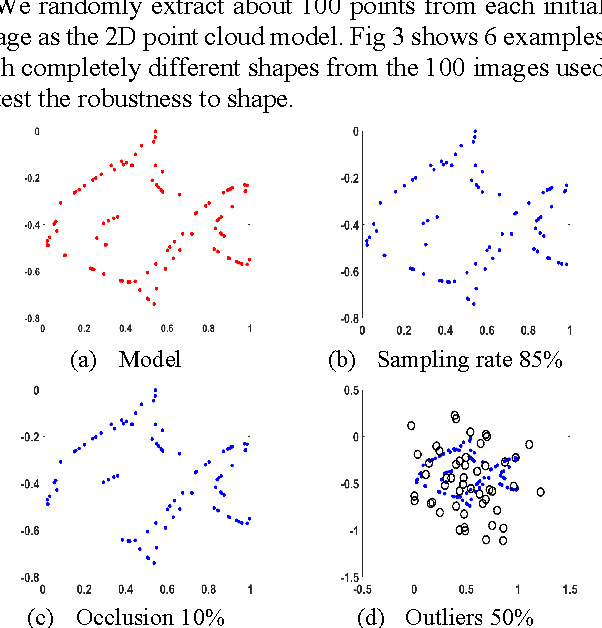
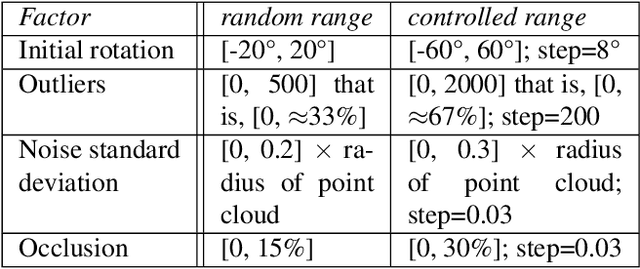
Matching 3D rigid point clouds in complex environments robustly and accurately is still a core technique used in many applications. This paper proposes a new architecture combining error estimation from sample covariances and dual global probability alignment based on the convolution of adaptive Gaussian Mixture Models (GMM) from point clouds. Firstly, a novel adaptive GMM is defined using probability distributions from the corresponding points. Then rigid point cloud alignment is performed by maximizing the global probability from the convolution of dual adaptive GMMs in the whole 2D or 3D space, which can be efficiently optimized and has a large zone of accurate convergence. Thousands of trials have been conducted on 200 models from public 2D and 3D datasets to demonstrate superior robustness and accuracy in complex environments with unpredictable noise, outliers, occlusion, initial rotation, shape and missing points.