 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnSAMFlow: Unsupervised Optical Flow Guided by Segment Anything Model
May 04, 2024



Traditional unsupervised optical flow methods are vulnerable to occlusions and motion boundaries due to lack of object-level information. Therefore, we propose UnSAMFlow, an unsupervised flow network that also leverages object information from the latest foundation model Segment Anything Model (SAM). We first include a self-supervised semantic augmentation module tailored to SAM masks. We also analyze the poor gradient landscapes of traditional smoothness losses and propose a new smoothness definition based on homography instead. A simple yet effective mask feature module has also been added to further aggregate features on the object level. With all these adaptations, our method produces clear optical flow estimation with sharp boundaries around objects, which outperforms state-of-the-art methods on both KITTI and Sintel datasets. Our method also generalizes well across domains and runs very efficiently.
Learning Quadruped Locomotion using Bio-Inspired Neural Networks with Intrinsic Rhythmicity
May 12, 2023
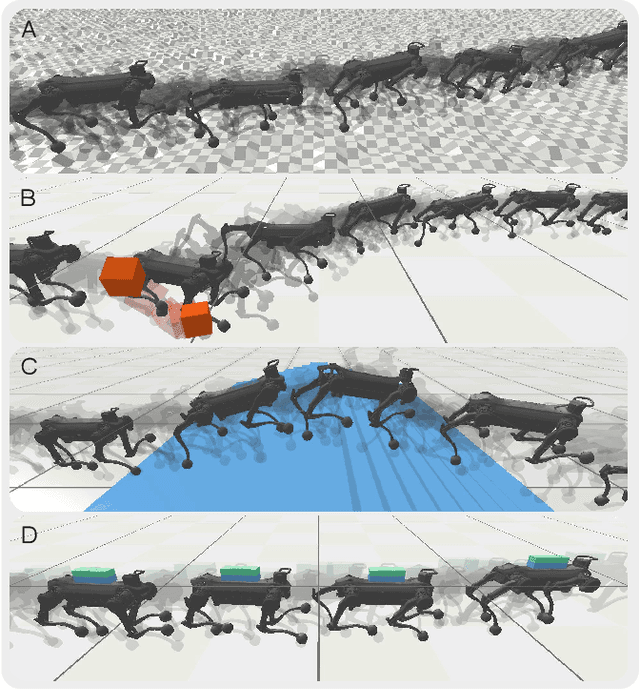
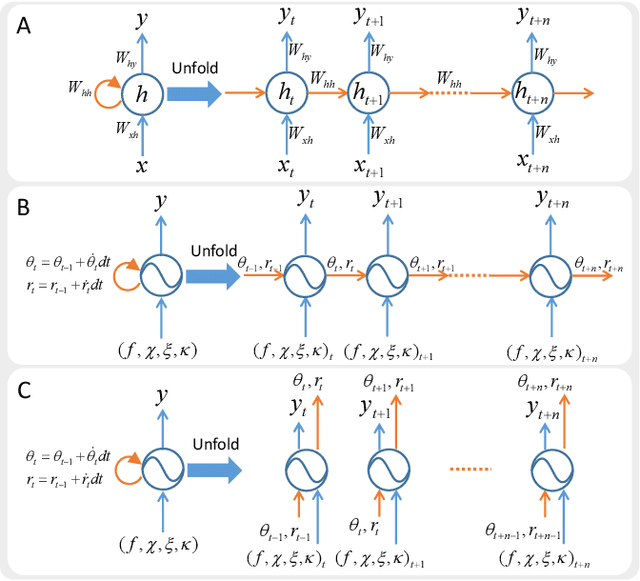
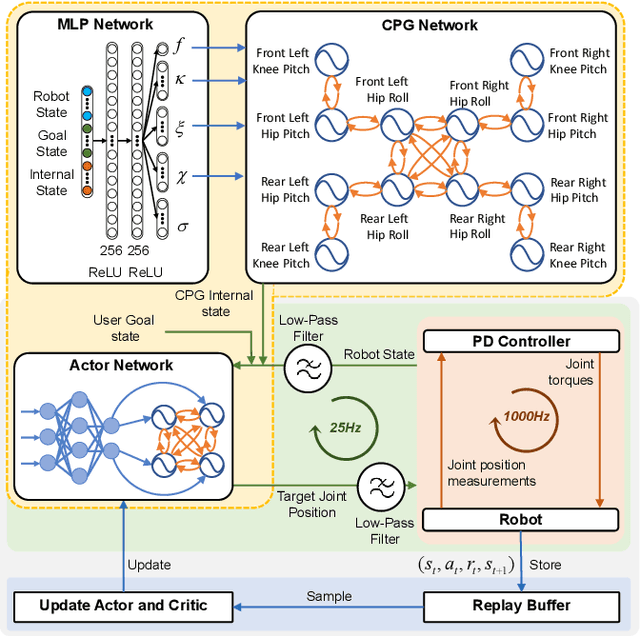
Biological studies reveal that neural circuits located at the spinal cord called central pattern generator (CPG) oscillates and generates rhythmic signals, which are the underlying mechanism responsible for rhythmic locomotion behaviors of animals. Inspired by CPG's capability to naturally generate rhythmic patterns, researchers have attempted to create mathematical models of CPG and utilize them for the locomotion of legged robots. In this paper, we propose a network architecture that incorporates CPGs for rhythmic pattern generation and a multi-layer perceptron (MLP) network for sensory feedback. We also proposed a method that reformulates CPGs into a fully-differentiable stateless network, allowing CPGs and MLP to be jointly trained with gradient-based learning. The results show that our proposed method learned agile and dynamic locomotion policies which are capable of blind traversal over uneven terrain and resist external pushes. Simulation results also show that the learned policies are capable of self-modulating step frequency and step length to adapt to the locomotion velocity.
A Multi-modal Garden Dataset and Hybrid 3D Dense Reconstruction Framework Based on Panoramic Stereo Images for a Trimming Robot
May 10, 2023
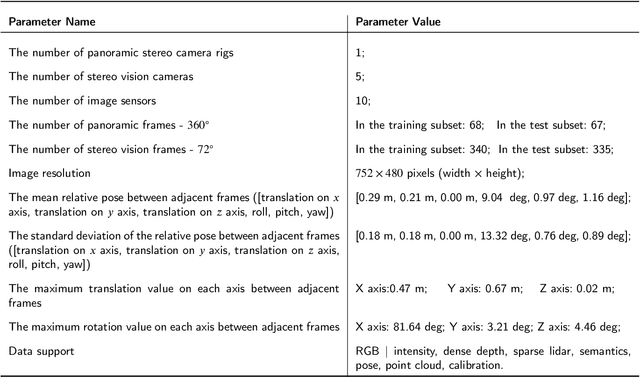
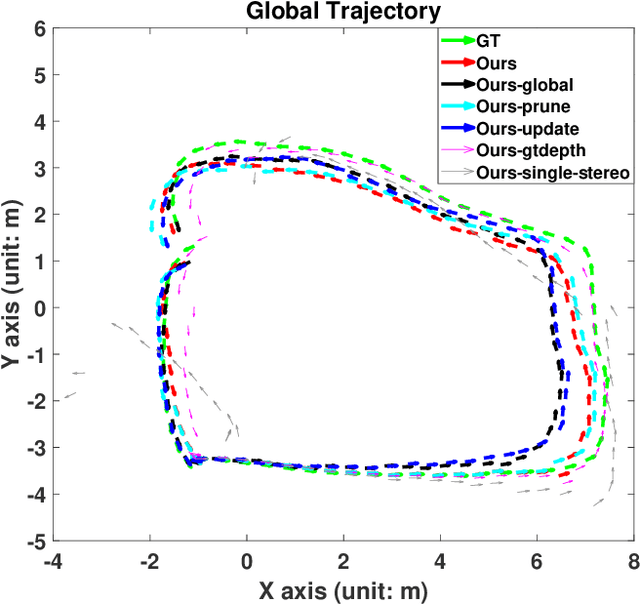
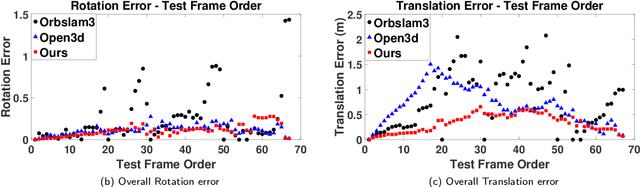
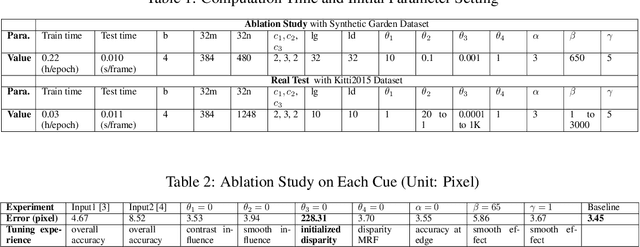
Recovering an outdoor environment's surface mesh is vital for an agricultural robot during task planning and remote visualization. Our proposed solution is based on a newly-designed panoramic stereo camera along with a hybrid novel software framework that consists of three fusion modules. The panoramic stereo camera with a pentagon shape consists of 5 stereo vision camera pairs to stream synchronized panoramic stereo images for the following three fusion modules. In the disparity fusion module, rectified stereo images produce the initial disparity maps using multiple stereo vision algorithms. Then, these initial disparity maps, along with the intensity images, are input into a disparity fusion network to produce refined disparity maps. Next, the refined disparity maps are converted into full-view point clouds or single-view point clouds for the pose fusion module. The pose fusion module adopts a two-stage global-coarse-to-local-fine strategy. In the first stage, each pair of full-view point clouds is registered by a global point cloud matching algorithm to estimate the transformation for a global pose graph's edge, which effectively implements loop closure. In the second stage, a local point cloud matching algorithm is used to match single-view point clouds in different nodes. Next, we locally refine the poses of all corresponding edges in the global pose graph using three proposed rules, thus constructing a refined pose graph. The refined pose graph is optimized to produce a global pose trajectory for volumetric fusion. In the volumetric fusion module, the global poses of all the nodes are used to integrate the single-view point clouds into the volume to produce the mesh of the whole garden. The proposed framework and its three fusion modules are tested on a real outdoor garden dataset to show the superiority of the performance.
A General Mobile Manipulator Automation Framework for Flexible Manufacturing in Hostile Industrial Environments
Feb 09, 2023
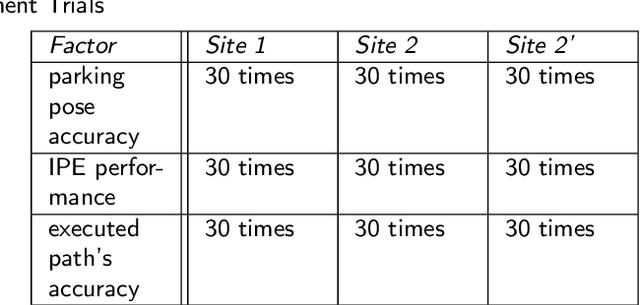

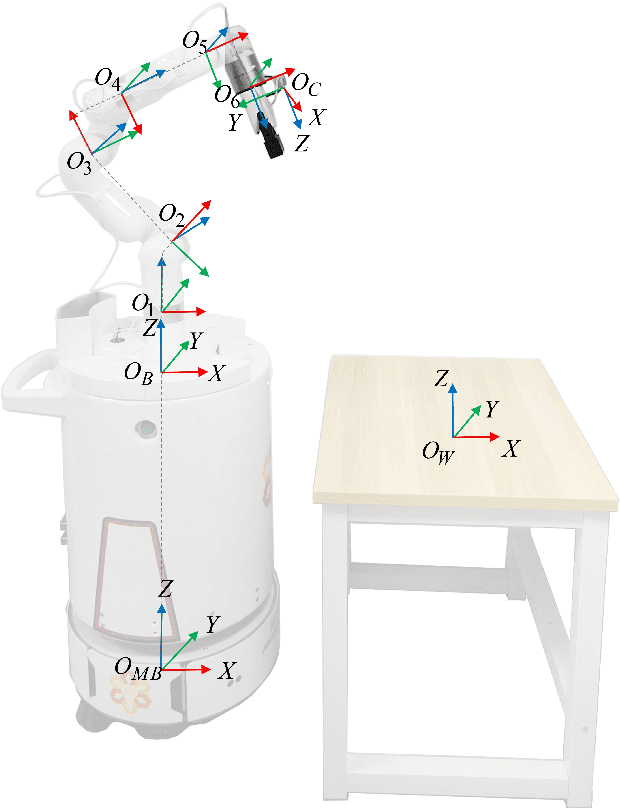
To enable a mobile manipulator to perform human tasks from a single teaching demonstration is vital to flexible manufacturing. We call our proposed method MMPA (Mobile Manipulator Process Automation with One-shot Teaching). Currently, there is no effective and robust MMPA framework which is not influenced by harsh industrial environments and the mobile base's parking precision. The proposed MMPA framework consists of two stages: collecting data (mobile base's location, environment information, end-effector's path) in the teaching stage for robot learning; letting the end-effector repeat the nearly same path as the reference path in the world frame to reproduce the work in the automation stage. More specifically, in the automation stage, the robot navigates to the specified location without the need of a precise parking. Then, based on colored point cloud registration, the proposed IPE (Iterative Pose Estimation by Eye & Hand) algorithm could estimate the accurate 6D relative parking pose of the robot arm base without the need of any marker. Finally, the robot could learn the error compensation from the parking pose's bias to modify the end-effector's path to make it repeat a nearly same path in the world coordinate system as recorded in the teaching stage. Hundreds of trials have been conducted with a real mobile manipulator to show the superior robustness of the system and the accuracy of the process automation regardless of the harsh industrial conditions and parking precision. For the released code, please contact marketing@amigaga.com
Online Incremental Non-Gaussian Inference for SLAM Using Normalizing Flows
Oct 02, 2021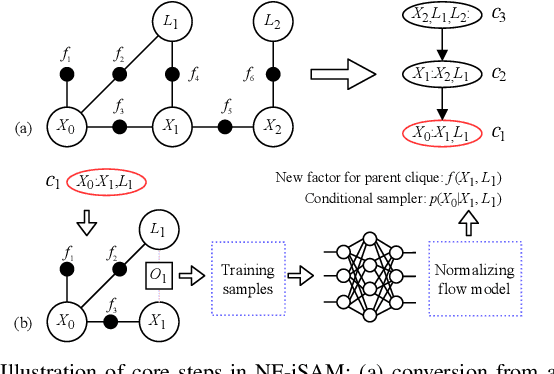
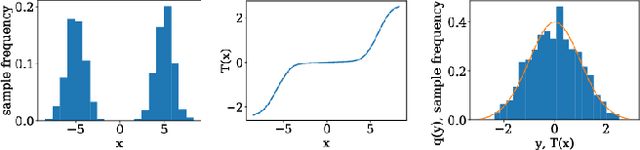
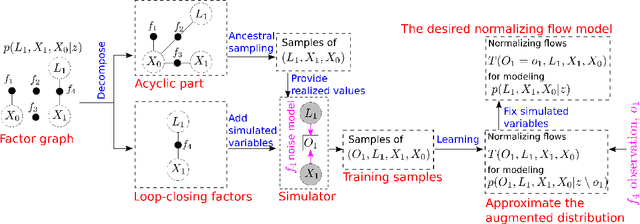

This paper presents a novel non-Gaussian inference algorithm, Normalizing Flow iSAM (NF-iSAM), for solving SLAM problems with non-Gaussian factors and/or nonlinear measurement models. NF-iSAM exploits the expressive power of neural networks to model normalizing flows that can accurately approximate the joint posterior of highly nonlinear and non-Gaussian factor graphs. By leveraging the Bayes tree, NF-iSAM is able to exploit the sparsity structure of SLAM, thus enabling efficient incremental updates similar to iSAM2, although in the more challenging non-Gaussian setting. We demonstrate the performance of NF-iSAM and compare it against state-of-the-art algorithms such as iSAM2 (Gaussian) and mm-iSAM (non-Gaussian) in synthetic and real range-only SLAM datasets with data association ambiguity.
NF-iSAM: Incremental Smoothing and Mapping via Normalizing Flows
May 11, 2021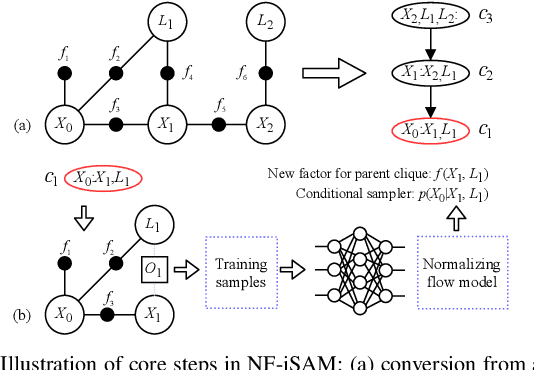
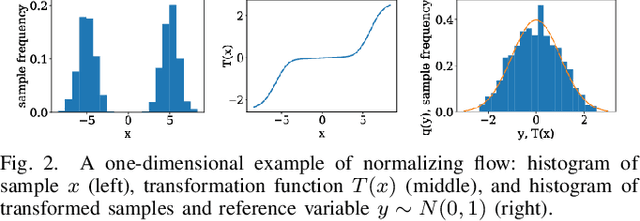
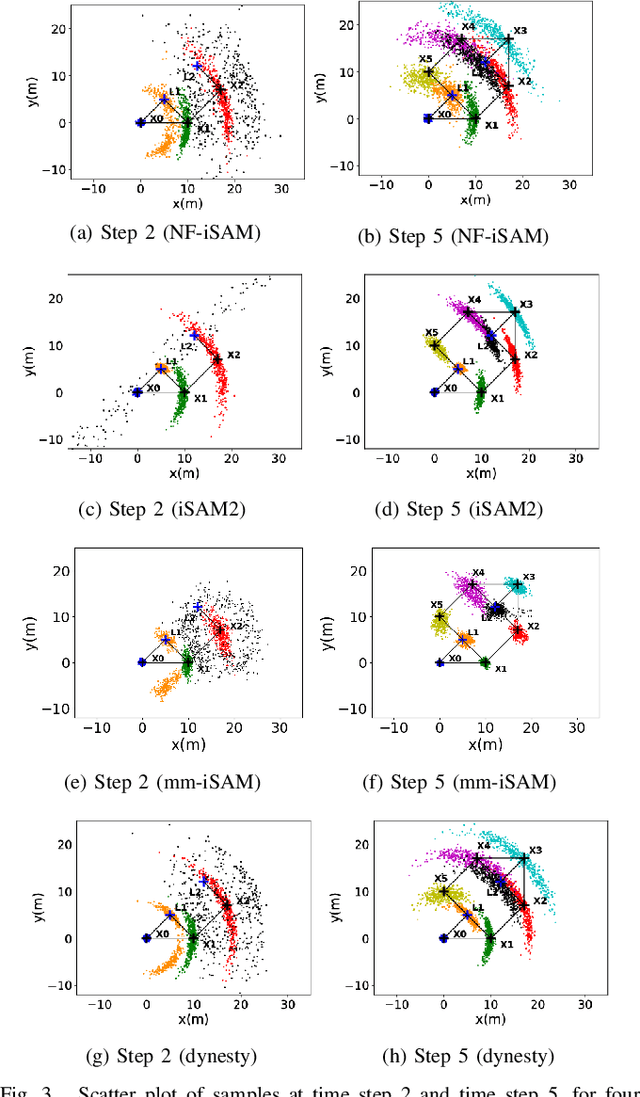
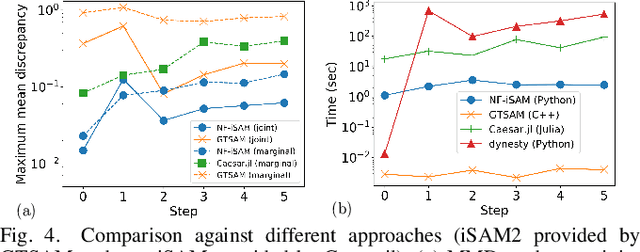
This paper presents a novel non-Gaussian inference algorithm, Normalizing Flow iSAM (NF-iSAM), for solving SLAM problems with non-Gaussian factors and/or non-linear measurement models. NF-iSAM exploits the expressive power of neural networks, and trains normalizing flows to draw samples from the joint posterior of non-Gaussian factor graphs. By leveraging the Bayes tree, NF-iSAM is able to exploit the sparsity structure of SLAM, thus enabling efficient incremental updates similar to iSAM2, albeit in the more challenging non-Gaussian setting. We demonstrate the performance of NF-iSAM and compare it against the state-of-the-art algorithms such as iSAM2 (Gaussian) and mm-iSAM (non-Gaussian) in synthetic and real range-only SLAM datasets.
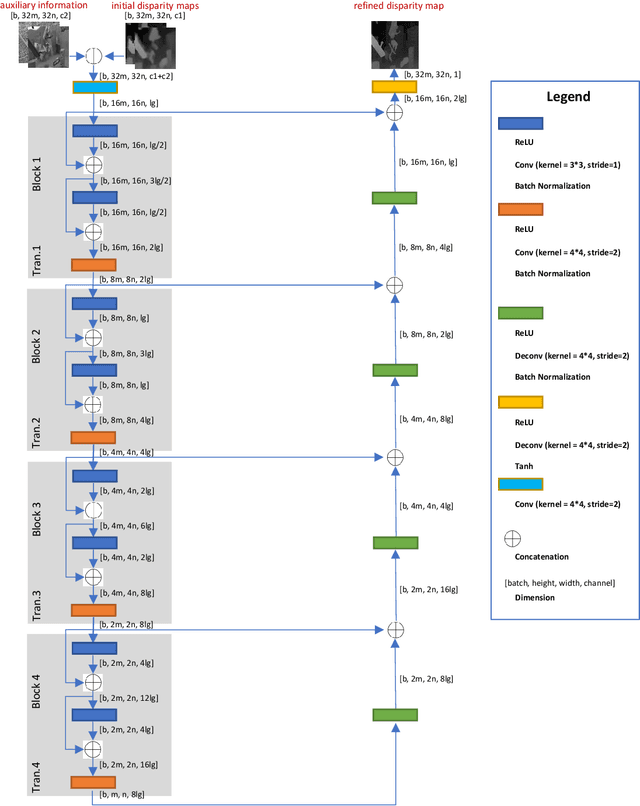
UDFNet: Unsupervised Disparity Fusion with Adversarial Networks
Apr 22, 2019
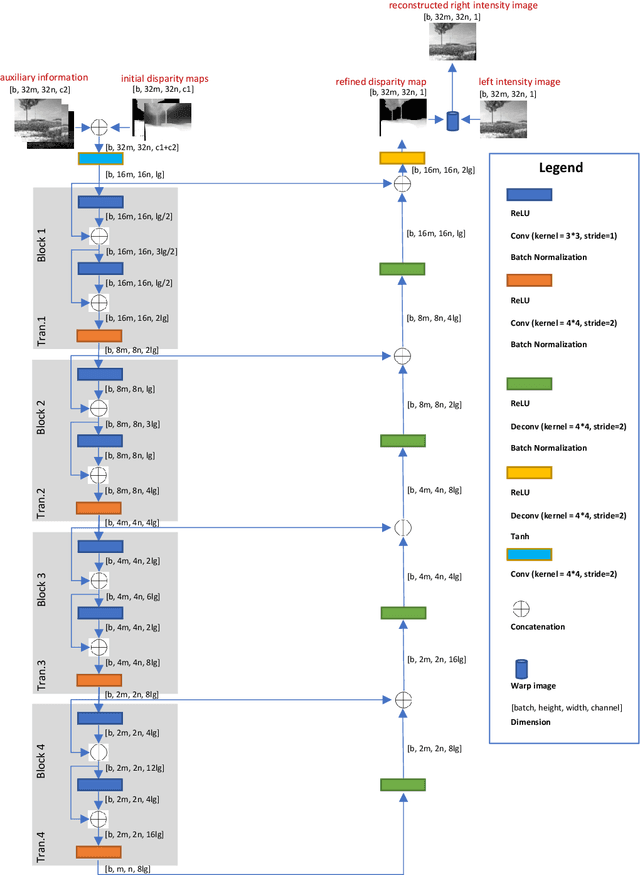

Existing disparity fusion methods based on deep learning achieve state-of-the-art performance, but they require ground truth disparity data to train. As far as I know, this is the first time an unsupervised disparity fusion not using ground truth disparity data has been proposed. In this paper, a mathematical model for disparity fusion is proposed to guide an adversarial network to train effectively without ground truth disparity data. The initial disparity maps are inputted from the left view along with auxiliary information (gradient, left & right intensity image) into the refiner and the refiner is trained to output the refined disparity map registered on the left view. The refined left disparity map and left intensity image are used to reconstruct a fake right intensity image. Finally, the fake and real right intensity images (from the right stereo vision camera) are fed into the discriminator. In the model, the refiner is trained to output a refined disparity value close to the weighted sum of the disparity inputs for global initialisation. Then, three refinement principles are adopted to refine the results further. (1) The reconstructed intensity error between the fake and real right intensity image is minimised. (2) The similarities between the fake and real right image in different receptive fields are maximised. (3) The refined disparity map is smoothed based on the corresponding intensity image. The adversarial networks' architectures are effective for the fusion task. The fusion time using the proposed network is small. The network can achieve 90 fps using Nvidia Geforce GTX 1080Ti on the Kitti2015 dataset when the input resolution is 1242 * 375 (Width * Height) without downsampling and cropping. The accuracy of this work is equal to (or better than) the state-of-the-art supervised methods.
DUGMA: Dynamic Uncertainty-Based Gaussian Mixture Alignment
Aug 02, 2018


Registering accurately point clouds from a cheap low-resolution sensor is a challenging task. Existing rigid registration methods failed to use the physical 3D uncertainty distribution of each point from a real sensor in the dynamic alignment process mainly because the uncertainty model for a point is static and invariant and it is hard to describe the change of these physical uncertainty models in the registration process. Additionally, the existing Gaussian mixture alignment architecture cannot be efficiently implement these dynamic changes. This paper proposes a simple architecture combining error estimation from sample covariances and dual dynamic global probability alignment using the convolution of uncertainty-based Gaussian Mixture Models (GMM) from point clouds. Firstly, we propose an efficient way to describe the change of each 3D uncertainty model, which represents the structure of the point cloud much better. Unlike the invariant GMM (representing a fixed point cloud) in traditional Gaussian mixture alignment, we use two uncertainty-based GMMs that change and interact with each other in each iteration. In order to have a wider basin of convergence than other local algorithms, we design a more robust energy function by convolving efficiently the two GMMs over the whole 3D space. Tens of thousands of trials have been conducted on hundreds of models from multiple datasets to demonstrate the proposed method's superior performance compared with the current state-of-the-art methods. The new dataset and code is available from https://github.com/Canpu999
Sdf-GAN: Semi-supervised Depth Fusion with Multi-scale Adversarial Networks
Mar 18, 2018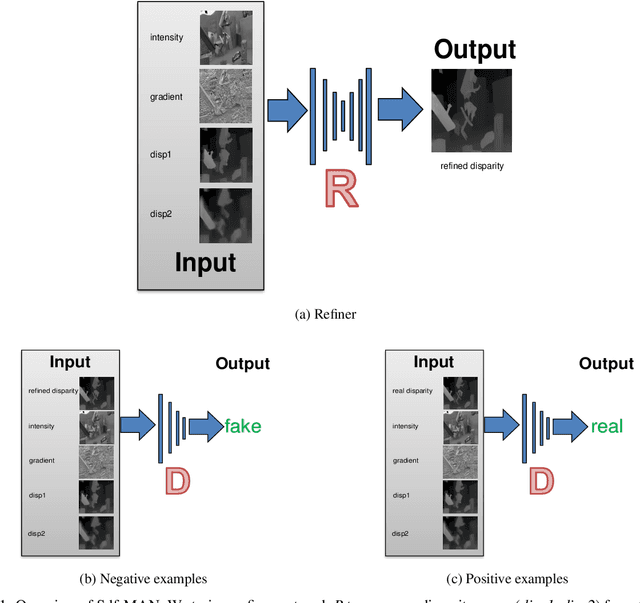
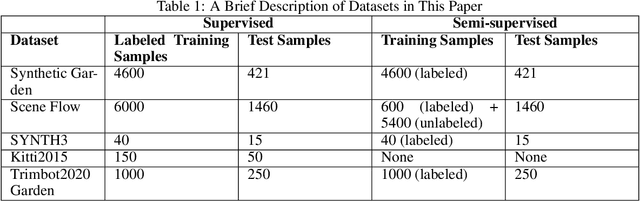
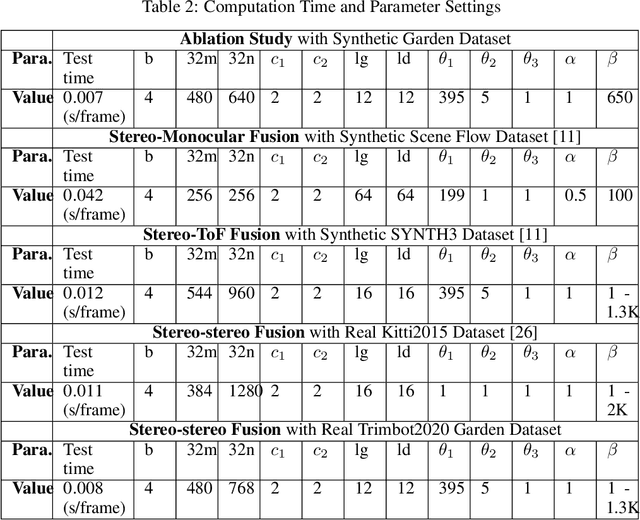
Fusing disparity maps from different algorithms to exploit their complementary advantages is still challenging. Uncertainty estimation and complex disparity relationships between neighboring pixels limit the accuracy and robustness of the existing methods and there is no common method for depth fusion of different kind of data. In this paper, we introduce a method to incorporate supplementary information (intensity, gradient constraints etc.) into a Generative Adversarial Network to better refine each input disparity value. By adopting a multi-scale strategy, the disparity relationship in the fused disparity map is a better estimate of the real distribution. The approach includes a more robust object function to avoid blurry edges, impaints invalid disparity values and requires much fewer ground data to train. The algorithm can be generalized to different kinds of depth fusion. The experiments were conducted through simulation and real data, exploring different fusion opportunities: stereo-monocular fusion from coarse input, stereo-stereo fusion from moderately accurate input, fusion from accurate binocular input and Time of Flight sensor. The experiments show the superiority of the proposed algorithm compared with the most recent algorithms on the public Scene Flow and SYNTH3 datasets. The code is available from https://github.com/Canpu999
Robust Rigid Point Registration based on Convolution of Adaptive Gaussian Mixture Models
Jul 26, 2017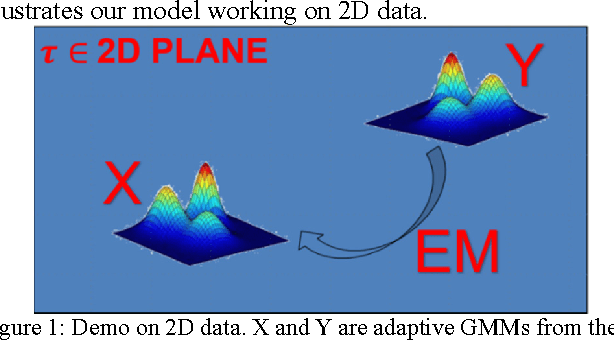
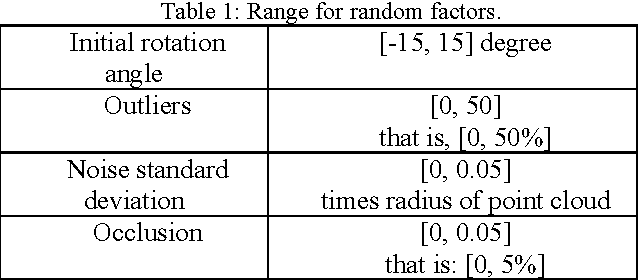

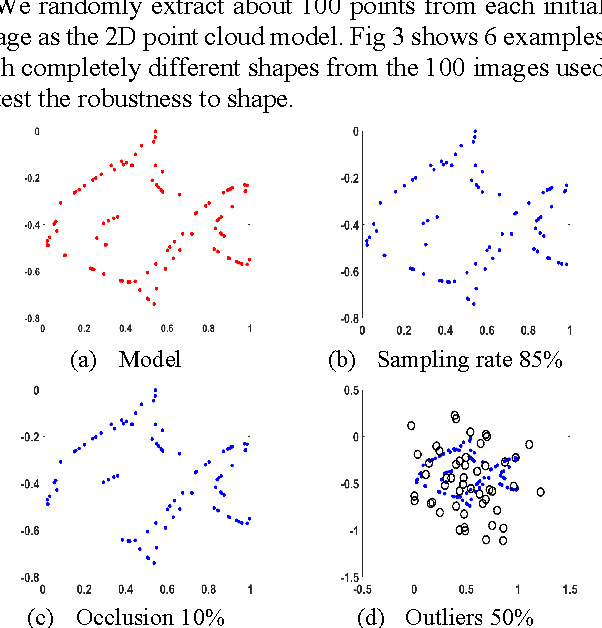
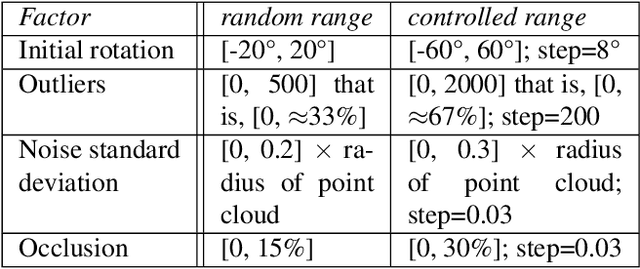
Matching 3D rigid point clouds in complex environments robustly and accurately is still a core technique used in many applications. This paper proposes a new architecture combining error estimation from sample covariances and dual global probability alignment based on the convolution of adaptive Gaussian Mixture Models (GMM) from point clouds. Firstly, a novel adaptive GMM is defined using probability distributions from the corresponding points. Then rigid point cloud alignment is performed by maximizing the global probability from the convolution of dual adaptive GMMs in the whole 2D or 3D space, which can be efficiently optimized and has a large zone of accurate convergence. Thousands of trials have been conducted on 200 models from public 2D and 3D datasets to demonstrate superior robustness and accuracy in complex environments with unpredictable noise, outliers, occlusion, initial rotation, shape and missing points.