 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaVR: Scene Latent Conditioned Generative Video Trajectory Re-Rendering using Large 4D Reconstruction Models
Jan 21, 2026Given a monocular video, the goal of video re-rendering is to generate views of the scene from a novel camera trajectory. Existing methods face two distinct challenges. Geometrically unconditioned models lack spatial awareness, leading to drift and deformation under viewpoint changes. On the other hand, geometrically-conditioned models depend on estimated depth and explicit reconstruction, making them susceptible to depth inaccuracies and calibration errors. We propose to address these challenges by using the implicit geometric knowledge embedded in the latent space of a large 4D reconstruction model to condition the video generation process. These latents capture scene structure in a continuous space without explicit reconstruction. Therefore, they provide a flexible representation that allows the pretrained diffusion prior to regularize errors more effectively. By jointly conditioning on these latents and source camera poses, we demonstrate that our model achieves state-of-the-art results on the video re-rendering task. Project webpage is https://lavr-4d-scene-rerender.github.io/
UnSAMFlow: Unsupervised Optical Flow Guided by Segment Anything Model
May 04, 2024



Traditional unsupervised optical flow methods are vulnerable to occlusions and motion boundaries due to lack of object-level information. Therefore, we propose UnSAMFlow, an unsupervised flow network that also leverages object information from the latest foundation model Segment Anything Model (SAM). We first include a self-supervised semantic augmentation module tailored to SAM masks. We also analyze the poor gradient landscapes of traditional smoothness losses and propose a new smoothness definition based on homography instead. A simple yet effective mask feature module has also been added to further aggregate features on the object level. With all these adaptations, our method produces clear optical flow estimation with sharp boundaries around objects, which outperforms state-of-the-art methods on both KITTI and Sintel datasets. Our method also generalizes well across domains and runs very efficiently.
AnyFlow: Arbitrary Scale Optical Flow with Implicit Neural Representation
Mar 29, 2023



To apply optical flow in practice, it is often necessary to resize the input to smaller dimensions in order to reduce computational costs. However, downsizing inputs makes the estimation more challenging because objects and motion ranges become smaller. Even though recent approaches have demonstrated high-quality flow estimation, they tend to fail to accurately model small objects and precise boundaries when the input resolution is lowered, restricting their applicability to high-resolution inputs. In this paper, we introduce AnyFlow, a robust network that estimates accurate flow from images of various resolutions. By representing optical flow as a continuous coordinate-based representation, AnyFlow generates outputs at arbitrary scales from low-resolution inputs, demonstrating superior performance over prior works in capturing tiny objects with detail preservation on a wide range of scenes. We establish a new state-of-the-art performance of cross-dataset generalization on the KITTI dataset, while achieving comparable accuracy on the online benchmarks to other SOTA methods.
Learning to Separate Multiple Illuminants in a Single Image
Nov 29, 2018



We present a method to separate a single image captured under two illuminants, with different spectra, into the two images corresponding to the appearance of the scene under each individual illuminant. We do this by training a deep neural network to predict the per-pixel reflectance chromaticity of the scene, which we use in conjunction with a previous flash/no-flash image-based separation algorithm to produce the final two output images. We design our reflectance chromaticity network and loss functions by incorporating intuitions from the physics of image formation. We show that this leads to significantly better performance than other single image techniques and even approaches the quality of the two image separation method.
Illuminant Spectra-based Source Separation Using Flash Photography
Nov 27, 2017
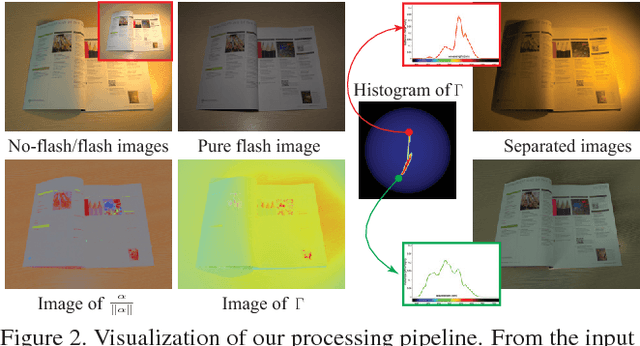

Real-world lighting often consists of multiple illuminants with different spectra. Separating and manipulating these illuminants in post-process is a challenging problem that requires either significant manual input or calibrated scene geometry and lighting. In this work, we leverage a flash/no-flash image pair to analyze and edit scene illuminants based on their spectral differences. We derive a novel physics-based relationship between color variations in the observed flash/no-flash intensities and the spectra and surface shading corresponding to individual scene illuminants. Our technique uses this constraint to automatically separate an image into constituent images lit by each illuminant. This separation can be used to support applications like white balancing, lighting editing, and RGB photometric stereo, where we demonstrate results that outperform state-of-the-art techniques on a wide range of images.
Shape and Spatially-Varying Reflectance Estimation From Virtual Exemplars
Sep 21, 2016
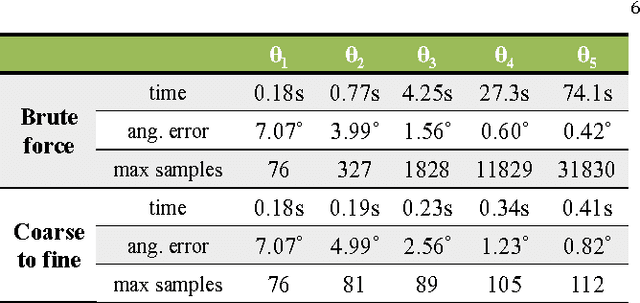
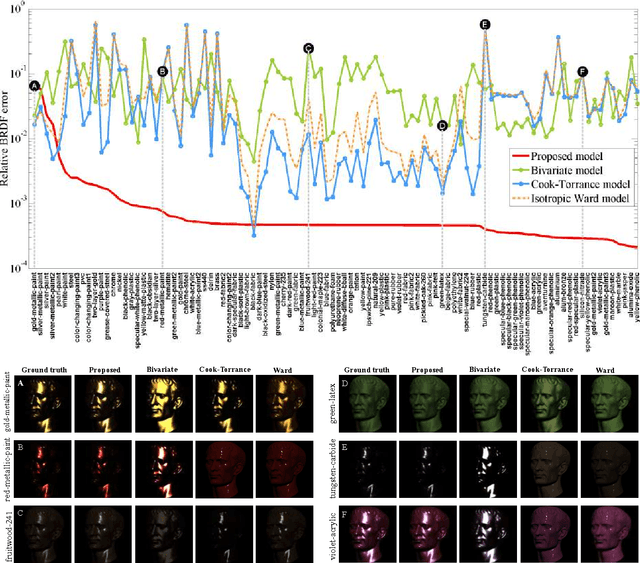

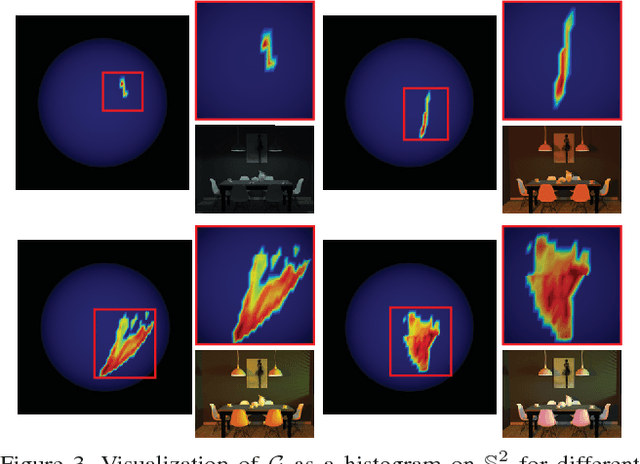
This paper addresses the problem of estimating the shape of objects that exhibit spatially-varying reflectance. We assume that multiple images of the object are obtained under a fixed view-point and varying illumination, i.e., the setting of photometric stereo. At the core of our techniques is the assumption that the BRDF at each pixel lies in the non-negative span of a known BRDF dictionary.This assumption enables a per-pixel surface normal and BRDF estimation framework that is computationally tractable and requires no initialization in spite of the underlying problem being non-convex. Our estimation framework first solves for the surface normal at each pixel using a variant of example-based photometric stereo. We design an efficient multi-scale search strategy for estimating the surface normal and subsequently, refine this estimate using a gradient descent procedure. Given the surface normal estimate, we solve for the spatially-varying BRDF by constraining the BRDF at each pixel to be in the span of the BRDF dictionary, here, we use additional priors to further regularize the solution. A hallmark of our approach is that it does not require iterative optimization techniques nor the need for careful initialization, both of which are endemic to most state-of-the-art techniques. We showcase the performance of our technique on a wide range of simulated and real scenes where we outperform competing methods.
An Empirical Study of Dimensional Reduction Techniques for Facial Action Units Detection
Mar 25, 2016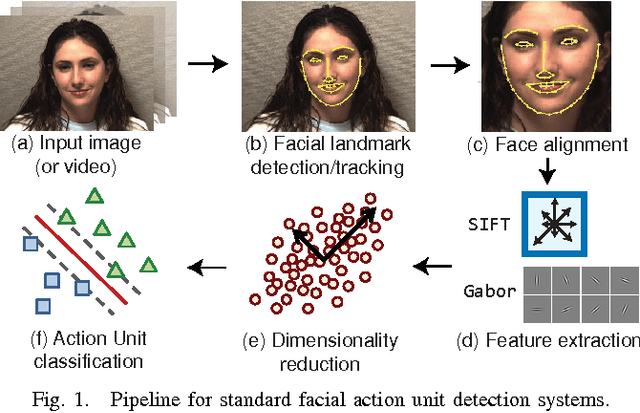

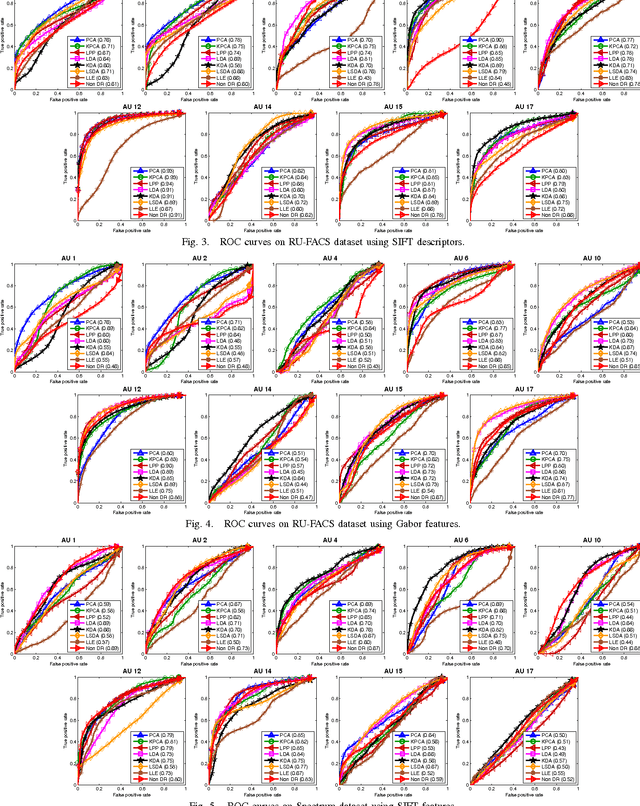

Biologically inspired features, such as Gabor filters, result in very high dimensional measurement. Does reducing the dimensionality of the feature space afford advantages beyond computational efficiency? Do some approaches to dimensionality reduction (DR) yield improved action unit detection? To answer these questions, we compared DR approaches in two relatively large databases of spontaneous facial behavior (45 participants in total with over 2 minutes of FACS-coded video per participant). Facial features were tracked and aligned using active appearance models (AAM). SIFT and Gabor features were extracted from local facial regions. We compared linear (PCA and KPCA), manifold (LPP and LLE), supervised (LDA and KDA) and hybrid approaches (LSDA) to DR with respect to AU detection. For further comparison, a no-DR control condition was included as well. Linear support vector machine classifiers with independent train and test sets were used for AU detection. AU detection was quantified using area under the ROC curve and F1. Baseline results for PCA with Gabor features were comparable with previous research. With some notable exceptions, DR improved AU detection relative to no-DR. Locality embedding approaches proved vulnerable to \emph{out-of-sample} problems. Gradient-based SIFT lead to better AU detection than the filter-based Gabor features. For area under the curve, few differences were found between linear and other DR approaches. For F1, results were mixed. For both metrics, the pattern of results varied among action units. These findings suggest that action unit detection may be optimized by using specific DR for specific action units. PCA and LDA were the most efficient approaches; KDA was the least efficient.
A Dictionary-based Approach for Estimating Shape and Spatially-Varying Reflectance
Mar 14, 2015



We present a technique for estimating the shape and reflectance of an object in terms of its surface normals and spatially-varying BRDF. We assume that multiple images of the object are obtained under fixed view-point and varying illumination, i.e, the setting of photometric stereo. Assuming that the BRDF at each pixel lies in the non-negative span of a known BRDF dictionary, we derive a per-pixel surface normal and BRDF estimation framework that requires neither iterative optimization techniques nor careful initialization, both of which are endemic to most state-of-the-art techniques. We showcase the performance of our technique on a wide range of simulated and real scenes where we outperform competing methods.