 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Realistic Virtual Try-on Application for Foundation Makeup with Kubelka-Munk Theory
Jul 09, 2025Augmented reality is revolutionizing beauty industry with virtual try-on (VTO) applications, which empowers users to try a wide variety of products using their phones without the hassle of physically putting on real products. A critical technical challenge in foundation VTO applications is the accurate synthesis of foundation-skin tone color blending while maintaining the scalability of the method across diverse product ranges. In this work, we propose a novel method to approximate well-established Kubelka-Munk (KM) theory for faster image synthesis while preserving foundation-skin tone color blending realism. Additionally, we build a scalable end-to-end framework for realistic foundation makeup VTO solely depending on the product information available on e-commerce sites. We validate our method using real-world makeup images, demonstrating that our framework outperforms other techniques.
Direct and Explicit 3D Generation from a Single Image
Nov 17, 2024



Current image-to-3D approaches suffer from high computational costs and lack scalability for high-resolution outputs. In contrast, we introduce a novel framework to directly generate explicit surface geometry and texture using multi-view 2D depth and RGB images along with 3D Gaussian features using a repurposed Stable Diffusion model. We introduce a depth branch into U-Net for efficient and high quality multi-view, cross-domain generation and incorporate epipolar attention into the latent-to-pixel decoder for pixel-level multi-view consistency. By back-projecting the generated depth pixels into 3D space, we create a structured 3D representation that can be either rendered via Gaussian splatting or extracted to high-quality meshes, thereby leveraging additional novel view synthesis loss to further improve our performance. Extensive experiments demonstrate that our method surpasses existing baselines in geometry and texture quality while achieving significantly faster generation time.
MRC-Net: 6-DoF Pose Estimation with MultiScale Residual Correlation
Mar 20, 2024We propose a single-shot approach to determining 6-DoF pose of an object with available 3D computer-aided design (CAD) model from a single RGB image. Our method, dubbed MRC-Net, comprises two stages. The first performs pose classification and renders the 3D object in the classified pose. The second stage performs regression to predict fine-grained residual pose within class. Connecting the two stages is a novel multi-scale residual correlation (MRC) layer that captures high-and-low level correspondences between the input image and rendering from first stage. MRC-Net employs a Siamese network with shared weights between both stages to learn embeddings for input and rendered images. To mitigate ambiguity when predicting discrete pose class labels on symmetric objects, we use soft probabilistic labels to define pose class in the first stage. We demonstrate state-of-the-art accuracy, outperforming all competing RGB-based methods on four challenging BOP benchmark datasets: T-LESS, LM-O, YCB-V, and ITODD. Our method is non-iterative and requires no complex post-processing.
All-Weather Deep Outdoor Lighting Estimation
Jun 12, 2019
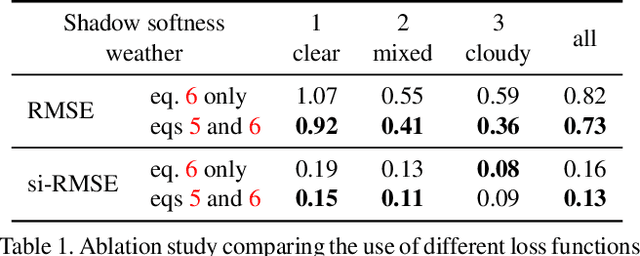

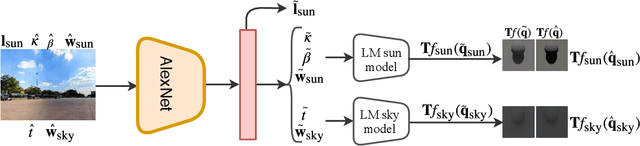
We present a neural network that predicts HDR outdoor illumination from a single LDR image. At the heart of our work is a method to accurately learn HDR lighting from LDR panoramas under any weather condition. We achieve this by training another CNN (on a combination of synthetic and real images) to take as input an LDR panorama, and regress the parameters of the Lalonde-Matthews outdoor illumination model. This model is trained such that it a) reconstructs the appearance of the sky, and b) renders the appearance of objects lit by this illumination. We use this network to label a large-scale dataset of LDR panoramas with lighting parameters and use them to train our single image outdoor lighting estimation network. We demonstrate, via extensive experiments, that both our panorama and single image networks outperform the state of the art, and unlike prior work, are able to handle weather conditions ranging from fully sunny to overcast skies.
Fast Spatially-Varying Indoor Lighting Estimation
Jun 10, 2019
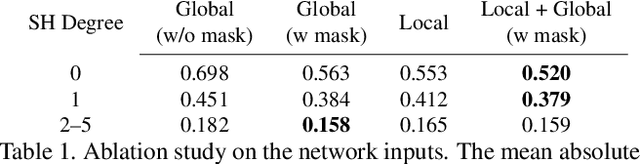

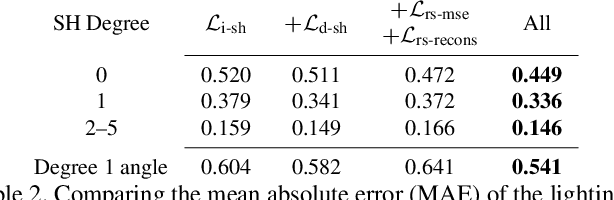
We propose a real-time method to estimate spatiallyvarying indoor lighting from a single RGB image. Given an image and a 2D location in that image, our CNN estimates a 5th order spherical harmonic representation of the lighting at the given location in less than 20ms on a laptop mobile graphics card. While existing approaches estimate a single, global lighting representation or require depth as input, our method reasons about local lighting without requiring any geometry information. We demonstrate, through quantitative experiments including a user study, that our results achieve lower lighting estimation errors and are preferred by users over the state-of-the-art. Our approach can be used directly for augmented reality applications, where a virtual object is relit realistically at any position in the scene in real-time.
* CVPR19
MT-VAE: Learning Motion Transformations to Generate Multimodal Human Dynamics
Aug 14, 2018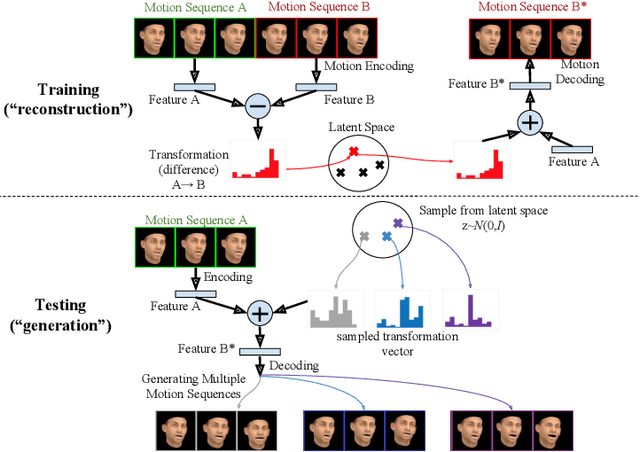
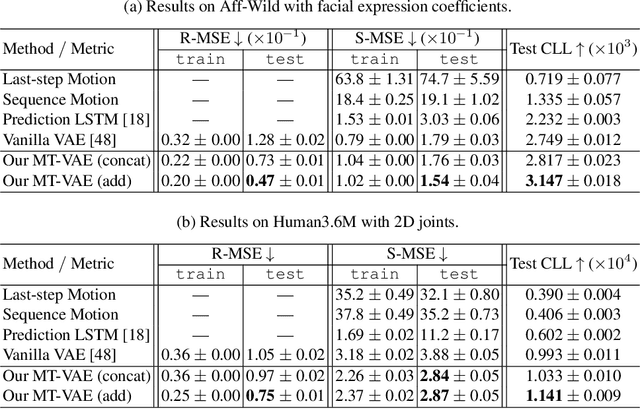
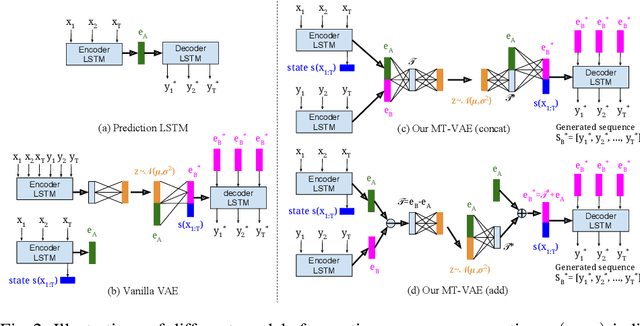

Long-term human motion can be represented as a series of motion modes---motion sequences that capture short-term temporal dynamics---with transitions between them. We leverage this structure and present a novel Motion Transformation Variational Auto-Encoders (MT-VAE) for learning motion sequence generation. Our model jointly learns a feature embedding for motion modes (that the motion sequence can be reconstructed from) and a feature transformation that represents the transition of one motion mode to the next motion mode. Our model is able to generate multiple diverse and plausible motion sequences in the future from the same input. We apply our approach to both facial and full body motion, and demonstrate applications like analogy-based motion transfer and video synthesis.
Automatic Adaptation of Person Association for Multiview Tracking in Group Activities
May 22, 2018


Reliable markerless motion tracking of multiple people participating in complex group activity from multiple handheld cameras is challenging due to frequent occlusions, strong viewpoint and appearance variations, and asynchronous video streams. The key to solving this problem is to reliably associate the same person across distant viewpoint and temporal instances. In this work, we combine motion tracking, mutual exclusion constraints, and multiview geometry in a multitask learning framework to automatically adapt a generic person appearance descriptor to the domain videos. Tracking is formulated as a spatiotemporally constrained clustering using the adapted person descriptor. Physical human constraints are exploited to reconstruct accurate and consistent 3D skeletons for every person across the entire sequence. We show significant improvement in association accuracy (up to 18%) in events with up to 60 people and 3D human skeleton reconstruction (5 to 10 times) over the baseline for events captured "in the wild".
A Perceptual Measure for Deep Single Image Camera Calibration
Apr 22, 2018

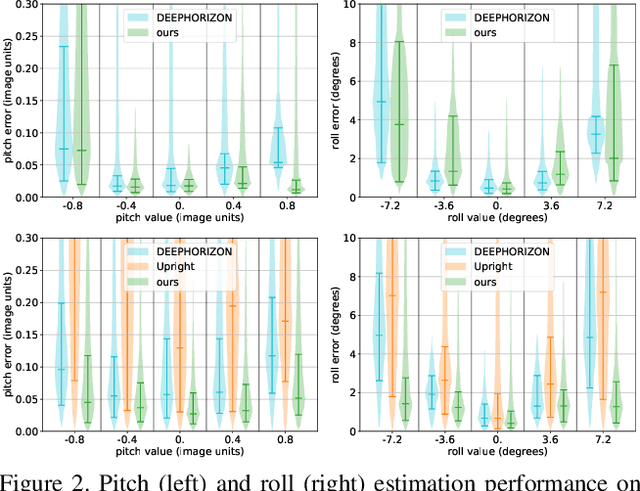
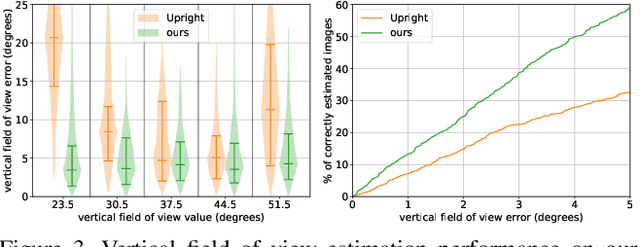
Most current single image camera calibration methods rely on specific image features or user input, and cannot be applied to natural images captured in uncontrolled settings. We propose directly inferring camera calibration parameters from a single image using a deep convolutional neural network. This network is trained using automatically generated samples from a large-scale panorama dataset, and considerably outperforms other methods, including recent deep learning-based approaches, in terms of standard L2 error. However, we argue that in many cases it is more important to consider how humans perceive errors in camera estimation. To this end, we conduct a large-scale human perception study where we ask users to judge the realism of 3D objects composited with and without ground truth camera calibration. Based on this study, we develop a new perceptual measure for camera calibration, and demonstrate that our deep calibration network outperforms other methods on this measure. Finally, we demonstrate the use of our calibration network for a number of applications including virtual object insertion, image retrieval and compositing.
Deep Outdoor Illumination Estimation
Apr 11, 2018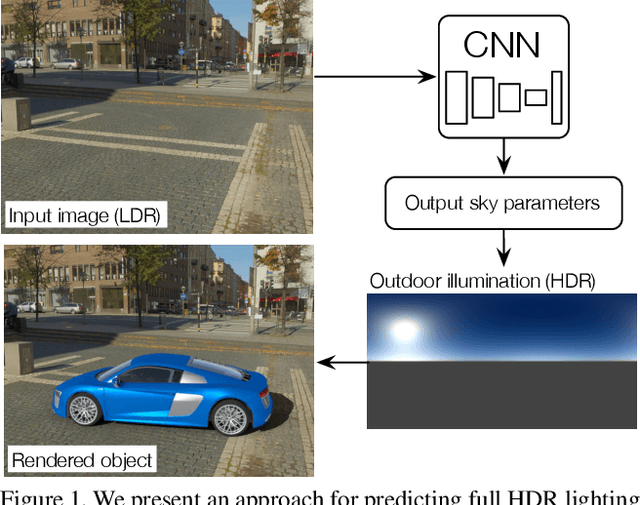

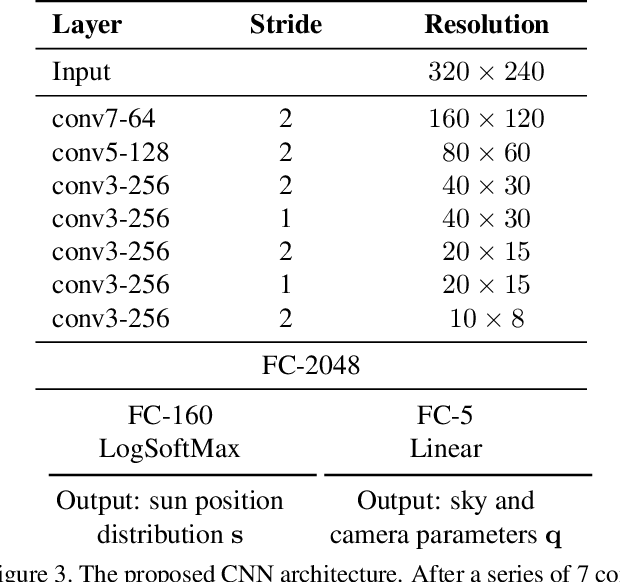
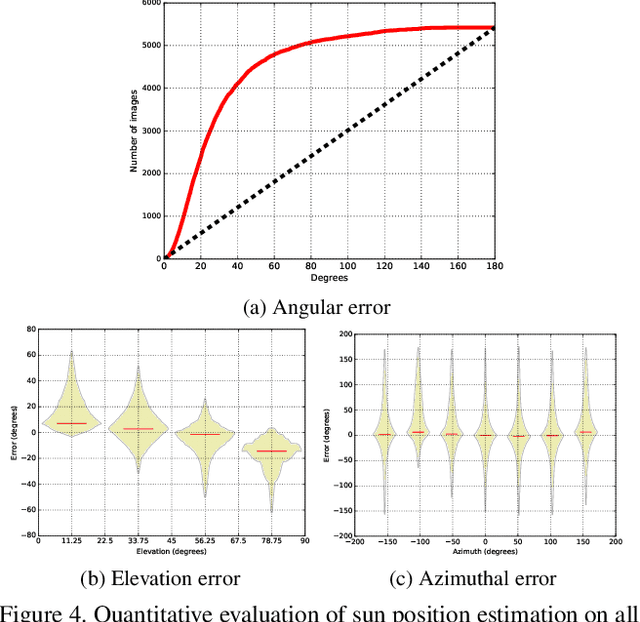
We present a CNN-based technique to estimate high-dynamic range outdoor illumination from a single low dynamic range image. To train the CNN, we leverage a large dataset of outdoor panoramas. We fit a low-dimensional physically-based outdoor illumination model to the skies in these panoramas giving us a compact set of parameters (including sun position, atmospheric conditions, and camera parameters). We extract limited field-of-view images from the panoramas, and train a CNN with this large set of input image--output lighting parameter pairs. Given a test image, this network can be used to infer illumination parameters that can, in turn, be used to reconstruct an outdoor illumination environment map. We demonstrate that our approach allows the recovery of plausible illumination conditions and enables photorealistic virtual object insertion from a single image. An extensive evaluation on both the panorama dataset and captured HDR environment maps shows that our technique significantly outperforms previous solutions to this problem.
Illuminant Spectra-based Source Separation Using Flash Photography
Nov 27, 2017
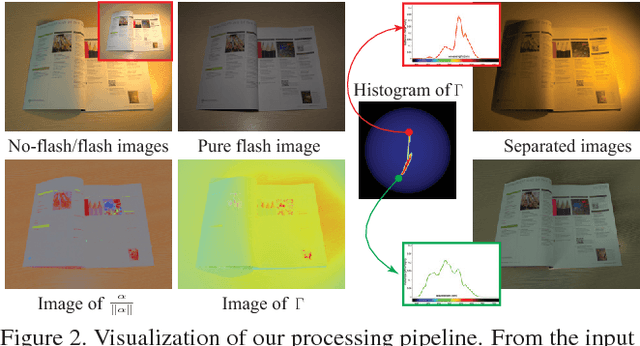
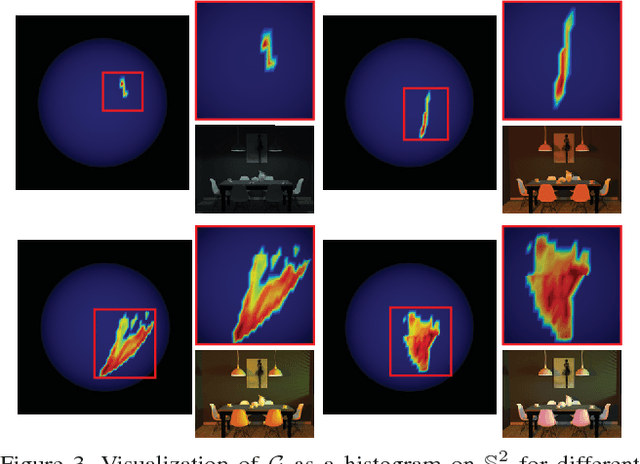

Real-world lighting often consists of multiple illuminants with different spectra. Separating and manipulating these illuminants in post-process is a challenging problem that requires either significant manual input or calibrated scene geometry and lighting. In this work, we leverage a flash/no-flash image pair to analyze and edit scene illuminants based on their spectral differences. We derive a novel physics-based relationship between color variations in the observed flash/no-flash intensities and the spectra and surface shading corresponding to individual scene illuminants. Our technique uses this constraint to automatically separate an image into constituent images lit by each illuminant. This separation can be used to support applications like white balancing, lighting editing, and RGB photometric stereo, where we demonstrate results that outperform state-of-the-art techniques on a wide range of images.