 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverLight: Indoor-Outdoor Editable HDR Lighting Estimation
Apr 26, 2023


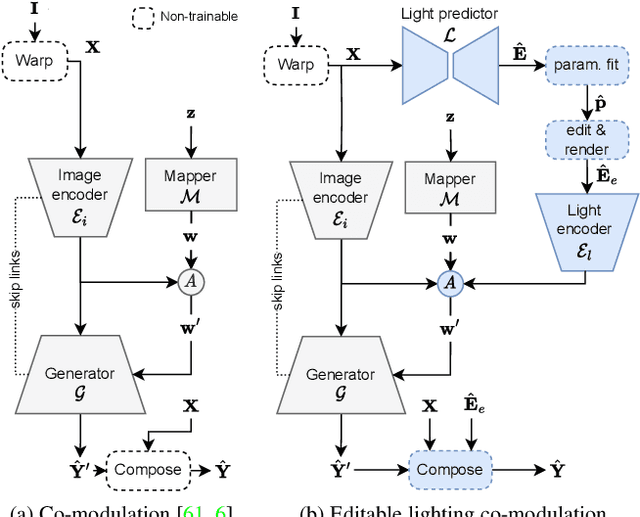
Because of the diversity in lighting environments, existing illumination estimation techniques have been designed explicitly on indoor or outdoor environments. Methods have focused specifically on capturing accurate energy (e.g., through parametric lighting models), which emphasizes shading and strong cast shadows; or producing plausible texture (e.g., with GANs), which prioritizes plausible reflections. Approaches which provide editable lighting capabilities have been proposed, but these tend to be with simplified lighting models, offering limited realism. In this work, we propose to bridge the gap between these recent trends in the literature, and propose a method which combines a parametric light model with 360{\deg} panoramas, ready to use as HDRI in rendering engines. We leverage recent advances in GAN-based LDR panorama extrapolation from a regular image, which we extend to HDR using parametric spherical gaussians. To achieve this, we introduce a novel lighting co-modulation method that injects lighting-related features throughout the generator, tightly coupling the original or edited scene illumination within the panorama generation process. In our representation, users can easily edit light direction, intensity, number, etc. to impact shading while providing rich, complex reflections while seamlessly blending with the edits. Furthermore, our method encompasses indoor and outdoor environments, demonstrating state-of-the-art results even when compared to domain-specific methods.
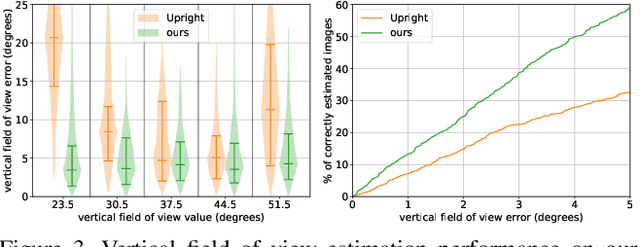
Guided Co-Modulated GAN for 360° Field of View Extrapolation
Apr 15, 2022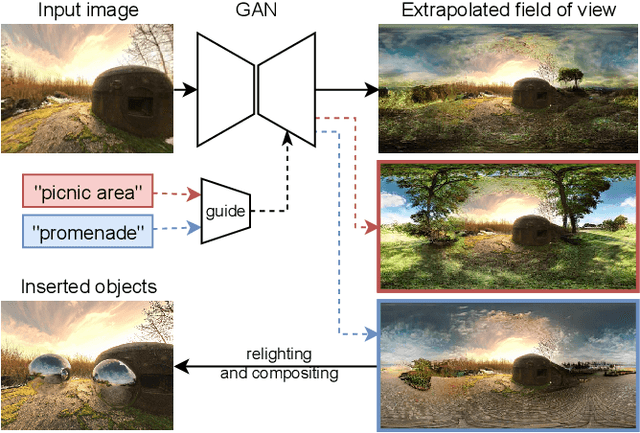
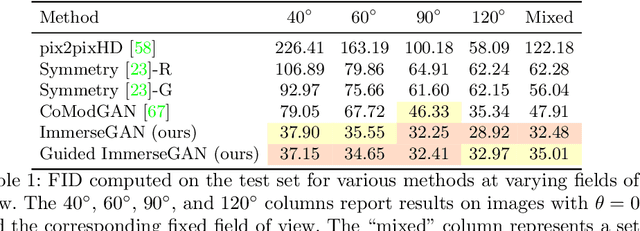


We propose a method to extrapolate a 360{\deg} field of view from a single image that allows for user-controlled synthesis of the out-painted content. To do so, we propose improvements to an existing GAN-based in-painting architecture for out-painting panoramic image representation. Our method obtains state-of-the-art results and outperforms previous methods on standard image quality metrics. To allow controlled synthesis of out-painting, we introduce a novel guided co-modulation framework, which drives the image generation process with a common pretrained discriminative model. Doing so maintains the high visual quality of generated panoramas while enabling user-controlled semantic content in the extrapolated field of view. We demonstrate the state-of-the-art results of our method on field of view extrapolation both qualitatively and quantitatively, providing thorough analysis of our novel editing capabilities. Finally, we demonstrate that our approach benefits the photorealistic virtual insertion of highly glossy objects in photographs.
Single View Metrology in the Wild
Aug 11, 2020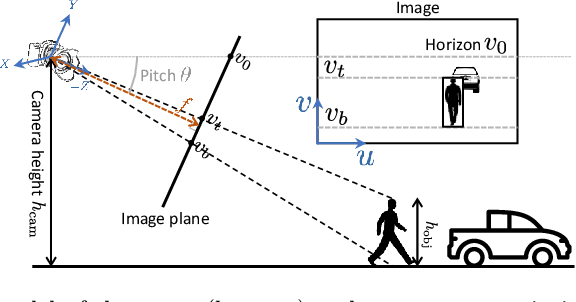

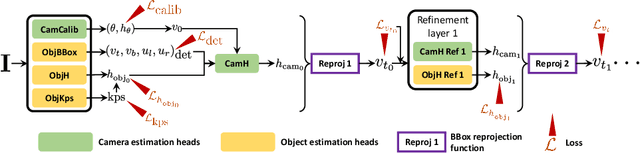
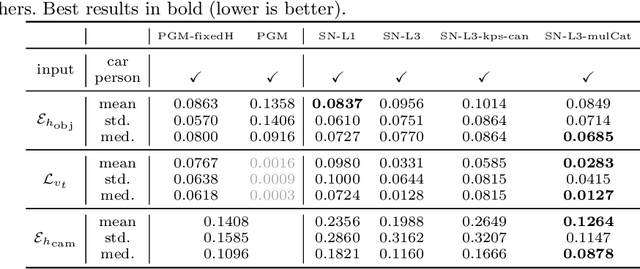
Most 3D reconstruction methods may only recover scene properties up to a global scale ambiguity. We present a novel approach to single view metrology that can recover the absolute scale of a scene represented by 3D heights of objects or camera height above the ground as well as camera parameters of orientation and field of view, using just a monocular image acquired in unconstrained condition. Our method relies on data-driven priors learned by a deep network specifically designed to imbibe weakly supervised constraints from the interplay of the unknown camera with 3D entities such as object heights, through estimation of bounding box projections. We leverage categorical priors for objects such as humans or cars that commonly occur in natural images, as references for scale estimation. We demonstrate state-of-the-art qualitative and quantitative results on several datasets as well as applications including virtual object insertion. Furthermore, the perceptual quality of our outputs is validated by a user study.
UprightNet: Geometry-Aware Camera Orientation Estimation from Single Images
Aug 19, 2019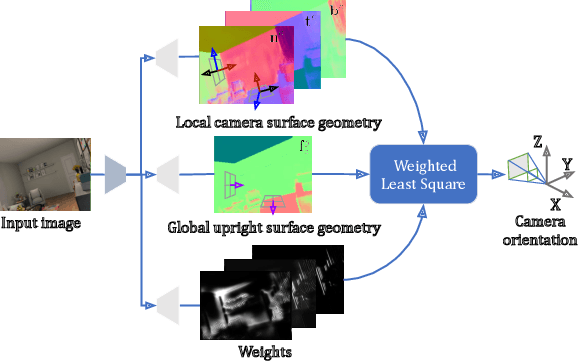
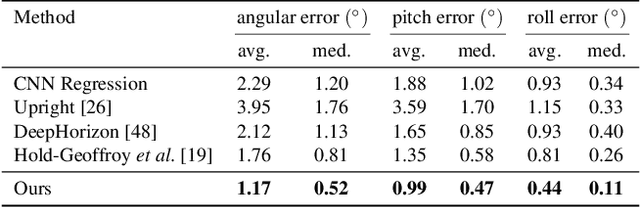

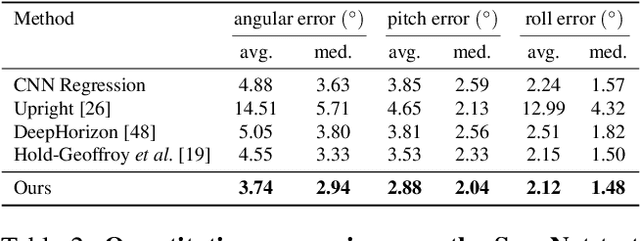
We introduce UprightNet, a learning-based approach for estimating 2DoF camera orientation from a single RGB image of an indoor scene. Unlike recent methods that leverage deep learning to perform black-box regression from image to orientation parameters, we propose an end-to-end framework that incorporates explicit geometric reasoning. In particular, we design a network that predicts two representations of scene geometry, in both the local camera and global reference coordinate systems, and solves for the camera orientation as the rotation that best aligns these two predictions via a differentiable least squares module. This network can be trained end-to-end, and can be supervised with both ground truth camera poses and intermediate representations of surface geometry. We evaluate UprightNet on the single-image camera orientation task on synthetic and real datasets, and show significant improvements over prior state-of-the-art approaches.
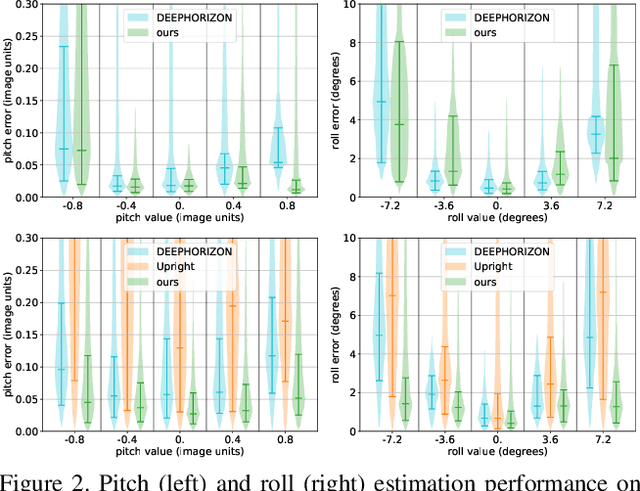
All-Weather Deep Outdoor Lighting Estimation
Jun 12, 2019
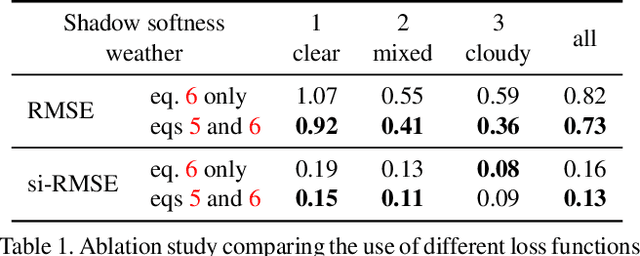

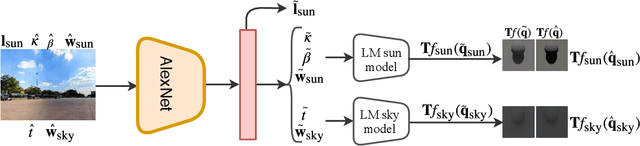
We present a neural network that predicts HDR outdoor illumination from a single LDR image. At the heart of our work is a method to accurately learn HDR lighting from LDR panoramas under any weather condition. We achieve this by training another CNN (on a combination of synthetic and real images) to take as input an LDR panorama, and regress the parameters of the Lalonde-Matthews outdoor illumination model. This model is trained such that it a) reconstructs the appearance of the sky, and b) renders the appearance of objects lit by this illumination. We use this network to label a large-scale dataset of LDR panoramas with lighting parameters and use them to train our single image outdoor lighting estimation network. We demonstrate, via extensive experiments, that both our panorama and single image networks outperform the state of the art, and unlike prior work, are able to handle weather conditions ranging from fully sunny to overcast skies.
A Perceptual Measure for Deep Single Image Camera Calibration
Apr 22, 2018

Most current single image camera calibration methods rely on specific image features or user input, and cannot be applied to natural images captured in uncontrolled settings. We propose directly inferring camera calibration parameters from a single image using a deep convolutional neural network. This network is trained using automatically generated samples from a large-scale panorama dataset, and considerably outperforms other methods, including recent deep learning-based approaches, in terms of standard L2 error. However, we argue that in many cases it is more important to consider how humans perceive errors in camera estimation. To this end, we conduct a large-scale human perception study where we ask users to judge the realism of 3D objects composited with and without ground truth camera calibration. Based on this study, we develop a new perceptual measure for camera calibration, and demonstrate that our deep calibration network outperforms other methods on this measure. Finally, we demonstrate the use of our calibration network for a number of applications including virtual object insertion, image retrieval and compositing.