 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality in Video Diffusers is Separable from Denoising
Feb 10, 2026Causality -- referring to temporal, uni-directional cause-effect relationships between components -- underlies many complex generative processes, including videos, language, and robot trajectories. Current causal diffusion models entangle temporal reasoning with iterative denoising, applying causal attention across all layers, at every denoising step, and over the entire context. In this paper, we show that the causal reasoning in these models is separable from the multi-step denoising process. Through systematic probing of autoregressive video diffusers, we uncover two key regularities: (1) early layers produce highly similar features across denoising steps, indicating redundant computation along the diffusion trajectory; and (2) deeper layers exhibit sparse cross-frame attention and primarily perform intra-frame rendering. Motivated by these findings, we introduce Separable Causal Diffusion (SCD), a new architecture that explicitly decouples once-per-frame temporal reasoning, via a causal transformer encoder, from multi-step frame-wise rendering, via a lightweight diffusion decoder. Extensive experiments on both pretraining and post-training tasks across synthetic and real benchmarks show that SCD significantly improves throughput and per-frame latency while matching or surpassing the generation quality of strong causal diffusion baselines.
Self-Evaluation Unlocks Any-Step Text-to-Image Generation
Dec 26, 2025We introduce the Self-Evaluating Model (Self-E), a novel, from-scratch training approach for text-to-image generation that supports any-step inference. Self-E learns from data similarly to a Flow Matching model, while simultaneously employing a novel self-evaluation mechanism: it evaluates its own generated samples using its current score estimates, effectively serving as a dynamic self-teacher. Unlike traditional diffusion or flow models, it does not rely solely on local supervision, which typically necessitates many inference steps. Unlike distillation-based approaches, it does not require a pretrained teacher. This combination of instantaneous local learning and self-driven global matching bridges the gap between the two paradigms, enabling the training of a high-quality text-to-image model from scratch that excels even at very low step counts. Extensive experiments on large-scale text-to-image benchmarks show that Self-E not only excels in few-step generation, but is also competitive with state-of-the-art Flow Matching models at 50 steps. We further find that its performance improves monotonically as inference steps increase, enabling both ultra-fast few-step generation and high-quality long-trajectory sampling within a single unified model. To our knowledge, Self-E is the first from-scratch, any-step text-to-image model, offering a unified framework for efficient and scalable generation.
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Jun 09, 2025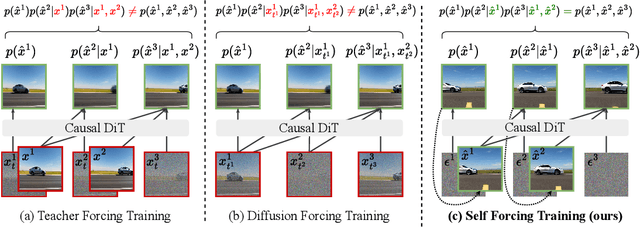
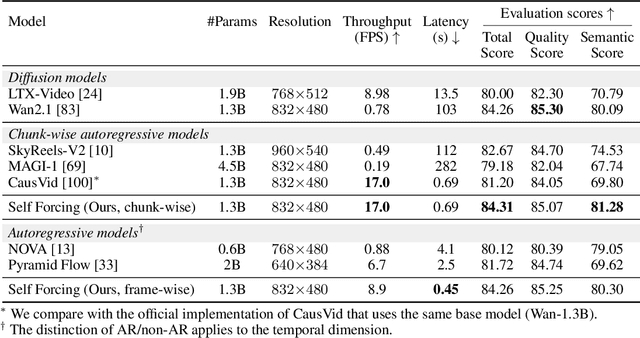
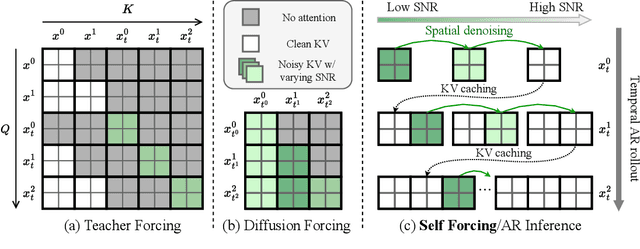
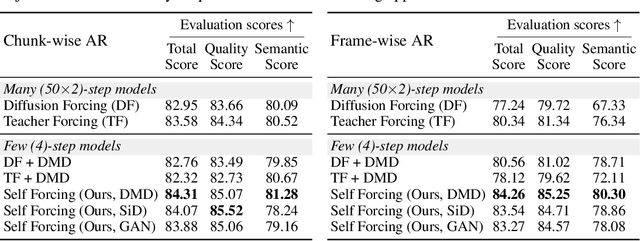
We introduce Self Forcing, a novel training paradigm for autoregressive video diffusion models. It addresses the longstanding issue of exposure bias, where models trained on ground-truth context must generate sequences conditioned on their own imperfect outputs during inference. Unlike prior methods that denoise future frames based on ground-truth context frames, Self Forcing conditions each frame's generation on previously self-generated outputs by performing autoregressive rollout with key-value (KV) caching during training. This strategy enables supervision through a holistic loss at the video level that directly evaluates the quality of the entire generated sequence, rather than relying solely on traditional frame-wise objectives. To ensure training efficiency, we employ a few-step diffusion model along with a stochastic gradient truncation strategy, effectively balancing computational cost and performance. We further introduce a rolling KV cache mechanism that enables efficient autoregressive video extrapolation. Extensive experiments demonstrate that our approach achieves real-time streaming video generation with sub-second latency on a single GPU, while matching or even surpassing the generation quality of significantly slower and non-causal diffusion models. Project website: http://self-forcing.github.io/
Can Generative Video Models Help Pose Estimation?
Dec 20, 2024Pairwise pose estimation from images with little or no overlap is an open challenge in computer vision. Existing methods, even those trained on large-scale datasets, struggle in these scenarios due to the lack of identifiable correspondences or visual overlap. Inspired by the human ability to infer spatial relationships from diverse scenes, we propose a novel approach, InterPose, that leverages the rich priors encoded within pre-trained generative video models. We propose to use a video model to hallucinate intermediate frames between two input images, effectively creating a dense, visual transition, which significantly simplifies the problem of pose estimation. Since current video models can still produce implausible motion or inconsistent geometry, we introduce a self-consistency score that evaluates the consistency of pose predictions from sampled videos. We demonstrate that our approach generalizes among three state-of-the-art video models and show consistent improvements over the state-of-the-art DUSt3R on four diverse datasets encompassing indoor, outdoor, and object-centric scenes. Our findings suggest a promising avenue for improving pose estimation models by leveraging large generative models trained on vast amounts of video data, which is more readily available than 3D data. See our project page for results: https://inter-pose.github.io/.
Stereo4D: Learning How Things Move in 3D from Internet Stereo Videos
Dec 12, 2024Learning to understand dynamic 3D scenes from imagery is crucial for applications ranging from robotics to scene reconstruction. Yet, unlike other problems where large-scale supervised training has enabled rapid progress, directly supervising methods for recovering 3D motion remains challenging due to the fundamental difficulty of obtaining ground truth annotations. We present a system for mining high-quality 4D reconstructions from internet stereoscopic, wide-angle videos. Our system fuses and filters the outputs of camera pose estimation, stereo depth estimation, and temporal tracking methods into high-quality dynamic 3D reconstructions. We use this method to generate large-scale data in the form of world-consistent, pseudo-metric 3D point clouds with long-term motion trajectories. We demonstrate the utility of this data by training a variant of DUSt3R to predict structure and 3D motion from real-world image pairs, showing that training on our reconstructed data enables generalization to diverse real-world scenes. Project page: https://stereo4d.github.io
MegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos
Dec 05, 2024



We present a system that allows for accurate, fast, and robust estimation of camera parameters and depth maps from casual monocular videos of dynamic scenes. Most conventional structure from motion and monocular SLAM techniques assume input videos that feature predominantly static scenes with large amounts of parallax. Such methods tend to produce erroneous estimates in the absence of these conditions. Recent neural network-based approaches attempt to overcome these challenges; however, such methods are either computationally expensive or brittle when run on dynamic videos with uncontrolled camera motion or unknown field of view. We demonstrate the surprising effectiveness of a deep visual SLAM framework: with careful modifications to its training and inference schemes, this system can scale to real-world videos of complex dynamic scenes with unconstrained camera paths, including videos with little camera parallax. Extensive experiments on both synthetic and real videos demonstrate that our system is significantly more accurate and robust at camera pose and depth estimation when compared with prior and concurrent work, with faster or comparable running times. See interactive results on our project page: https://mega-sam.github.io/
Shape of Motion: 4D Reconstruction from a Single Video
Jul 18, 2024



Monocular dynamic reconstruction is a challenging and long-standing vision problem due to the highly ill-posed nature of the task. Existing approaches are limited in that they either depend on templates, are effective only in quasi-static scenes, or fail to model 3D motion explicitly. In this work, we introduce a method capable of reconstructing generic dynamic scenes, featuring explicit, full-sequence-long 3D motion, from casually captured monocular videos. We tackle the under-constrained nature of the problem with two key insights: First, we exploit the low-dimensional structure of 3D motion by representing scene motion with a compact set of SE3 motion bases. Each point's motion is expressed as a linear combination of these bases, facilitating soft decomposition of the scene into multiple rigidly-moving groups. Second, we utilize a comprehensive set of data-driven priors, including monocular depth maps and long-range 2D tracks, and devise a method to effectively consolidate these noisy supervisory signals, resulting in a globally consistent representation of the dynamic scene. Experiments show that our method achieves state-of-the-art performance for both long-range 3D/2D motion estimation and novel view synthesis on dynamic scenes. Project Page: https://shape-of-motion.github.io/
Streetscapes: Large-scale Consistent Street View Generation Using Autoregressive Video Diffusion
Jul 18, 2024



We present a method for generating Streetscapes-long sequences of views through an on-the-fly synthesized city-scale scene. Our generation is conditioned by language input (e.g., city name, weather), as well as an underlying map/layout hosting the desired trajectory. Compared to recent models for video generation or 3D view synthesis, our method can scale to much longer-range camera trajectories, spanning several city blocks, while maintaining visual quality and consistency. To achieve this goal, we build on recent work on video diffusion, used within an autoregressive framework that can easily scale to long sequences. In particular, we introduce a new temporal imputation method that prevents our autoregressive approach from drifting from the distribution of realistic city imagery. We train our Streetscapes system on a compelling source of data-posed imagery from Google Street View, along with contextual map data-which allows users to generate city views conditioned on any desired city layout, with controllable camera poses. Please see more results at our project page at https://boyangdeng.com/streetscapes.
Generative Image Dynamics
Sep 14, 2023



We present an approach to modeling an image-space prior on scene dynamics. Our prior is learned from a collection of motion trajectories extracted from real video sequences containing natural, oscillating motion such as trees, flowers, candles, and clothes blowing in the wind. Given a single image, our trained model uses a frequency-coordinated diffusion sampling process to predict a per-pixel long-term motion representation in the Fourier domain, which we call a neural stochastic motion texture. This representation can be converted into dense motion trajectories that span an entire video. Along with an image-based rendering module, these trajectories can be used for a number of downstream applications, such as turning still images into seamlessly looping dynamic videos, or allowing users to realistically interact with objects in real pictures.
Tracking Everything Everywhere All at Once
Jun 08, 2023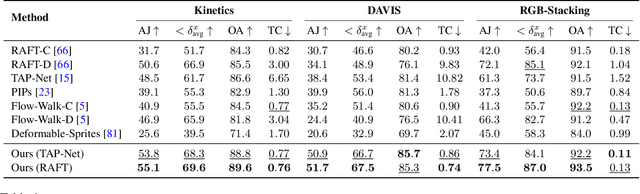
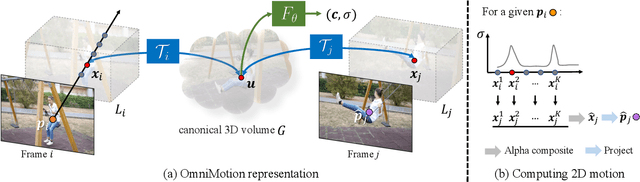
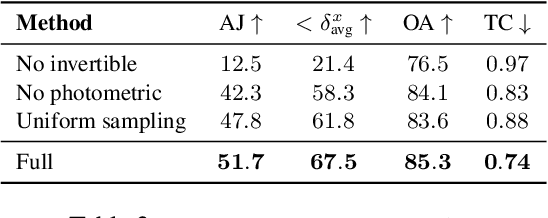

We present a new test-time optimization method for estimating dense and long-range motion from a video sequence. Prior optical flow or particle video tracking algorithms typically operate within limited temporal windows, struggling to track through occlusions and maintain global consistency of estimated motion trajectories. We propose a complete and globally consistent motion representation, dubbed OmniMotion, that allows for accurate, full-length motion estimation of every pixel in a video. OmniMotion represents a video using a quasi-3D canonical volume and performs pixel-wise tracking via bijections between local and canonical space. This representation allows us to ensure global consistency, track through occlusions, and model any combination of camera and object motion. Extensive evaluations on the TAP-Vid benchmark and real-world footage show that our approach outperforms prior state-of-the-art methods by a large margin both quantitatively and qualitatively. See our project page for more results: http://omnimotion.github.io/