 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Multi-Site Multi-Sequence Brain MRI Harmonization Enriched by Biomedical Semantic Style
Jan 13, 2026Aggregating multi-site brain MRI data can enhance deep learning model training, but also introduces non-biological heterogeneity caused by site-specific variations (e.g., differences in scanner vendors, acquisition parameters, and imaging protocols) that can undermine generalizability. Recent retrospective MRI harmonization seeks to reduce such site effects by standardizing image style (e.g., intensity, contrast, noise patterns) while preserving anatomical content. However, existing methods often rely on limited paired traveling-subject data or fail to effectively disentangle style from anatomy. Furthermore, most current approaches address only single-sequence harmonization, restricting their use in real-world settings where multi-sequence MRI is routinely acquired. To this end, we introduce MMH, a unified framework for multi-site multi-sequence brain MRI harmonization that leverages biomedical semantic priors for sequence-aware style alignment. MMH operates in two stages: (1) a diffusion-based global harmonizer that maps MR images to a sequence-specific unified domain using style-agnostic gradient conditioning, and (2) a target-specific fine-tuner that adapts globally aligned images to desired target domains. A tri-planar attention BiomedCLIP encoder aggregates multi-view embeddings to characterize volumetric style information, allowing explicit disentanglement of image styles from anatomy without requiring paired data. Evaluations on 4,163 T1- and T2-weighted MRIs demonstrate MMH's superior harmonization over state-of-the-art methods in image feature clustering, voxel-level comparison, tissue segmentation, and downstream age and site classification.
OpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
Federated Multi-Task Clustering
Dec 30, 2025Spectral clustering has emerged as one of the most effective clustering algorithms due to its superior performance. However, most existing models are designed for centralized settings, rendering them inapplicable in modern decentralized environments. Moreover, current federated learning approaches often suffer from poor generalization performance due to reliance on unreliable pseudo-labels, and fail to capture the latent correlations amongst heterogeneous clients. To tackle these limitations, this paper proposes a novel framework named Federated Multi-Task Clustering (i.e.,FMTC), which intends to learn personalized clustering models for heterogeneous clients while collaboratively leveraging their shared underlying structure in a privacy-preserving manner. More specifically, the FMTC framework is composed of two main components: client-side personalized clustering module, which learns a parameterized mapping model to support robust out-of-sample inference, bypassing the need for unreliable pseudo-labels; and server-side tensorial correlation module, which explicitly captures the shared knowledge across all clients. This is achieved by organizing all client models into a unified tensor and applying a low-rank regularization to discover their common subspace. To solve this joint optimization problem, we derive an efficient, privacy-preserving distributed algorithm based on the Alternating Direction Method of Multipliers, which decomposes the global problem into parallel local updates on clients and an aggregation step on the server. To the end, several extensive experiments on multiple real-world datasets demonstrate that our proposed FMTC framework significantly outperforms various baseline and state-of-the-art federated clustering algorithms.
E-RayZer: Self-supervised 3D Reconstruction as Spatial Visual Pre-training
Dec 11, 2025



Self-supervised pre-training has revolutionized foundation models for languages, individual 2D images and videos, but remains largely unexplored for learning 3D-aware representations from multi-view images. In this paper, we present E-RayZer, a self-supervised large 3D Vision model that learns truly 3D-aware representations directly from unlabeled images. Unlike prior self-supervised methods such as RayZer that infer 3D indirectly through latent-space view synthesis, E-RayZer operates directly in 3D space, performing self-supervised 3D reconstruction with Explicit geometry. This formulation eliminates shortcut solutions and yields representations that are geometrically grounded. To ensure convergence and scalability, we introduce a novel fine-grained learning curriculum that organizes training from easy to hard samples and harmonizes heterogeneous data sources in an entirely unsupervised manner. Experiments demonstrate that E-RayZer significantly outperforms RayZer on pose estimation, matches or sometimes surpasses fully supervised reconstruction models such as VGGT. Furthermore, its learned representations outperform leading visual pre-training models (e.g., DINOv3, CroCo v2, VideoMAE V2, and RayZer) when transferring to 3D downstream tasks, establishing E-RayZer as a new paradigm for 3D-aware visual pre-training.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
Learning from Heterogeneous Structural MRI via Collaborative Domain Adaptation for Late-Life Depression Assessment
Jul 30, 2025Accurate identification of late-life depression (LLD) using structural brain MRI is essential for monitoring disease progression and facilitating timely intervention. However, existing learning-based approaches for LLD detection are often constrained by limited sample sizes (e.g., tens), which poses significant challenges for reliable model training and generalization. Although incorporating auxiliary datasets can expand the training set, substantial domain heterogeneity, such as differences in imaging protocols, scanner hardware, and population demographics, often undermines cross-domain transferability. To address this issue, we propose a Collaborative Domain Adaptation (CDA) framework for LLD detection using T1-weighted MRIs. The CDA leverages a Vision Transformer (ViT) to capture global anatomical context and a Convolutional Neural Network (CNN) to extract local structural features, with each branch comprising an encoder and a classifier. The CDA framework consists of three stages: (a) supervised training on labeled source data, (b) self-supervised target feature adaptation and (c) collaborative training on unlabeled target data. We first train ViT and CNN on source data, followed by self-supervised target feature adaptation by minimizing the discrepancy between classifier outputs from two branches to make the categorical boundary clearer. The collaborative training stage employs pseudo-labeled and augmented target-domain MRIs, enforcing prediction consistency under strong and weak augmentation to enhance domain robustness and generalization. Extensive experiments conducted on multi-site T1-weighted MRI data demonstrate that the CDA consistently outperforms state-of-the-art unsupervised domain adaptation methods.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
DreamLight: Towards Harmonious and Consistent Image Relighting
Jun 17, 2025We introduce a model named DreamLight for universal image relighting in this work, which can seamlessly composite subjects into a new background while maintaining aesthetic uniformity in terms of lighting and color tone. The background can be specified by natural images (image-based relighting) or generated from unlimited text prompts (text-based relighting). Existing studies primarily focus on image-based relighting, while with scant exploration into text-based scenarios. Some works employ intricate disentanglement pipeline designs relying on environment maps to provide relevant information, which grapples with the expensive data cost required for intrinsic decomposition and light source. Other methods take this task as an image translation problem and perform pixel-level transformation with autoencoder architecture. While these methods have achieved decent harmonization effects, they struggle to generate realistic and natural light interaction effects between the foreground and background. To alleviate these challenges, we reorganize the input data into a unified format and leverage the semantic prior provided by the pretrained diffusion model to facilitate the generation of natural results. Moreover, we propose a Position-Guided Light Adapter (PGLA) that condenses light information from different directions in the background into designed light query embeddings, and modulates the foreground with direction-biased masked attention. In addition, we present a post-processing module named Spectral Foreground Fixer (SFF) to adaptively reorganize different frequency components of subject and relighted background, which helps enhance the consistency of foreground appearance. Extensive comparisons and user study demonstrate that our DreamLight achieves remarkable relighting performance.
OneRec Technical Report
Jun 16, 2025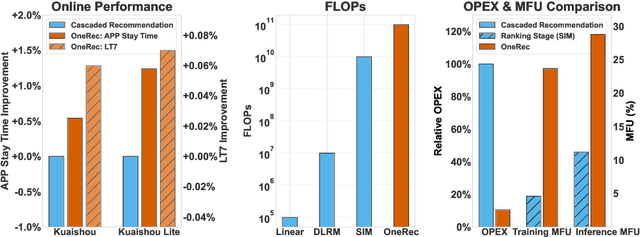

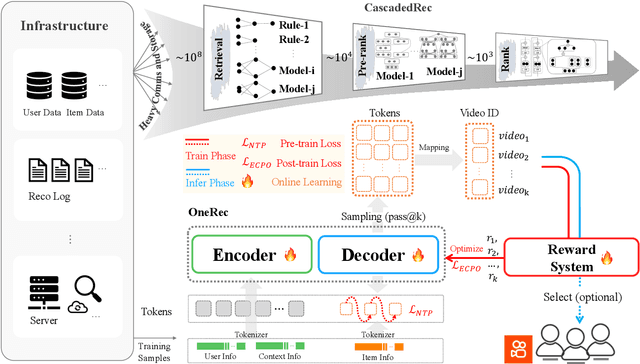

Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
St4RTrack: Simultaneous 4D Reconstruction and Tracking in the World
Apr 17, 2025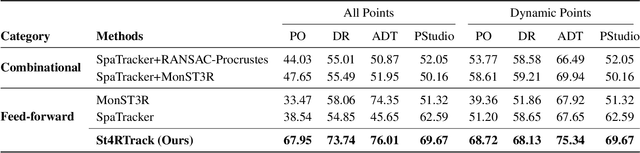
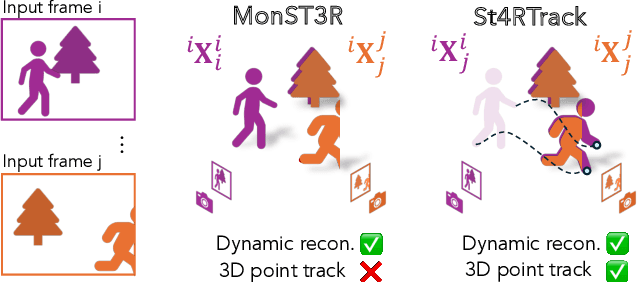
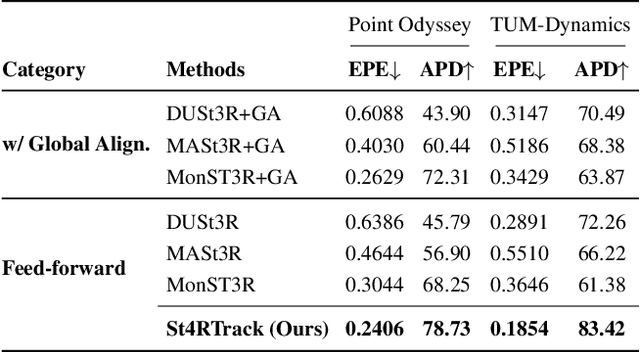
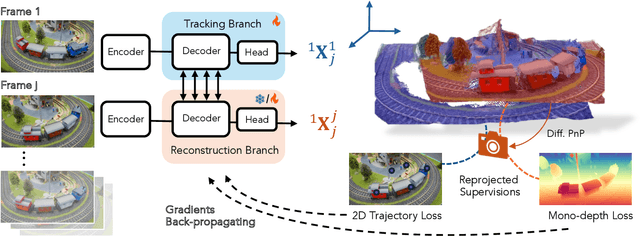
Dynamic 3D reconstruction and point tracking in videos are typically treated as separate tasks, despite their deep connection. We propose St4RTrack, a feed-forward framework that simultaneously reconstructs and tracks dynamic video content in a world coordinate frame from RGB inputs. This is achieved by predicting two appropriately defined pointmaps for a pair of frames captured at different moments. Specifically, we predict both pointmaps at the same moment, in the same world, capturing both static and dynamic scene geometry while maintaining 3D correspondences. Chaining these predictions through the video sequence with respect to a reference frame naturally computes long-range correspondences, effectively combining 3D reconstruction with 3D tracking. Unlike prior methods that rely heavily on 4D ground truth supervision, we employ a novel adaptation scheme based on a reprojection loss. We establish a new extensive benchmark for world-frame reconstruction and tracking, demonstrating the effectiveness and efficiency of our unified, data-driven framework. Our code, model, and benchmark will be released.