 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment Any Motion in Videos
Mar 28, 2025Moving object segmentation is a crucial task for achieving a high-level understanding of visual scenes and has numerous downstream applications. Humans can effortlessly segment moving objects in videos. Previous work has largely relied on optical flow to provide motion cues; however, this approach often results in imperfect predictions due to challenges such as partial motion, complex deformations, motion blur and background distractions. We propose a novel approach for moving object segmentation that combines long-range trajectory motion cues with DINO-based semantic features and leverages SAM2 for pixel-level mask densification through an iterative prompting strategy. Our model employs Spatio-Temporal Trajectory Attention and Motion-Semantic Decoupled Embedding to prioritize motion while integrating semantic support. Extensive testing on diverse datasets demonstrates state-of-the-art performance, excelling in challenging scenarios and fine-grained segmentation of multiple objects. Our code is available at https://motion-seg.github.io/.
EMD: Explicit Motion Modeling for High-Quality Street Gaussian Splatting
Nov 23, 2024



Photorealistic reconstruction of street scenes is essential for developing real-world simulators in autonomous driving. While recent methods based on 3D/4D Gaussian Splatting (GS) have demonstrated promising results, they still encounter challenges in complex street scenes due to the unpredictable motion of dynamic objects. Current methods typically decompose street scenes into static and dynamic objects, learning the Gaussians in either a supervised manner (e.g., w/ 3D bounding-box) or a self-supervised manner (e.g., w/o 3D bounding-box). However, these approaches do not effectively model the motions of dynamic objects (e.g., the motion speed of pedestrians is clearly different from that of vehicles), resulting in suboptimal scene decomposition. To address this, we propose Explicit Motion Decomposition (EMD), which models the motions of dynamic objects by introducing learnable motion embeddings to the Gaussians, enhancing the decomposition in street scenes. The proposed EMD is a plug-and-play approach applicable to various baseline methods. We also propose tailored training strategies to apply EMD to both supervised and self-supervised baselines. Through comprehensive experimentation, we illustrate the effectiveness of our approach with various established baselines. The code will be released at: https://qingpowuwu.github.io/emdgaussian.github.io/.
Repurposing Foundation Model for Generalizable Medical Time Series Classification
Oct 03, 2024



Medical time series (MedTS) classification is critical for a wide range of healthcare applications such as Alzheimer's Disease diagnosis. However, its real-world deployment is severely challenged by poor generalizability due to inter- and intra-dataset heterogeneity in MedTS, including variations in channel configurations, time series lengths, and diagnostic tasks. Here, we propose FORMED, a foundation classification model that leverages a pre-trained backbone and tackles these challenges through re-purposing. FORMED integrates the general representation learning enabled by the backbone foundation model and the medical domain knowledge gained on a curated cohort of MedTS datasets. FORMED can adapt seamlessly to unseen MedTS datasets, regardless of the number of channels, sample lengths, or medical tasks. Experimental results show that, without any task-specific adaptation, the repurposed FORMED achieves performance that is competitive with, and often superior to, 11 baseline models trained specifically for each dataset. Furthermore, FORMED can effectively adapt to entirely new, unseen datasets, with lightweight parameter updates, consistently outperforming baselines. Our results highlight FORMED as a versatile and scalable model for a wide range of MedTS classification tasks, positioning it as a strong foundation model for future research in MedTS analysis.
$\textit{S}^3$Gaussian: Self-Supervised Street Gaussians for Autonomous Driving
May 30, 2024



Photorealistic 3D reconstruction of street scenes is a critical technique for developing real-world simulators for autonomous driving. Despite the efficacy of Neural Radiance Fields (NeRF) for driving scenes, 3D Gaussian Splatting (3DGS) emerges as a promising direction due to its faster speed and more explicit representation. However, most existing street 3DGS methods require tracked 3D vehicle bounding boxes to decompose the static and dynamic elements for effective reconstruction, limiting their applications for in-the-wild scenarios. To facilitate efficient 3D scene reconstruction without costly annotations, we propose a self-supervised street Gaussian ($\textit{S}^3$Gaussian) method to decompose dynamic and static elements from 4D consistency. We represent each scene with 3D Gaussians to preserve the explicitness and further accompany them with a spatial-temporal field network to compactly model the 4D dynamics. We conduct extensive experiments on the challenging Waymo-Open dataset to evaluate the effectiveness of our method. Our $\textit{S}^3$Gaussian demonstrates the ability to decompose static and dynamic scenes and achieves the best performance without using 3D annotations. Code is available at: https://github.com/nnanhuang/S3Gaussian/.
Medformer: A Multi-Granularity Patching Transformer for Medical Time-Series Classification
May 24, 2024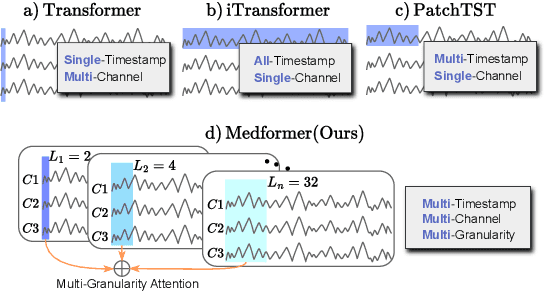
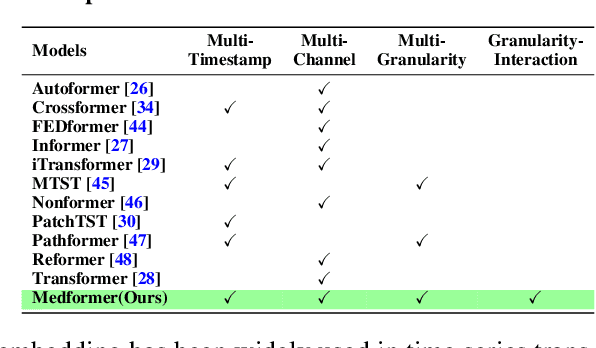
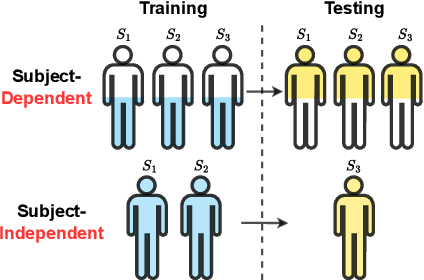
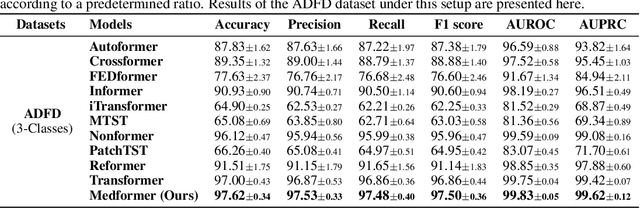
Medical time series data, such as Electroencephalography (EEG) and Electrocardiography (ECG), play a crucial role in healthcare, such as diagnosing brain and heart diseases. Existing methods for medical time series classification primarily rely on handcrafted biomarkers extraction and CNN-based models, with limited exploration of transformers tailored for medical time series. In this paper, we introduce Medformer, a multi-granularity patching transformer tailored specifically for medical time series classification. Our method incorporates three novel mechanisms to leverage the unique characteristics of medical time series: cross-channel patching to leverage inter-channel correlations, multi-granularity embedding for capturing features at different scales, and two-stage (intra- and inter-granularity) multi-granularity self-attention for learning features and correlations within and among granularities. We conduct extensive experiments on five public datasets under both subject-dependent and challenging subject-independent setups. Results demonstrate Medformer's superiority over 10 baselines, achieving top averaged ranking across five datasets on all six evaluation metrics. These findings underscore the significant impact of our method on healthcare applications, such as diagnosing Myocardial Infarction, Alzheimer's, and Parkinson's disease. We release the source code at \url{https://github.com/DL4mHealth/Medformer}.
UnitNorm: Rethinking Normalization for Transformers in Time Series
May 24, 2024Normalization techniques are crucial for enhancing Transformer models' performance and stability in time series analysis tasks, yet traditional methods like batch and layer normalization often lead to issues such as token shift, attention shift, and sparse attention. We propose UnitNorm, a novel approach that scales input vectors by their norms and modulates attention patterns, effectively circumventing these challenges. Grounded in existing normalization frameworks, UnitNorm's effectiveness is demonstrated across diverse time series analysis tasks, including forecasting, classification, and anomaly detection, via a rigorous evaluation on 6 state-of-the-art models and 10 datasets. Notably, UnitNorm shows superior performance, especially in scenarios requiring robust attention mechanisms and contextual comprehension, evidenced by significant improvements by up to a 1.46 decrease in MSE for forecasting, and a 4.89% increase in accuracy for classification. This work not only calls for a reevaluation of normalization strategies in time series Transformers but also sets a new direction for enhancing model performance and stability. The source code is available at https://anonymous.4open.science/r/UnitNorm-5B84.
Customize-It-3D: High-Quality 3D Creation from A Single Image Using Subject-Specific Knowledge Prior
Dec 15, 2023



In this paper, we present a novel two-stage approach that fully utilizes the information provided by the reference image to establish a customized knowledge prior for image-to-3D generation. While previous approaches primarily rely on a general diffusion prior, which struggles to yield consistent results with the reference image, we propose a subject-specific and multi-modal diffusion model. This model not only aids NeRF optimization by considering the shading mode for improved geometry but also enhances texture from the coarse results to achieve superior refinement. Both aspects contribute to faithfully aligning the 3D content with the subject. Extensive experiments showcase the superiority of our method, Customize-It-3D, outperforming previous works by a substantial margin. It produces faithful 360-degree reconstructions with impressive visual quality, making it well-suited for various applications, including text-to-3D creation.
Time-Frequency Mask Aware Bi-directional LSTM: A Deep Learning Approach for Underwater Acoustic Signal Separation
Feb 09, 2022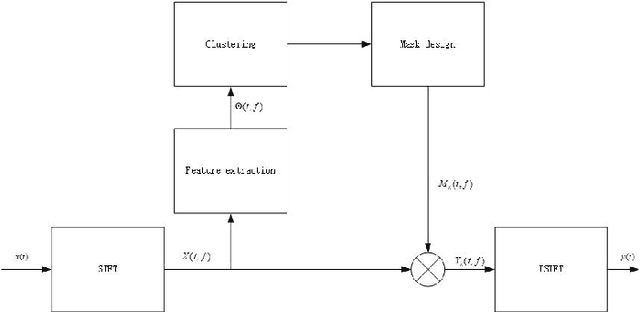

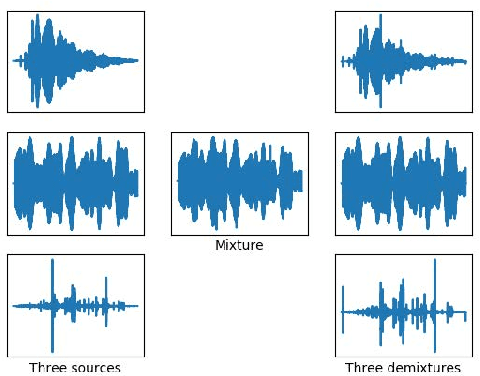
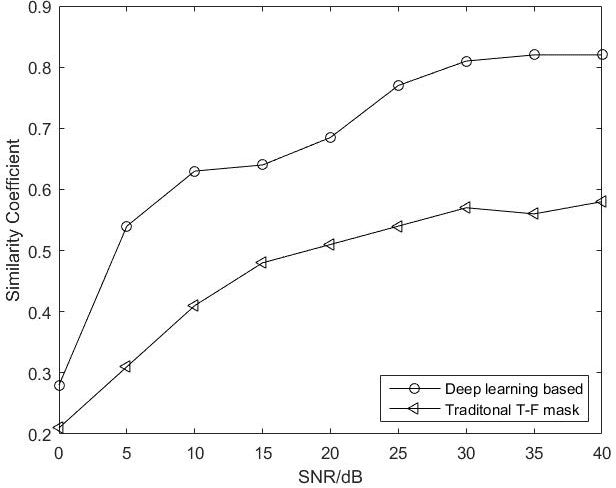
The underwater acoustic signals separation is a key technique for the underwater communications. The existing methods are mostly model-based, and could not accurately characterise the practical underwater acoustic communication environment. They are only suitable for binary signal separation, but cannot handle multivariate signal separation. On the other hand, the recurrent neural network (RNN) shows powerful capability in extracting the features of the temporal sequences. Inspired by this, in this paper, we present a data-driven approach for underwater acoustic signals separation using deep learning technology. We use the Bi-directional Long Short-Term Memory (Bi-LSTM) to explore the features of Time-Frequency (T-F) mask, and propose a T-F mask aware Bi-LSTM for signal separation. Taking advantage of the sparseness of the T-F image, the designed Bi-LSTM network is able to extract the discriminative features for separation, which further improves the separation performance. In particular, this method breaks through the limitations of the existing methods, not only achieves good results in multivariate separation, but also effectively separates signals when mixed with 40dB Gaussian noise signals. The experimental results show that this method can achieve a $97\%$ guarantee ratio (PSR), and the average similarity coefficient of the multivariate signal separation is stable above 0.8 under high noise conditions.