 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking ERP Analysis: Manual Features, Deep Learning, and Foundation Models
Jan 02, 2026Event-related potential (ERP), a specialized paradigm of electroencephalographic (EEG), reflects neurological responses to external stimuli or events, generally associated with the brain's processing of specific cognitive tasks. ERP plays a critical role in cognitive analysis, the detection of neurological diseases, and the assessment of psychological states. Recent years have seen substantial advances in deep learning-based methods for spontaneous EEG and other non-time-locked task-related EEG signals. However, their effectiveness on ERP data remains underexplored, and many existing ERP studies still rely heavily on manually extracted features. In this paper, we conduct a comprehensive benchmark study that systematically compares traditional manual features (followed by a linear classifier), deep learning models, and pre-trained EEG foundation models for ERP analysis. We establish a unified data preprocessing and training pipeline and evaluate these approaches on two representative tasks, ERP stimulus classification and ERP-based brain disease detection, across 12 publicly available datasets. Furthermore, we investigate various patch-embedding strategies within advanced Transformer architectures to identify embedding designs that better suit ERP data. Our study provides a landmark framework to guide method selection and tailored model design for future ERP analysis. The code is available at https://github.com/DL4mHealth/ERP-Benchmark.
Medformer: A Multi-Granularity Patching Transformer for Medical Time-Series Classification
May 24, 2024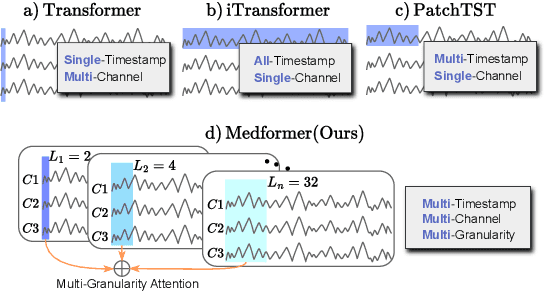
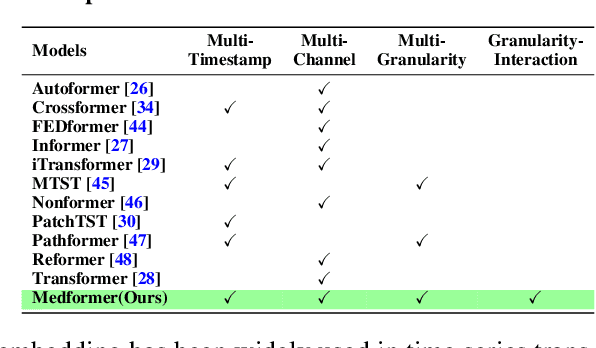
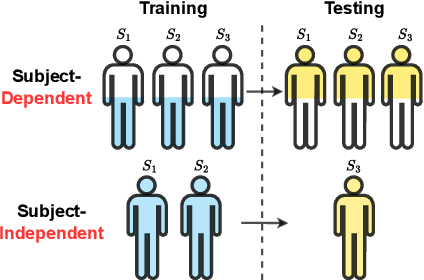
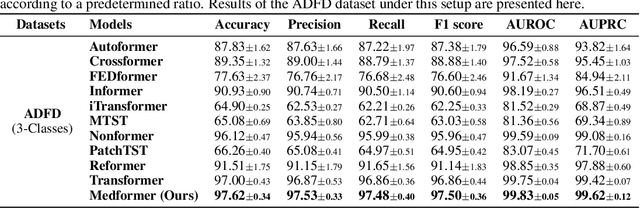
Medical time series data, such as Electroencephalography (EEG) and Electrocardiography (ECG), play a crucial role in healthcare, such as diagnosing brain and heart diseases. Existing methods for medical time series classification primarily rely on handcrafted biomarkers extraction and CNN-based models, with limited exploration of transformers tailored for medical time series. In this paper, we introduce Medformer, a multi-granularity patching transformer tailored specifically for medical time series classification. Our method incorporates three novel mechanisms to leverage the unique characteristics of medical time series: cross-channel patching to leverage inter-channel correlations, multi-granularity embedding for capturing features at different scales, and two-stage (intra- and inter-granularity) multi-granularity self-attention for learning features and correlations within and among granularities. We conduct extensive experiments on five public datasets under both subject-dependent and challenging subject-independent setups. Results demonstrate Medformer's superiority over 10 baselines, achieving top averaged ranking across five datasets on all six evaluation metrics. These findings underscore the significant impact of our method on healthcare applications, such as diagnosing Myocardial Infarction, Alzheimer's, and Parkinson's disease. We release the source code at \url{https://github.com/DL4mHealth/Medformer}.
Design and Visual Servoing Control of a Hybrid Dual-Segment Flexible Neurosurgical Robot for Intraventricular Biopsy
Feb 23, 2024



Traditional rigid endoscopes have challenges in flexibly treating tumors located deep in the brain, and low operability and fixed viewing angles limit its development. This study introduces a novel dual-segment flexible robotic endoscope MicroNeuro, designed to perform biopsies with dexterous surgical manipulation deep in the brain. Taking into account the uncertainty of the control model, an image-based visual servoing with online robot Jacobian estimation has been implemented to enhance motion accuracy. Furthermore, the application of model predictive control with constraints significantly bolsters the flexible robot's ability to adaptively track mobile objects and resist external interference. Experimental results underscore that the proposed control system enhances motion stability and precision. Phantom testing substantiates its considerable potential for deployment in neurosurgery.
Contrast Everything: A Hierarchical Contrastive Framework for Medical Time-Series
Oct 28, 2023Contrastive representation learning is crucial in medical time series analysis as it alleviates dependency on labor-intensive, domain-specific, and scarce expert annotations. However, existing contrastive learning methods primarily focus on one single data level, which fails to fully exploit the intricate nature of medical time series. To address this issue, we present COMET, an innovative hierarchical framework that leverages data consistencies at all inherent levels in medical time series. Our meticulously designed model systematically captures data consistency from four potential levels: observation, sample, trial, and patient levels. By developing contrastive loss at multiple levels, we can learn effective representations that preserve comprehensive data consistency, maximizing information utilization in a self-supervised manner. We conduct experiments in the challenging patient-independent setting. We compare COMET against six baselines using three diverse datasets, which include ECG signals for myocardial infarction and EEG signals for Alzheimer's and Parkinson's diseases. The results demonstrate that COMET consistently outperforms all baselines, particularly in setup with 10% and 1% labeled data fractions across all datasets. These results underscore the significant impact of our framework in advancing contrastive representation learning techniques for medical time series. The source code is available at https://github.com/DL4mHealth/COMET.
* Accepted by NeurIPS 2023; 24pages (13 pages main paper + 11 pages supplementary materials)
Large Language Models are Pretty Good Zero-Shot Video Game Bug Detectors
Oct 05, 2022


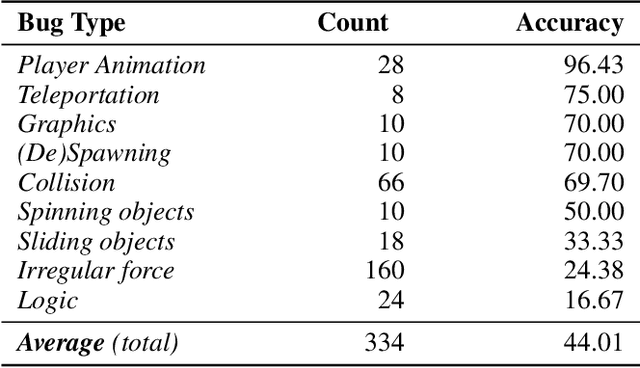
Video game testing requires game-specific knowledge as well as common sense reasoning about the events in the game. While AI-driven agents can satisfy the first requirement, it is not yet possible to meet the second requirement automatically. Therefore, video game testing often still relies on manual testing, and human testers are required to play the game thoroughly to detect bugs. As a result, it is challenging to fully automate game testing. In this study, we explore the possibility of leveraging the zero-shot capabilities of large language models for video game bug detection. By formulating the bug detection problem as a question-answering task, we show that large language models can identify which event is buggy in a sequence of textual descriptions of events from a game. To this end, we introduce the GameBugDescriptions benchmark dataset, which consists of 167 buggy gameplay videos and a total of 334 question-answer pairs across 8 games. We extensively evaluate the performance of six models across the OPT and InstructGPT large language model families on our benchmark dataset. Our results show promising results for employing language models to detect video game bugs. With the proper prompting technique, we could achieve an accuracy of 70.66%, and on some video games, up to 78.94%. Our code, evaluation data and the benchmark can be found on https://asgaardlab.github.io/LLMxBugs
Pan More Gold from the Sand: Refining Open-domain Dialogue Training with Noisy Self-Retrieval Generation
Jan 27, 2022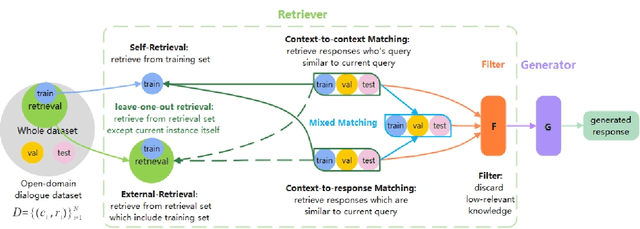
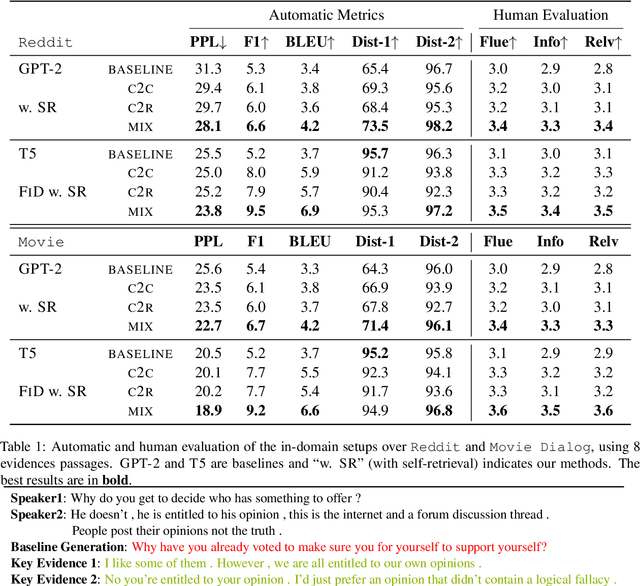
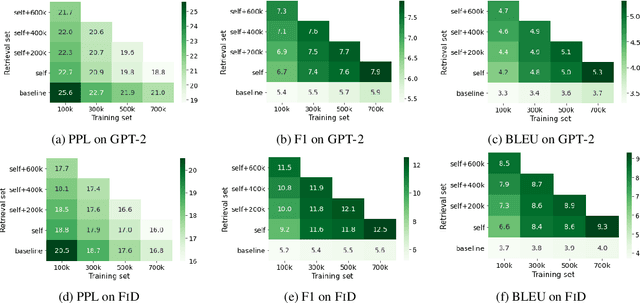
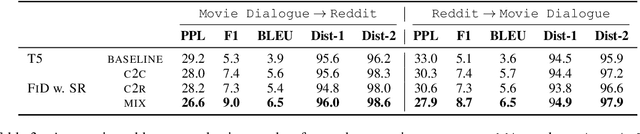
Real human conversation data are complicated, heterogeneous, and noisy, from whom building open-domain dialogue systems remains a challenging task. In fact, such dialogue data can still contain a wealth of information and knowledge, however, they are not fully explored. In this paper, we show existing open-domain dialogue generation methods by memorizing context-response paired data with causal or encode-decode language models underutilize the training data. Different from current approaches, using external knowledge, we explore a retrieval-generation training framework that can increase the usage of training data by directly considering the heterogeneous and noisy training data as the "evidence". Experiments over publicly available datasets demonstrate that our method can help models generate better responses, even such training data are usually impressed as low-quality data. Such performance gain is comparable with those improved by enlarging the training set, even better. We also found that the model performance has a positive correlation with the relevance of the retrieved evidence. Moreover, our method performed well on zero-shot experiments, which indicates that our method can be more robust to real-world data.