 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Can VLMs Go for Visual Bug Detection? Studying 19,738 Keyframes from 41 Hours of Gameplay Videos
Mar 24, 2026Video-based quality assurance (QA) for long-form gameplay video is labor-intensive and error-prone, yet valuable for assessing game stability and visual correctness over extended play sessions. Vision language models (VLMs) promise general-purpose visual reasoning capabilities and thus appear attractive for detecting visual bugs directly from video frames. Recent benchmarks suggest that VLMs can achieve promising results in detecting visual glitches on curated datasets. Building on these findings, we conduct a real-world study using industrial QA gameplay videos to evaluate how well VLMs perform in practical scenarios. Our study samples keyframes from long gameplay videos and asks a VLM whether each keyframe contains a bug. Starting from a single-prompt baseline, the model achieves a precision of 0.50 and an accuracy of 0.72. We then examine two common enhancement strategies used to improve VLM performance without fine-tuning: (1) a secondary judge model that re-evaluates VLM outputs, and (2) metadata-augmented prompting through the retrieval of prior bug reports. Across \textbf{100 videos} totaling \textbf{41 hours} and \textbf{19,738 keyframes}, these strategies provide only marginal improvements over the simple baseline, while introducing additional computational cost and output variance. Our findings indicate that off-the-shelf VLMs are already capable of detecting a certain range of visual bugs in QA gameplay videos, but further progress likely requires hybrid approaches that better separate textual and visual anomaly detection.
VideoGameQA-Bench: Evaluating Vision-Language Models for Video Game Quality Assurance
May 21, 2025With video games now generating the highest revenues in the entertainment industry, optimizing game development workflows has become essential for the sector's sustained growth. Recent advancements in Vision-Language Models (VLMs) offer considerable potential to automate and enhance various aspects of game development, particularly Quality Assurance (QA), which remains one of the industry's most labor-intensive processes with limited automation options. To accurately evaluate the performance of VLMs in video game QA tasks and determine their effectiveness in handling real-world scenarios, there is a clear need for standardized benchmarks, as existing benchmarks are insufficient to address the specific requirements of this domain. To bridge this gap, we introduce VideoGameQA-Bench, a comprehensive benchmark that covers a wide array of game QA activities, including visual unit testing, visual regression testing, needle-in-a-haystack tasks, glitch detection, and bug report generation for both images and videos of various games. Code and data are available at: https://asgaardlab.github.io/videogameqa-bench/
Software Engineering and Foundation Models: Insights from Industry Blogs Using a Jury of Foundation Models
Oct 11, 2024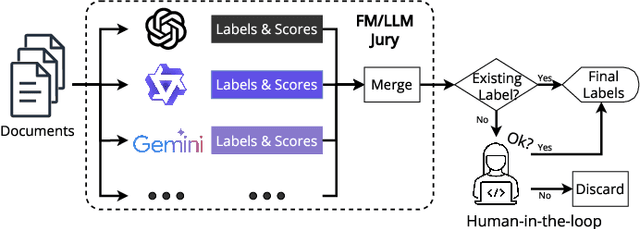
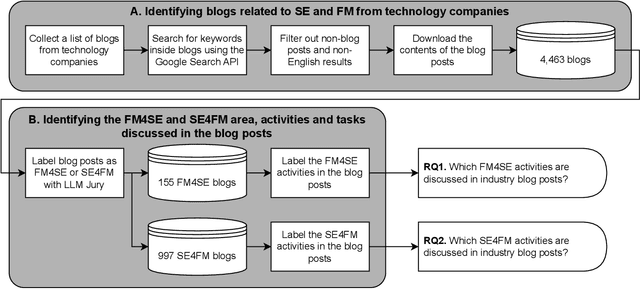

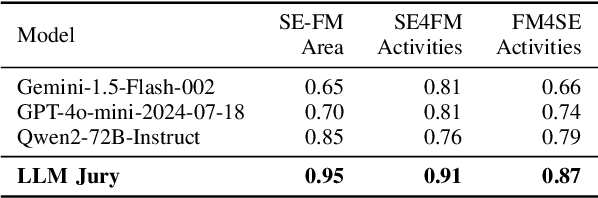
Foundation models (FMs) such as large language models (LLMs) have significantly impacted many fields, including software engineering (SE). The interaction between SE and FMs has led to the integration of FMs into SE practices (FM4SE) and the application of SE methodologies to FMs (SE4FM). While several literature surveys exist on academic contributions to these trends, we are the first to provide a practitioner's view. We analyze 155 FM4SE and 997 SE4FM blog posts from leading technology companies, leveraging an FM-powered surveying approach to systematically label and summarize the discussed activities and tasks. We observed that while code generation is the most prominent FM4SE task, FMs are leveraged for many other SE activities such as code understanding, summarization, and API recommendation. The majority of blog posts on SE4FM are about model deployment & operation, and system architecture & orchestration. Although the emphasis is on cloud deployments, there is a growing interest in compressing FMs and deploying them on smaller devices such as edge or mobile devices. We outline eight future research directions inspired by our gained insights, aiming to bridge the gap between academic findings and real-world applications. Our study not only enriches the body of knowledge on practical applications of FM4SE and SE4FM but also demonstrates the utility of FMs as a powerful and efficient approach in conducting literature surveys within technical and grey literature domains. Our dataset, results, code and used prompts can be found in our online replication package at https://github.com/SAILResearch/fmse-blogs.
VideoGameBunny: Towards vision assistants for video games
Jul 21, 2024



Large multimodal models (LMMs) hold substantial promise across various domains, from personal assistance in daily tasks to sophisticated applications like medical diagnostics. However, their capabilities have limitations in the video game domain, such as challenges with scene understanding, hallucinations, and inaccurate descriptions of video game content, especially in open-source models. This paper describes the development of VideoGameBunny, a LLaVA-style model based on Bunny, specifically tailored for understanding images from video games. We release intermediate checkpoints, training logs, and an extensive dataset comprising 185,259 video game images from 413 titles, along with 389,565 image-instruction pairs that include image captions, question-answer pairs, and a JSON representation of 16 elements of 136,974 images. Our experiments show that our high quality game-related data has the potential to make a relatively small model outperform the much larger state-of-the-art model LLaVa-1.6-34b (which has more than 4x the number of parameters). Our study paves the way for future research in video game understanding on tasks such as playing, commentary, and debugging. Code and data are available at https://videogamebunny.github.io/
Studying the Impact of TensorFlow and PyTorch Bindings on Machine Learning Software Quality
Jul 07, 2024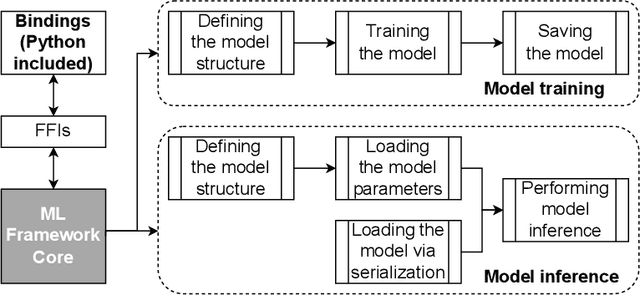
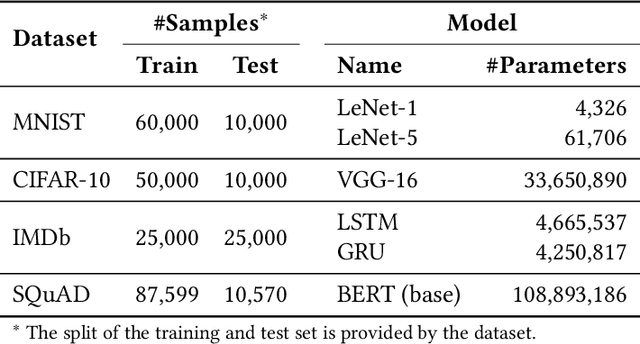
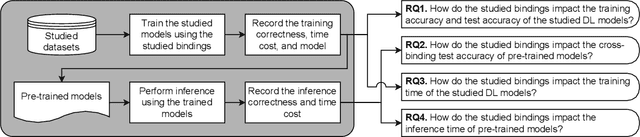
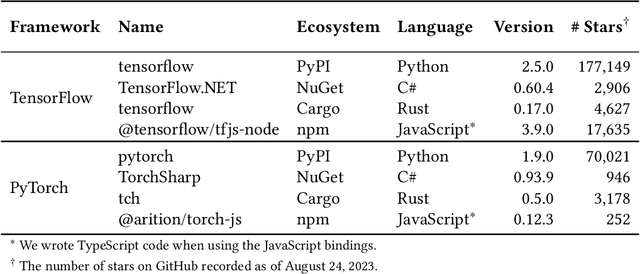
Bindings for machine learning frameworks (such as TensorFlow and PyTorch) allow developers to integrate a framework's functionality using a programming language different from the framework's default language (usually Python). In this paper, we study the impact of using TensorFlow and PyTorch bindings in C#, Rust, Python and JavaScript on the software quality in terms of correctness (training and test accuracy) and time cost (training and inference time) when training and performing inference on five widely used deep learning models. Our experiments show that a model can be trained in one binding and used for inference in another binding for the same framework without losing accuracy. Our study is the first to show that using a non-default binding can help improve machine learning software quality from the time cost perspective compared to the default Python binding while still achieving the same level of correctness.
Keeping Deep Learning Models in Check: A History-Based Approach to Mitigate Overfitting
Jan 18, 2024In software engineering, deep learning models are increasingly deployed for critical tasks such as bug detection and code review. However, overfitting remains a challenge that affects the quality, reliability, and trustworthiness of software systems that utilize deep learning models. Overfitting can be (1) prevented (e.g., using dropout or early stopping) or (2) detected in a trained model (e.g., using correlation-based approaches). Both overfitting detection and prevention approaches that are currently used have constraints (e.g., requiring modification of the model structure, and high computing resources). In this paper, we propose a simple, yet powerful approach that can both detect and prevent overfitting based on the training history (i.e., validation losses). Our approach first trains a time series classifier on training histories of overfit models. This classifier is then used to detect if a trained model is overfit. In addition, our trained classifier can be used to prevent overfitting by identifying the optimal point to stop a model's training. We evaluate our approach on its ability to identify and prevent overfitting in real-world samples. We compare our approach against correlation-based detection approaches and the most commonly used prevention approach (i.e., early stopping). Our approach achieves an F1 score of 0.91 which is at least 5% higher than the current best-performing non-intrusive overfitting detection approach. Furthermore, our approach can stop training to avoid overfitting at least 32% of the times earlier than early stopping and has the same or a better rate of returning the best model.
GlitchBench: Can large multimodal models detect video game glitches?
Dec 08, 2023


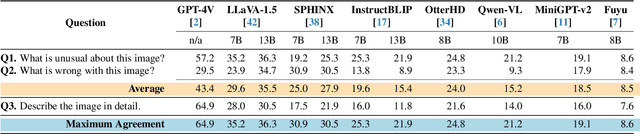
Large multimodal models (LMMs) have evolved from large language models (LLMs) to integrate multiple input modalities, such as visual inputs. This integration augments the capacity of LLMs for tasks requiring visual comprehension and reasoning. However, the extent and limitations of their enhanced abilities are not fully understood, especially when it comes to real-world tasks. To address this gap, we introduce GlitchBench, a novel benchmark derived from video game quality assurance tasks, to test and evaluate the reasoning capabilities of LMMs. Our benchmark is curated from a variety of unusual and glitched scenarios from video games and aims to challenge both the visual and linguistic reasoning powers of LMMs in detecting and interpreting out-of-the-ordinary events. We evaluate multiple state-of-the-art LMMs, and we show that GlitchBench presents a new challenge for these models. Code and data are available at: https://glitchbench.github.io/
Zoom is what you need: An empirical study of the power of zoom and spatial biases in image classification
Apr 11, 2023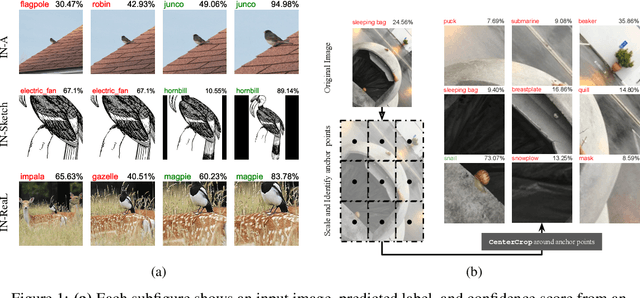

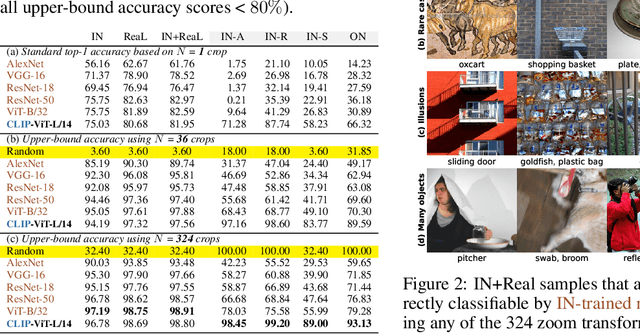

Image classifiers are information-discarding machines, by design. Yet, how these models discard information remains mysterious. We hypothesize that one way for image classifiers to reach high accuracy is to first zoom to the most discriminative region in the image and then extract features from there to predict image labels. We study six popular networks ranging from AlexNet to CLIP and find that proper framing of the input image can lead to the correct classification of 98.91% of ImageNet images. Furthermore, we explore the potential and limits of zoom transforms in image classification and uncover positional biases in various datasets, especially a strong center bias in two popular datasets: ImageNet-A and ObjectNet. Finally, leveraging our insights into the potential of zoom, we propose a state-of-the-art test-time augmentation (TTA) technique that improves classification accuracy by forcing models to explicitly perform zoom-in operations before making predictions. Our method is more interpretable, accurate, and faster than MEMO, a state-of-the-art TTA method. Additionally, we propose ImageNet-Hard, a new benchmark where zooming in alone often does not help state-of-the-art models better label images.
Large Language Models are Pretty Good Zero-Shot Video Game Bug Detectors
Oct 05, 2022


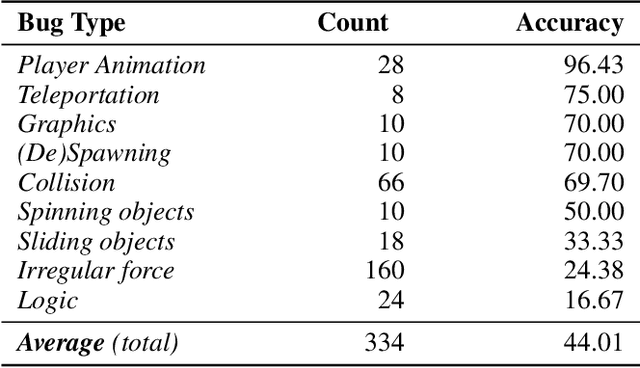
Video game testing requires game-specific knowledge as well as common sense reasoning about the events in the game. While AI-driven agents can satisfy the first requirement, it is not yet possible to meet the second requirement automatically. Therefore, video game testing often still relies on manual testing, and human testers are required to play the game thoroughly to detect bugs. As a result, it is challenging to fully automate game testing. In this study, we explore the possibility of leveraging the zero-shot capabilities of large language models for video game bug detection. By formulating the bug detection problem as a question-answering task, we show that large language models can identify which event is buggy in a sequence of textual descriptions of events from a game. To this end, we introduce the GameBugDescriptions benchmark dataset, which consists of 167 buggy gameplay videos and a total of 334 question-answer pairs across 8 games. We extensively evaluate the performance of six models across the OPT and InstructGPT large language model families on our benchmark dataset. Our results show promising results for employing language models to detect video game bugs. With the proper prompting technique, we could achieve an accuracy of 70.66%, and on some video games, up to 78.94%. Our code, evaluation data and the benchmark can be found on https://asgaardlab.github.io/LLMxBugs
CLIP meets GamePhysics: Towards bug identification in gameplay videos using zero-shot transfer learning
Mar 22, 2022
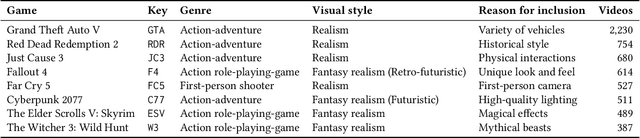

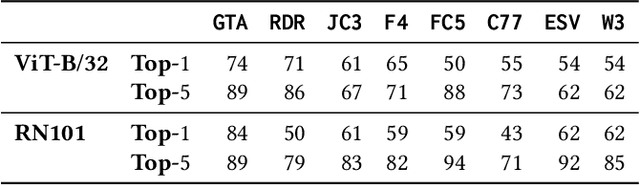
Gameplay videos contain rich information about how players interact with the game and how the game responds. Sharing gameplay videos on social media platforms, such as Reddit, has become a common practice for many players. Often, players will share gameplay videos that showcase video game bugs. Such gameplay videos are software artifacts that can be utilized for game testing, as they provide insight for bug analysis. Although large repositories of gameplay videos exist, parsing and mining them in an effective and structured fashion has still remained a big challenge. In this paper, we propose a search method that accepts any English text query as input to retrieve relevant videos from large repositories of gameplay videos. Our approach does not rely on any external information (such as video metadata); it works solely based on the content of the video. By leveraging the zero-shot transfer capabilities of the Contrastive Language-Image Pre-Training (CLIP) model, our approach does not require any data labeling or training. To evaluate our approach, we present the $\texttt{GamePhysics}$ dataset consisting of 26,954 videos from 1,873 games, that were collected from the GamePhysics section on the Reddit website. Our approach shows promising results in our extensive analysis of simple queries, compound queries, and bug queries, indicating that our approach is useful for object and event detection in gameplay videos. An example application of our approach is as a gameplay video search engine to aid in reproducing video game bugs. Please visit the following link for the code and the data: https://asgaardlab.github.io/CLIPxGamePhysics/