 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Language Models are Biased
May 29, 2025Large language models (LLMs) memorize a vast amount of prior knowledge from the Internet that help them on downstream tasks but also may notoriously sway their outputs towards wrong or biased answers. In this work, we test how the knowledge about popular subjects hurt the accuracy of vision language models (VLMs) on standard, objective visual tasks of counting and identification. We find that state-of-the-art VLMs are strongly biased (e.g, unable to recognize a fourth stripe has been added to a 3-stripe Adidas logo) scoring an average of 17.05% accuracy in counting (e.g., counting stripes in an Adidas-like logo) across 7 diverse domains from animals, logos, chess, board games, optical illusions, to patterned grids. Insert text (e.g., "Adidas") describing the subject name into the counterfactual image further decreases VLM accuracy. The biases in VLMs are so strong that instructing them to double-check their results or rely exclusively on image details to answer improves counting accuracy by only +2 points, on average. Our work presents an interesting failure mode in VLMs and an automated framework for testing VLM biases. Code and data are available at: vlmsarebiased.github.io.
B-score: Detecting biases in large language models using response history
May 24, 2025Large language models (LLMs) often exhibit strong biases, e.g, against women or in favor of the number 7. We investigate whether LLMs would be able to output less biased answers when allowed to observe their prior answers to the same question in a multi-turn conversation. To understand which types of questions invite more biased answers, we test LLMs on our proposed set of questions that span 9 topics and belong to three types: (1) Subjective; (2) Random; and (3) Objective. Interestingly, LLMs are able to "de-bias" themselves in a multi-turn conversation in response to questions that seek an Random, unbiased answer. Furthermore, we propose B-score, a novel metric that is effective in detecting biases to Subjective, Random, Easy, and Hard questions. On MMLU, HLE, and CSQA, leveraging B-score substantially improves the verification accuracy of LLM answers (i.e, accepting LLM correct answers and rejecting incorrect ones) compared to using verbalized confidence scores or the frequency of single-turn answers alone. Code and data are available at: https://b-score.github.io.
Understanding Generative AI Capabilities in Everyday Image Editing Tasks
May 22, 2025Generative AI (GenAI) holds significant promise for automating everyday image editing tasks, especially following the recent release of GPT-4o on March 25, 2025. However, what subjects do people most often want edited? What kinds of editing actions do they want to perform (e.g., removing or stylizing the subject)? Do people prefer precise edits with predictable outcomes or highly creative ones? By understanding the characteristics of real-world requests and the corresponding edits made by freelance photo-editing wizards, can we draw lessons for improving AI-based editors and determine which types of requests can currently be handled successfully by AI editors? In this paper, we present a unique study addressing these questions by analyzing 83k requests from the past 12 years (2013-2025) on the Reddit community, which collected 305k PSR-wizard edits. According to human ratings, approximately only 33% of requests can be fulfilled by the best AI editors (including GPT-4o, Gemini-2.0-Flash, SeedEdit). Interestingly, AI editors perform worse on low-creativity requests that require precise editing than on more open-ended tasks. They often struggle to preserve the identity of people and animals, and frequently make non-requested touch-ups. On the other side of the table, VLM judges (e.g., o1) perform differently from human judges and may prefer AI edits more than human edits. Code and qualitative examples are available at: https://psrdataset.github.io
VideoGameQA-Bench: Evaluating Vision-Language Models for Video Game Quality Assurance
May 21, 2025With video games now generating the highest revenues in the entertainment industry, optimizing game development workflows has become essential for the sector's sustained growth. Recent advancements in Vision-Language Models (VLMs) offer considerable potential to automate and enhance various aspects of game development, particularly Quality Assurance (QA), which remains one of the industry's most labor-intensive processes with limited automation options. To accurately evaluate the performance of VLMs in video game QA tasks and determine their effectiveness in handling real-world scenarios, there is a clear need for standardized benchmarks, as existing benchmarks are insufficient to address the specific requirements of this domain. To bridge this gap, we introduce VideoGameQA-Bench, a comprehensive benchmark that covers a wide array of game QA activities, including visual unit testing, visual regression testing, needle-in-a-haystack tasks, glitch detection, and bug report generation for both images and videos of various games. Code and data are available at: https://asgaardlab.github.io/videogameqa-bench/
HoT: Highlighted Chain of Thought for Referencing Supporting Facts from Inputs
Mar 05, 2025An Achilles heel of Large Language Models (LLMs) is their tendency to hallucinate non-factual statements. A response mixed of factual and non-factual statements poses a challenge for humans to verify and accurately base their decisions on. To combat this problem, we propose Highlighted Chain-of-Thought Prompting (HoT), a technique for prompting LLMs to generate responses with XML tags that ground facts to those provided in the query. That is, given an input question, LLMs would first re-format the question to add XML tags highlighting key facts, and then, generate a response with highlights over the facts referenced from the input. Interestingly, in few-shot settings, HoT outperforms vanilla chain of thought prompting (CoT) on a wide range of 17 tasks from arithmetic, reading comprehension to logical reasoning. When asking humans to verify LLM responses, highlights help time-limited participants to more accurately and efficiently recognize when LLMs are correct. Yet, surprisingly, when LLMs are wrong, HoTs tend to make users believe that an answer is correct.
VideoGameBunny: Towards vision assistants for video games
Jul 21, 2024



Large multimodal models (LMMs) hold substantial promise across various domains, from personal assistance in daily tasks to sophisticated applications like medical diagnostics. However, their capabilities have limitations in the video game domain, such as challenges with scene understanding, hallucinations, and inaccurate descriptions of video game content, especially in open-source models. This paper describes the development of VideoGameBunny, a LLaVA-style model based on Bunny, specifically tailored for understanding images from video games. We release intermediate checkpoints, training logs, and an extensive dataset comprising 185,259 video game images from 413 titles, along with 389,565 image-instruction pairs that include image captions, question-answer pairs, and a JSON representation of 16 elements of 136,974 images. Our experiments show that our high quality game-related data has the potential to make a relatively small model outperform the much larger state-of-the-art model LLaVa-1.6-34b (which has more than 4x the number of parameters). Our study paves the way for future research in video game understanding on tasks such as playing, commentary, and debugging. Code and data are available at https://videogamebunny.github.io/
Vision language models are blind
Jul 11, 2024Large language models with vision capabilities (VLMs), e.g., GPT-4o and Gemini 1.5 Pro are powering countless image-text applications and scoring high on many vision-understanding benchmarks. We propose BlindTest, a suite of 7 visual tasks absurdly easy to humans such as identifying (a) whether two circles overlap; (b) whether two lines intersect; (c) which letter is being circled in a word; and (d) counting the number of circles in a Olympic-like logo. Surprisingly, four state-of-the-art VLMs are, on average, only 56.20% accurate on our benchmark, with \newsonnet being the best (73.77% accuracy). On BlindTest, VLMs struggle with tasks that requires precise spatial information and counting (from 0 to 10), sometimes providing an impression of a person with myopia seeing fine details as blurry and making educated guesses. Code is available at: https://vlmsareblind.github.io/
Allowing humans to interactively guide machines where to look does not always improve human-AI team's classification accuracy
Apr 14, 2024Via thousands of papers in Explainable AI (XAI), attention maps \cite{vaswani2017attention} and feature attribution maps \cite{bansal2020sam} have been established as a common means for finding how important each input feature is to an AI's decisions. It is an interesting, unexplored question whether allowing users to edit the feature importance at test time would improve a human-AI team's accuracy on downstream tasks. In this paper, we address this question by leveraging CHM-Corr, a state-of-the-art, ante-hoc explainable classifier \cite{taesiri2022visual} that first predicts patch-wise correspondences between the input and training-set images, and then base on them to make classification decisions. We build CHM-Corr++, an interactive interface for CHM-Corr, enabling users to edit the feature attribution map provided by CHM-Corr and observe updated model decisions. Via CHM-Corr++, users can gain insights into if, when, and how the model changes its outputs, improving their understanding beyond static explanations. However, our user study with 18 users who performed 1,400 decisions finds no statistical significance that our interactive approach improves user accuracy on CUB-200 bird image classification over static explanations. This challenges the hypothesis that interactivity can boost human-AI team accuracy~\cite{sokol2020one,sun2022exploring,shen2024towards,singh2024rethinking,mindlin2024beyond,lakkaraju2022rethinking,cheng2019explaining,liu2021understanding} and raises needs for future research. We open-source CHM-Corr++, an interactive tool for editing image classifier attention (see an interactive demo \href{http://137.184.82.109:7080/}{here}). % , and it lays the groundwork for future research to enable effective human-AI interaction in computer vision. We release code and data on \href{https://github.com/anguyen8/chm-corr-interactive}{github}.
GlitchBench: Can large multimodal models detect video game glitches?
Dec 08, 2023


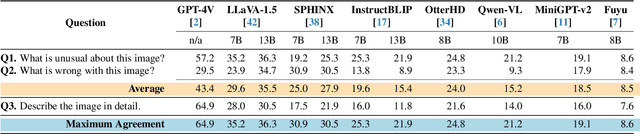
Large multimodal models (LMMs) have evolved from large language models (LLMs) to integrate multiple input modalities, such as visual inputs. This integration augments the capacity of LLMs for tasks requiring visual comprehension and reasoning. However, the extent and limitations of their enhanced abilities are not fully understood, especially when it comes to real-world tasks. To address this gap, we introduce GlitchBench, a novel benchmark derived from video game quality assurance tasks, to test and evaluate the reasoning capabilities of LMMs. Our benchmark is curated from a variety of unusual and glitched scenarios from video games and aims to challenge both the visual and linguistic reasoning powers of LMMs in detecting and interpreting out-of-the-ordinary events. We evaluate multiple state-of-the-art LMMs, and we show that GlitchBench presents a new challenge for these models. Code and data are available at: https://glitchbench.github.io/
Zoom is what you need: An empirical study of the power of zoom and spatial biases in image classification
Apr 11, 2023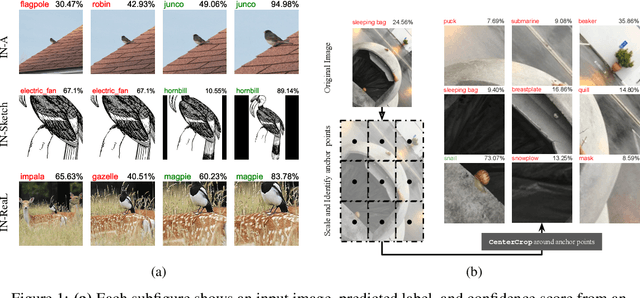

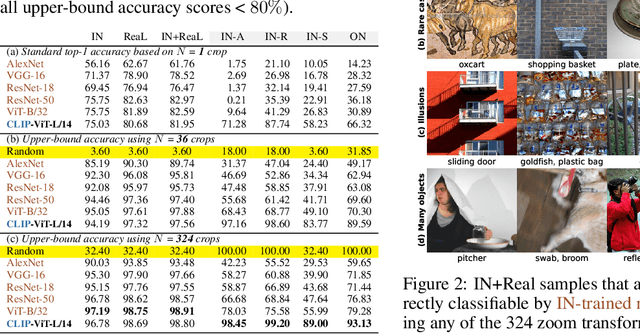

Image classifiers are information-discarding machines, by design. Yet, how these models discard information remains mysterious. We hypothesize that one way for image classifiers to reach high accuracy is to first zoom to the most discriminative region in the image and then extract features from there to predict image labels. We study six popular networks ranging from AlexNet to CLIP and find that proper framing of the input image can lead to the correct classification of 98.91% of ImageNet images. Furthermore, we explore the potential and limits of zoom transforms in image classification and uncover positional biases in various datasets, especially a strong center bias in two popular datasets: ImageNet-A and ObjectNet. Finally, leveraging our insights into the potential of zoom, we propose a state-of-the-art test-time augmentation (TTA) technique that improves classification accuracy by forcing models to explicitly perform zoom-in operations before making predictions. Our method is more interpretable, accurate, and faster than MEMO, a state-of-the-art TTA method. Additionally, we propose ImageNet-Hard, a new benchmark where zooming in alone often does not help state-of-the-art models better label images.