 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Aligned Reference Image Quality Assessment for Novel View Synthesis
Nov 11, 2025Evaluating the perceptual quality of Novel View Synthesis (NVS) images remains a key challenge, particularly in the absence of pixel-aligned ground truth references. Full-Reference Image Quality Assessment (FR-IQA) methods fail under misalignment, while No-Reference (NR-IQA) methods struggle with generalization. In this work, we introduce a Non-Aligned Reference (NAR-IQA) framework tailored for NVS, where it is assumed that the reference view shares partial scene content but lacks pixel-level alignment. We constructed a large-scale image dataset containing synthetic distortions targeting Temporal Regions of Interest (TROI) to train our NAR-IQA model. Our model is built on a contrastive learning framework that incorporates LoRA-enhanced DINOv2 embeddings and is guided by supervision from existing IQA methods. We train exclusively on synthetically generated distortions, deliberately avoiding overfitting to specific real NVS samples and thereby enhancing the model's generalization capability. Our model outperforms state-of-the-art FR-IQA, NR-IQA, and NAR-IQA methods, achieving robust performance on both aligned and non-aligned references. We also conducted a novel user study to gather data on human preferences when viewing non-aligned references in NVS. We find strong correlation between our proposed quality prediction model and the collected subjective ratings. For dataset and code, please visit our project page: https://stootaghaj.github.io/nova-project/
VideoGameQA-Bench: Evaluating Vision-Language Models for Video Game Quality Assurance
May 21, 2025With video games now generating the highest revenues in the entertainment industry, optimizing game development workflows has become essential for the sector's sustained growth. Recent advancements in Vision-Language Models (VLMs) offer considerable potential to automate and enhance various aspects of game development, particularly Quality Assurance (QA), which remains one of the industry's most labor-intensive processes with limited automation options. To accurately evaluate the performance of VLMs in video game QA tasks and determine their effectiveness in handling real-world scenarios, there is a clear need for standardized benchmarks, as existing benchmarks are insufficient to address the specific requirements of this domain. To bridge this gap, we introduce VideoGameQA-Bench, a comprehensive benchmark that covers a wide array of game QA activities, including visual unit testing, visual regression testing, needle-in-a-haystack tasks, glitch detection, and bug report generation for both images and videos of various games. Code and data are available at: https://asgaardlab.github.io/videogameqa-bench/
Quality Prediction of AI Generated Images and Videos: Emerging Trends and Opportunities
Oct 11, 2024
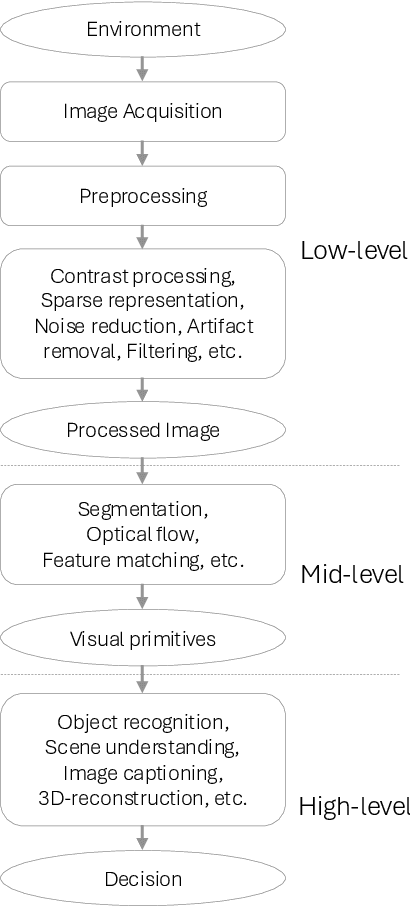

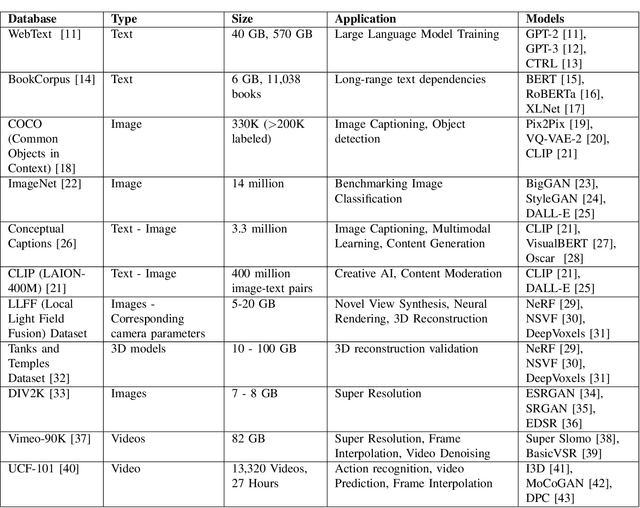
The advent of AI has influenced many aspects of human life, from self-driving cars and intelligent chatbots to text-based image and video generation models capable of creating realistic images and videos based on user prompts (text-to-image, image-to-image, and image-to-video). AI-based methods for image and video super resolution, video frame interpolation, denoising, and compression have already gathered significant attention and interest in the industry and some solutions are already being implemented in real-world products and services. However, to achieve widespread integration and acceptance, AI-generated and enhanced content must be visually accurate, adhere to intended use, and maintain high visual quality to avoid degrading the end user's quality of experience (QoE). One way to monitor and control the visual "quality" of AI-generated and -enhanced content is by deploying Image Quality Assessment (IQA) and Video Quality Assessment (VQA) models. However, most existing IQA and VQA models measure visual fidelity in terms of "reconstruction" quality against a pristine reference content and were not designed to assess the quality of "generative" artifacts. To address this, newer metrics and models have recently been proposed, but their performance evaluation and overall efficacy have been limited by datasets that were too small or otherwise lack representative content and/or distortion capacity; and by performance measures that can accurately report the success of an IQA/VQA model for "GenAI". This paper examines the current shortcomings and possibilities presented by AI-generated and enhanced image and video content, with a particular focus on end-user perceived quality. Finally, we discuss open questions and make recommendations for future work on the "GenAI" quality assessment problems, towards further progressing on this interesting and relevant field of research.
AIM 2024 Challenge on UHD Blind Photo Quality Assessment
Sep 24, 2024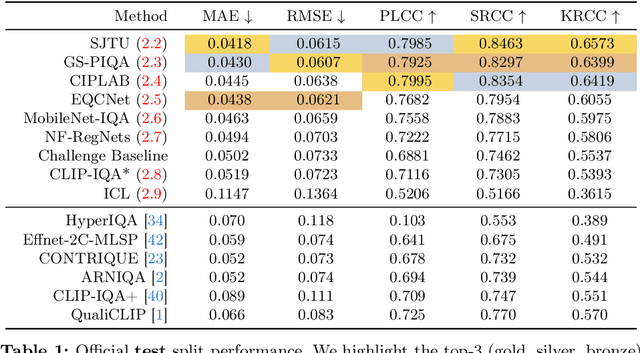
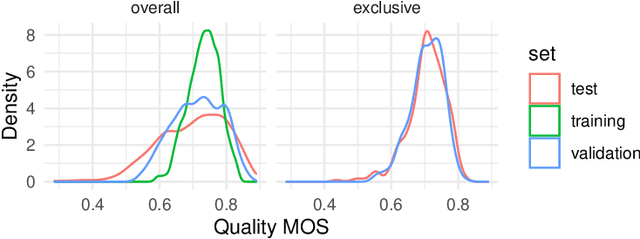
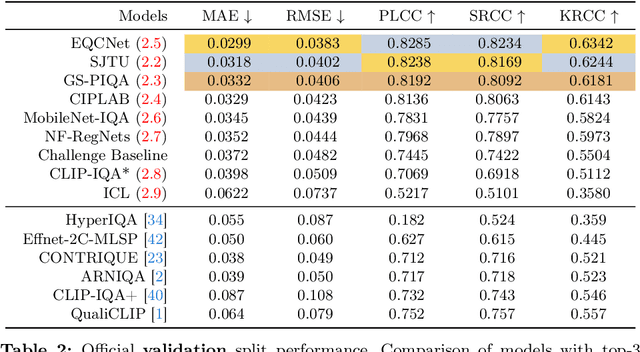
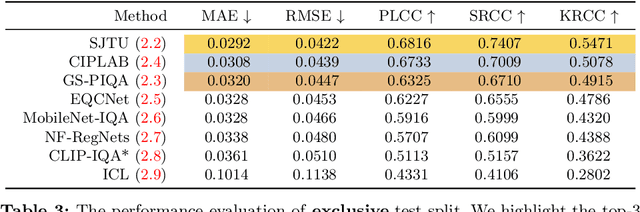
We introduce the AIM 2024 UHD-IQA Challenge, a competition to advance the No-Reference Image Quality Assessment (NR-IQA) task for modern, high-resolution photos. The challenge is based on the recently released UHD-IQA Benchmark Database, which comprises 6,073 UHD-1 (4K) images annotated with perceptual quality ratings from expert raters. Unlike previous NR-IQA datasets, UHD-IQA focuses on highly aesthetic photos of superior technical quality, reflecting the ever-increasing standards of digital photography. This challenge aims to develop efficient and effective NR-IQA models. Participants are tasked with creating novel architectures and training strategies to achieve high predictive performance on UHD-1 images within a computational budget of 50G MACs. This enables model deployment on edge devices and scalable processing of extensive image collections. Winners are determined based on a combination of performance metrics, including correlation measures (SRCC, PLCC, KRCC), absolute error metrics (MAE, RMSE), and computational efficiency (G MACs). To excel in this challenge, participants leverage techniques like knowledge distillation, low-precision inference, and multi-scale training. By pushing the boundaries of NR-IQA for high-resolution photos, the UHD-IQA Challenge aims to stimulate the development of practical models that can keep pace with the rapidly evolving landscape of digital photography. The innovative solutions emerging from this competition will have implications for various applications, from photo curation and enhancement to image compression.
Foundation Models Boost Low-Level Perceptual Similarity Metrics
Sep 11, 2024



For full-reference image quality assessment (FR-IQA) using deep-learning approaches, the perceptual similarity score between a distorted image and a reference image is typically computed as a distance measure between features extracted from a pretrained CNN or more recently, a Transformer network. Often, these intermediate features require further fine-tuning or processing with additional neural network layers to align the final similarity scores with human judgments. So far, most IQA models based on foundation models have primarily relied on the final layer or the embedding for the quality score estimation. In contrast, this work explores the potential of utilizing the intermediate features of these foundation models, which have largely been unexplored so far in the design of low-level perceptual similarity metrics. We demonstrate that the intermediate features are comparatively more effective. Moreover, without requiring any training, these metrics can outperform both traditional and state-of-the-art learned metrics by utilizing distance measures between the features.
LAR-IQA: A Lightweight, Accurate, and Robust No-Reference Image Quality Assessment Model
Aug 30, 2024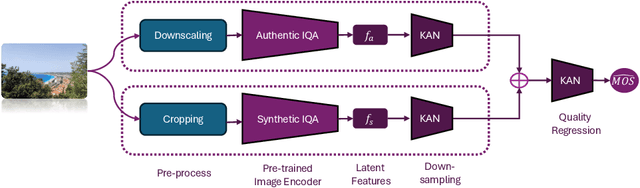
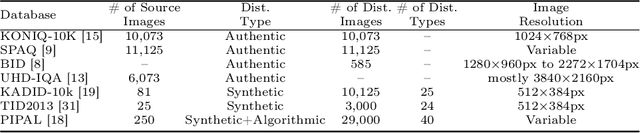
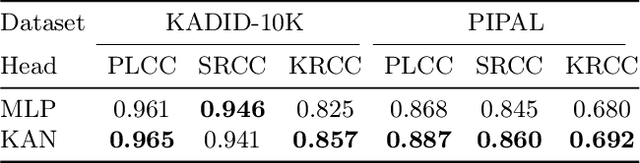
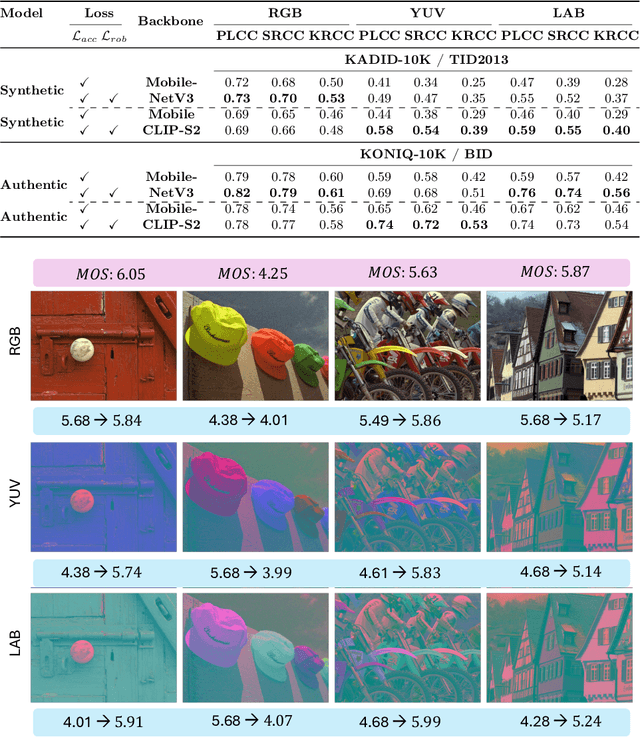
Recent advancements in the field of No-Reference Image Quality Assessment (NR-IQA) using deep learning techniques demonstrate high performance across multiple open-source datasets. However, such models are typically very large and complex making them not so suitable for real-world deployment, especially on resource- and battery-constrained mobile devices. To address this limitation, we propose a compact, lightweight NR-IQA model that achieves state-of-the-art (SOTA) performance on ECCV AIM UHD-IQA challenge validation and test datasets while being also nearly 5.7 times faster than the fastest SOTA model. Our model features a dual-branch architecture, with each branch separately trained on synthetically and authentically distorted images which enhances the model's generalizability across different distortion types. To improve robustness under diverse real-world visual conditions, we additionally incorporate multiple color spaces during the training process. We also demonstrate the higher accuracy of recently proposed Kolmogorov-Arnold Networks (KANs) for final quality regression as compared to the conventional Multi-Layer Perceptrons (MLPs). Our evaluation considering various open-source datasets highlights the practical, high-accuracy, and robust performance of our proposed lightweight model. Code: https://github.com/nasimjamshidi/LAR-IQA.
MSLIQA: Enhancing Learning Representations for Image Quality Assessment through Multi-Scale Learning
Aug 29, 2024No-Reference Image Quality Assessment (NR-IQA) remains a challenging task due to the diversity of distortions and the lack of large annotated datasets. Many studies have attempted to tackle these challenges by developing more accurate NR-IQA models, often employing complex and computationally expensive networks, or by bridging the domain gap between various distortions to enhance performance on test datasets. In our work, we improve the performance of a generic lightweight NR-IQA model by introducing a novel augmentation strategy that boosts its performance by almost 28\%. This augmentation strategy enables the network to better discriminate between different distortions in various parts of the image by zooming in and out. Additionally, the inclusion of test-time augmentation further enhances performance, making our lightweight network's results comparable to the current state-of-the-art models, simply through the use of augmentations.
AIS 2024 Challenge on Video Quality Assessment of User-Generated Content: Methods and Results
Apr 24, 2024



This paper reviews the AIS 2024 Video Quality Assessment (VQA) Challenge, focused on User-Generated Content (UGC). The aim of this challenge is to gather deep learning-based methods capable of estimating the perceptual quality of UGC videos. The user-generated videos from the YouTube UGC Dataset include diverse content (sports, games, lyrics, anime, etc.), quality and resolutions. The proposed methods must process 30 FHD frames under 1 second. In the challenge, a total of 102 participants registered, and 15 submitted code and models. The performance of the top-5 submissions is reviewed and provided here as a survey of diverse deep models for efficient video quality assessment of user-generated content.
Bjøntegaard Delta : A Tutorial Overview of the Metric, Evolution, Challenges, and Recommendations
Jan 08, 2024The Bj{\o}ntegaard Delta (BD) method proposed in 2001 has become a popular tool for comparing video codec compression efficiency. It was initially proposed to compute bitrate and quality differences between two Rate-Distortion curves using PSNR as a distortion metric. Over the years, many works have calculated and reported BD results using other objective quality metrics such as SSIM, VMAF and, in some cases, even subjective ratings (mean opinion scores). However, the lack of consolidated literature explaining the metric, its evolution over the years, and a systematic evaluation of the same under different test conditions can result in a wrong interpretation of the BD results thus obtained. Towards this end, this paper presents a detailed tutorial describing the BD method and example cases where the metric might fail. We also provide a detailed history of its evolution, including a discussion of various proposed improvements and variations over the last 20 years. In addition, we evaluate the various BD methods and their open-source implementations, considering different objective quality metrics and subjective ratings taking into account different RD characteristics. Based on our results, we present a set of recommendations on using existing BD metrics and various insights for possible exploration towards developing more effective tools for codec compression efficiency evaluation and comparison.