 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Prediction of AI Generated Images and Videos: Emerging Trends and Opportunities
Paper and Code
Oct 11, 2024
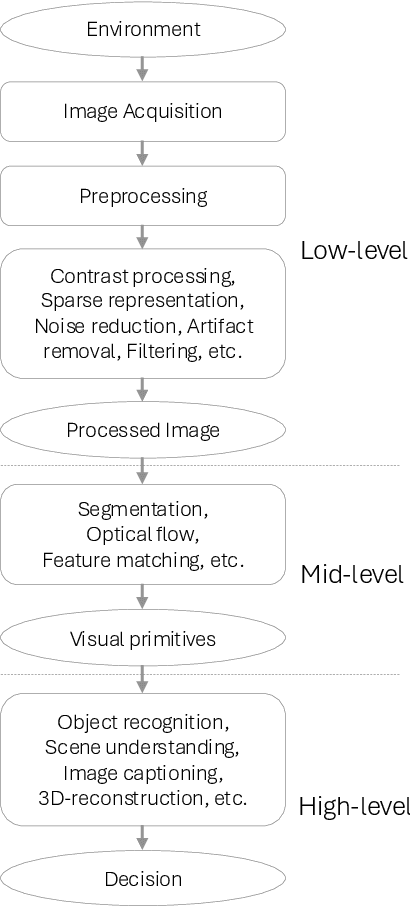

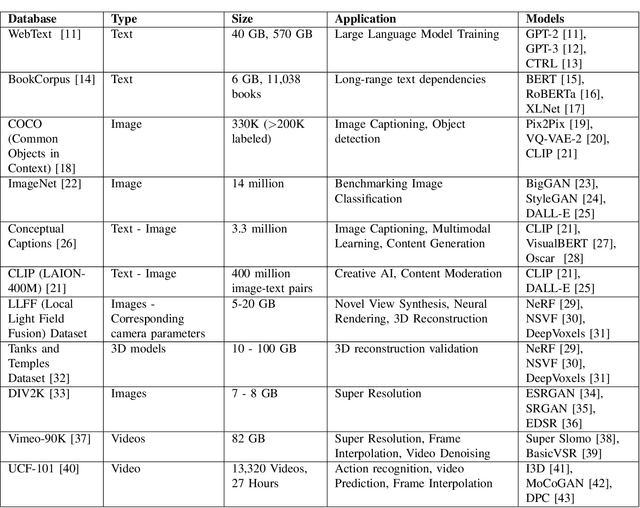
The advent of AI has influenced many aspects of human life, from self-driving cars and intelligent chatbots to text-based image and video generation models capable of creating realistic images and videos based on user prompts (text-to-image, image-to-image, and image-to-video). AI-based methods for image and video super resolution, video frame interpolation, denoising, and compression have already gathered significant attention and interest in the industry and some solutions are already being implemented in real-world products and services. However, to achieve widespread integration and acceptance, AI-generated and enhanced content must be visually accurate, adhere to intended use, and maintain high visual quality to avoid degrading the end user's quality of experience (QoE). One way to monitor and control the visual "quality" of AI-generated and -enhanced content is by deploying Image Quality Assessment (IQA) and Video Quality Assessment (VQA) models. However, most existing IQA and VQA models measure visual fidelity in terms of "reconstruction" quality against a pristine reference content and were not designed to assess the quality of "generative" artifacts. To address this, newer metrics and models have recently been proposed, but their performance evaluation and overall efficacy have been limited by datasets that were too small or otherwise lack representative content and/or distortion capacity; and by performance measures that can accurately report the success of an IQA/VQA model for "GenAI". This paper examines the current shortcomings and possibilities presented by AI-generated and enhanced image and video content, with a particular focus on end-user perceived quality. Finally, we discuss open questions and make recommendations for future work on the "GenAI" quality assessment problems, towards further progressing on this interesting and relevant field of research.