 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Aligned Reference Image Quality Assessment for Novel View Synthesis
Nov 11, 2025Evaluating the perceptual quality of Novel View Synthesis (NVS) images remains a key challenge, particularly in the absence of pixel-aligned ground truth references. Full-Reference Image Quality Assessment (FR-IQA) methods fail under misalignment, while No-Reference (NR-IQA) methods struggle with generalization. In this work, we introduce a Non-Aligned Reference (NAR-IQA) framework tailored for NVS, where it is assumed that the reference view shares partial scene content but lacks pixel-level alignment. We constructed a large-scale image dataset containing synthetic distortions targeting Temporal Regions of Interest (TROI) to train our NAR-IQA model. Our model is built on a contrastive learning framework that incorporates LoRA-enhanced DINOv2 embeddings and is guided by supervision from existing IQA methods. We train exclusively on synthetically generated distortions, deliberately avoiding overfitting to specific real NVS samples and thereby enhancing the model's generalization capability. Our model outperforms state-of-the-art FR-IQA, NR-IQA, and NAR-IQA methods, achieving robust performance on both aligned and non-aligned references. We also conducted a novel user study to gather data on human preferences when viewing non-aligned references in NVS. We find strong correlation between our proposed quality prediction model and the collected subjective ratings. For dataset and code, please visit our project page: https://stootaghaj.github.io/nova-project/
WP-CLIP: Leveraging CLIP to Predict Wölfflin's Principles in Visual Art
Aug 18, 2025W\"olfflin's five principles offer a structured approach to analyzing stylistic variations for formal analysis. However, no existing metric effectively predicts all five principles in visual art. Computationally evaluating the visual aspects of a painting requires a metric that can interpret key elements such as color, composition, and thematic choices. Recent advancements in vision-language models (VLMs) have demonstrated their ability to evaluate abstract image attributes, making them promising candidates for this task. In this work, we investigate whether CLIP, pre-trained on large-scale data, can understand and predict W\"olfflin's principles. Our findings indicate that it does not inherently capture such nuanced stylistic elements. To address this, we fine-tune CLIP on annotated datasets of real art images to predict a score for each principle. We evaluate our model, WP-CLIP, on GAN-generated paintings and the Pandora-18K art dataset, demonstrating its ability to generalize across diverse artistic styles. Our results highlight the potential of VLMs for automated art analysis.
VideoGameQA-Bench: Evaluating Vision-Language Models for Video Game Quality Assurance
May 21, 2025With video games now generating the highest revenues in the entertainment industry, optimizing game development workflows has become essential for the sector's sustained growth. Recent advancements in Vision-Language Models (VLMs) offer considerable potential to automate and enhance various aspects of game development, particularly Quality Assurance (QA), which remains one of the industry's most labor-intensive processes with limited automation options. To accurately evaluate the performance of VLMs in video game QA tasks and determine their effectiveness in handling real-world scenarios, there is a clear need for standardized benchmarks, as existing benchmarks are insufficient to address the specific requirements of this domain. To bridge this gap, we introduce VideoGameQA-Bench, a comprehensive benchmark that covers a wide array of game QA activities, including visual unit testing, visual regression testing, needle-in-a-haystack tasks, glitch detection, and bug report generation for both images and videos of various games. Code and data are available at: https://asgaardlab.github.io/videogameqa-bench/
Quality Prediction of AI Generated Images and Videos: Emerging Trends and Opportunities
Oct 11, 2024
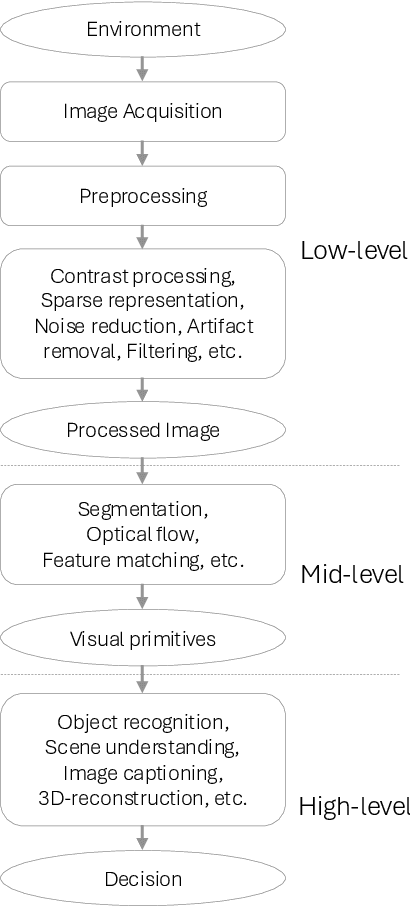

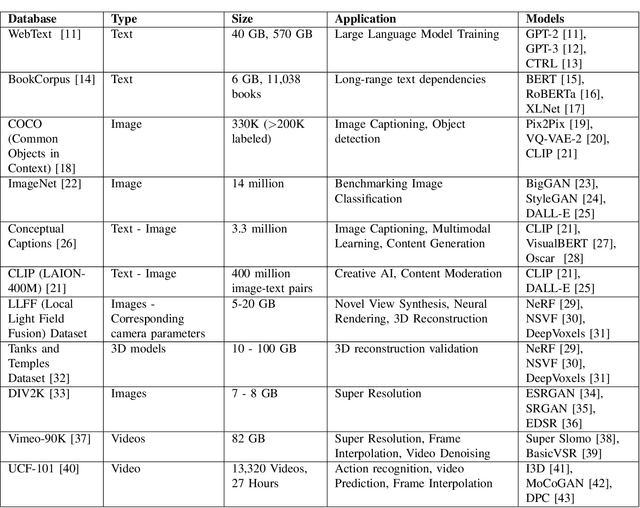
The advent of AI has influenced many aspects of human life, from self-driving cars and intelligent chatbots to text-based image and video generation models capable of creating realistic images and videos based on user prompts (text-to-image, image-to-image, and image-to-video). AI-based methods for image and video super resolution, video frame interpolation, denoising, and compression have already gathered significant attention and interest in the industry and some solutions are already being implemented in real-world products and services. However, to achieve widespread integration and acceptance, AI-generated and enhanced content must be visually accurate, adhere to intended use, and maintain high visual quality to avoid degrading the end user's quality of experience (QoE). One way to monitor and control the visual "quality" of AI-generated and -enhanced content is by deploying Image Quality Assessment (IQA) and Video Quality Assessment (VQA) models. However, most existing IQA and VQA models measure visual fidelity in terms of "reconstruction" quality against a pristine reference content and were not designed to assess the quality of "generative" artifacts. To address this, newer metrics and models have recently been proposed, but their performance evaluation and overall efficacy have been limited by datasets that were too small or otherwise lack representative content and/or distortion capacity; and by performance measures that can accurately report the success of an IQA/VQA model for "GenAI". This paper examines the current shortcomings and possibilities presented by AI-generated and enhanced image and video content, with a particular focus on end-user perceived quality. Finally, we discuss open questions and make recommendations for future work on the "GenAI" quality assessment problems, towards further progressing on this interesting and relevant field of research.
Foundation Models Boost Low-Level Perceptual Similarity Metrics
Sep 11, 2024



For full-reference image quality assessment (FR-IQA) using deep-learning approaches, the perceptual similarity score between a distorted image and a reference image is typically computed as a distance measure between features extracted from a pretrained CNN or more recently, a Transformer network. Often, these intermediate features require further fine-tuning or processing with additional neural network layers to align the final similarity scores with human judgments. So far, most IQA models based on foundation models have primarily relied on the final layer or the embedding for the quality score estimation. In contrast, this work explores the potential of utilizing the intermediate features of these foundation models, which have largely been unexplored so far in the design of low-level perceptual similarity metrics. We demonstrate that the intermediate features are comparatively more effective. Moreover, without requiring any training, these metrics can outperform both traditional and state-of-the-art learned metrics by utilizing distance measures between the features.
Attacking Perceptual Similarity Metrics
May 15, 2023



Perceptual similarity metrics have progressively become more correlated with human judgments on perceptual similarity; however, despite recent advances, the addition of an imperceptible distortion can still compromise these metrics. In our study, we systematically examine the robustness of these metrics to imperceptible adversarial perturbations. Following the two-alternative forced-choice experimental design with two distorted images and one reference image, we perturb the distorted image closer to the reference via an adversarial attack until the metric flips its judgment. We first show that all metrics in our study are susceptible to perturbations generated via common adversarial attacks such as FGSM, PGD, and the One-pixel attack. Next, we attack the widely adopted LPIPS metric using spatial-transformation-based adversarial perturbations (stAdv) in a white-box setting to craft adversarial examples that can effectively transfer to other similarity metrics in a black-box setting. We also combine the spatial attack stAdv with PGD ($\ell_\infty$-bounded) attack to increase transferability and use these adversarial examples to benchmark the robustness of both traditional and recently developed metrics. Our benchmark provides a good starting point for discussion and further research on the robustness of metrics to imperceptible adversarial perturbations.
A Perceptual Quality Metric for Video Frame Interpolation
Oct 04, 2022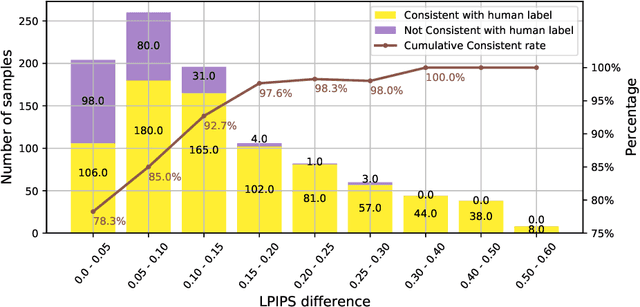
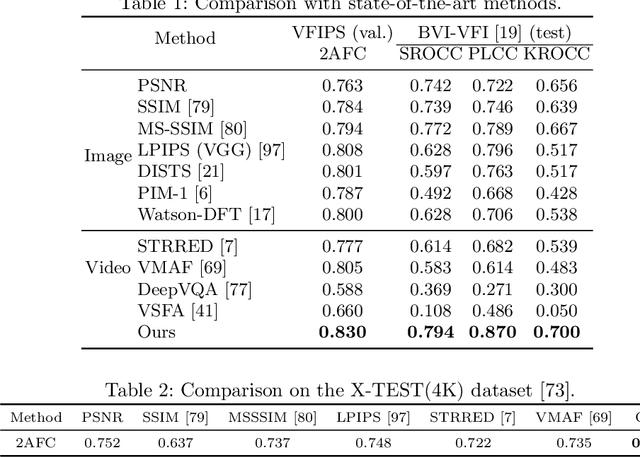

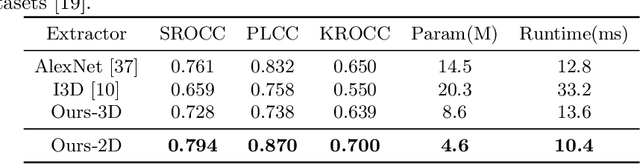
Research on video frame interpolation has made significant progress in recent years. However, existing methods mostly use off-the-shelf metrics to measure the quality of interpolation results with the exception of a few methods that employ user studies, which is time-consuming. As video frame interpolation results often exhibit unique artifacts, existing quality metrics sometimes are not consistent with human perception when measuring the interpolation results. Some recent deep learning-based perceptual quality metrics are shown more consistent with human judgments, but their performance on videos is compromised since they do not consider temporal information. In this paper, we present a dedicated perceptual quality metric for measuring video frame interpolation results. Our method learns perceptual features directly from videos instead of individual frames. It compares pyramid features extracted from video frames and employs Swin Transformer blocks-based spatio-temporal modules to extract spatio-temporal information. To train our metric, we collected a new video frame interpolation quality assessment dataset. Our experiments show that our dedicated quality metric outperforms state-of-the-art methods when measuring video frame interpolation results. Our code and model are made publicly available at \url{https://github.com/hqqxyy/VFIPS}.
Shift-tolerant Perceptual Similarity Metric
Jul 27, 2022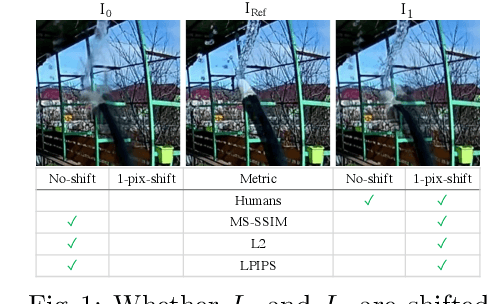
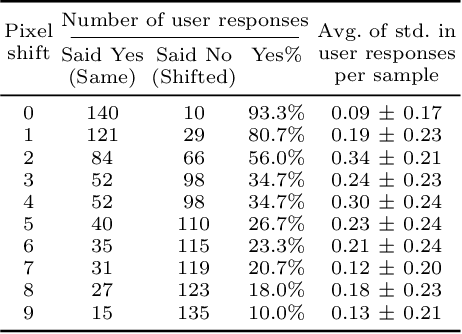

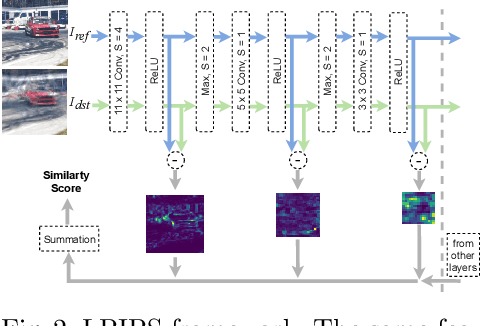
Existing perceptual similarity metrics assume an image and its reference are well aligned. As a result, these metrics are often sensitive to a small alignment error that is imperceptible to the human eyes. This paper studies the effect of small misalignment, specifically a small shift between the input and reference image, on existing metrics, and accordingly develops a shift-tolerant similarity metric. This paper builds upon LPIPS, a widely used learned perceptual similarity metric, and explores architectural design considerations to make it robust against imperceptible misalignment. Specifically, we study a wide spectrum of neural network elements, such as anti-aliasing filtering, pooling, striding, padding, and skip connection, and discuss their roles in making a robust metric. Based on our studies, we develop a new deep neural network-based perceptual similarity metric. Our experiments show that our metric is tolerant to imperceptible shifts while being consistent with the human similarity judgment.