 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSort-free Gaussian Splatting via Weighted Sum Rendering
Oct 24, 2024



Recently, 3D Gaussian Splatting (3DGS) has emerged as a significant advancement in 3D scene reconstruction, attracting considerable attention due to its ability to recover high-fidelity details while maintaining low complexity. Despite the promising results achieved by 3DGS, its rendering performance is constrained by its dependence on costly non-commutative alpha-blending operations. These operations mandate complex view dependent sorting operations that introduce computational overhead, especially on the resource-constrained platforms such as mobile phones. In this paper, we propose Weighted Sum Rendering, which approximates alpha blending with weighted sums, thereby removing the need for sorting. This simplifies implementation, delivers superior performance, and eliminates the "popping" artifacts caused by sorting. Experimental results show that optimizing a generalized Gaussian splatting formulation to the new differentiable rendering yields competitive image quality. The method was implemented and tested in a mobile device GPU, achieving on average $1.23\times$ faster rendering.
Low-Latency Neural Stereo Streaming
Mar 26, 2024



The rise of new video modalities like virtual reality or autonomous driving has increased the demand for efficient multi-view video compression methods, both in terms of rate-distortion (R-D) performance and in terms of delay and runtime. While most recent stereo video compression approaches have shown promising performance, they compress left and right views sequentially, leading to poor parallelization and runtime performance. This work presents Low-Latency neural codec for Stereo video Streaming (LLSS), a novel parallel stereo video coding method designed for fast and efficient low-latency stereo video streaming. Instead of using a sequential cross-view motion compensation like existing methods, LLSS introduces a bidirectional feature shifting module to directly exploit mutual information among views and encode them effectively with a joint cross-view prior model for entropy coding. Thanks to this design, LLSS processes left and right views in parallel, minimizing latency; all while substantially improving R-D performance compared to both existing neural and conventional codecs.
Auxiliary Features-Guided Super Resolution for Monte Carlo Rendering
Oct 20, 2023This paper investigates super resolution to reduce the number of pixels to render and thus speed up Monte Carlo rendering algorithms. While great progress has been made to super resolution technologies, it is essentially an ill-posed problem and cannot recover high-frequency details in renderings. To address this problem, we exploit high-resolution auxiliary features to guide super resolution of low-resolution renderings. These high-resolution auxiliary features can be quickly rendered by a rendering engine and at the same time provide valuable high-frequency details to assist super resolution. To this end, we develop a cross-modality Transformer network that consists of an auxiliary feature branch and a low-resolution rendering branch. These two branches are designed to fuse high-resolution auxiliary features with the corresponding low-resolution rendering. Furthermore, we design residual densely-connected Swin Transformer groups to learn to extract representative features to enable high-quality super-resolution. Our experiments show that our auxiliary features-guided super-resolution method outperforms both super-resolution methods and Monte Carlo denoising methods in producing high-quality renderings.
* Accepted by CGF
A Perceptual Quality Metric for Video Frame Interpolation
Oct 04, 2022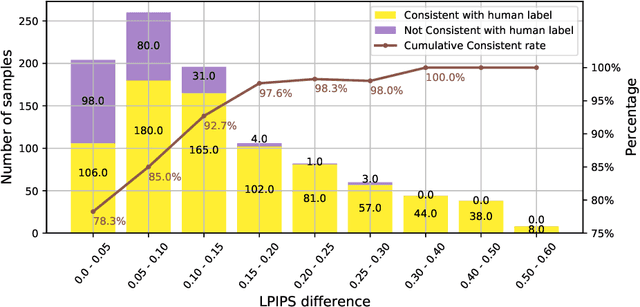
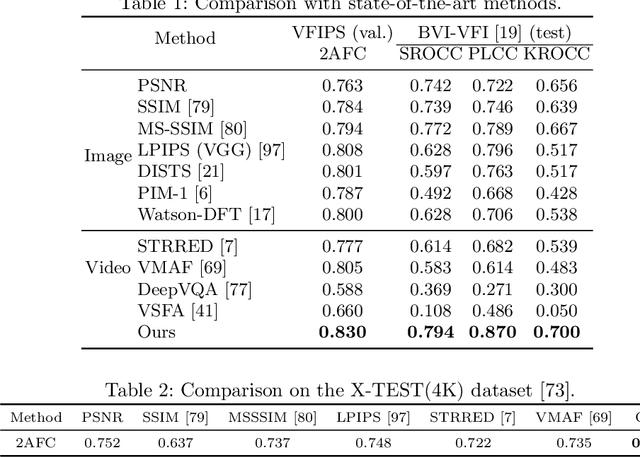

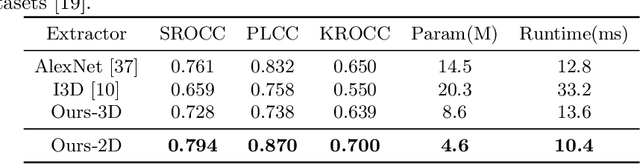
Research on video frame interpolation has made significant progress in recent years. However, existing methods mostly use off-the-shelf metrics to measure the quality of interpolation results with the exception of a few methods that employ user studies, which is time-consuming. As video frame interpolation results often exhibit unique artifacts, existing quality metrics sometimes are not consistent with human perception when measuring the interpolation results. Some recent deep learning-based perceptual quality metrics are shown more consistent with human judgments, but their performance on videos is compromised since they do not consider temporal information. In this paper, we present a dedicated perceptual quality metric for measuring video frame interpolation results. Our method learns perceptual features directly from videos instead of individual frames. It compares pyramid features extracted from video frames and employs Swin Transformer blocks-based spatio-temporal modules to extract spatio-temporal information. To train our metric, we collected a new video frame interpolation quality assessment dataset. Our experiments show that our dedicated quality metric outperforms state-of-the-art methods when measuring video frame interpolation results. Our code and model are made publicly available at \url{https://github.com/hqqxyy/VFIPS}.
Automatic Portrait Video Matting via Context Motion Network
Sep 13, 2021
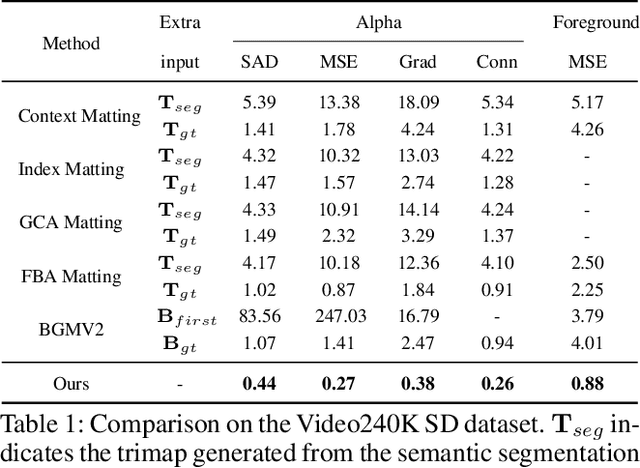
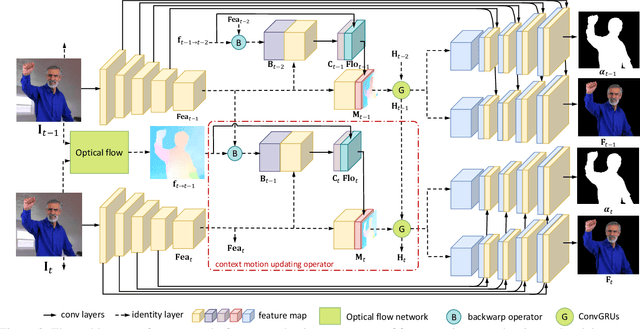
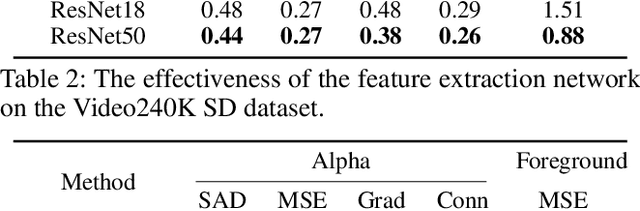
Automatic portrait video matting is an under-constrained problem. Most state-of-the-art methods only exploit the semantic information and process each frame individually. Their performance is compromised due to the lack of temporal information between the frames. To solve this problem, we propose the context motion network to leverage semantic information and motion information. To capture the motion information, we estimate the optical flow and design a context-motion updating operator to integrate features between frames recurrently. Our experiments show that our network outperforms state-of-the-art matting methods significantly on the Video240K SD dataset.
Fast Monte Carlo Rendering via Multi-Resolution Sampling
Jun 24, 2021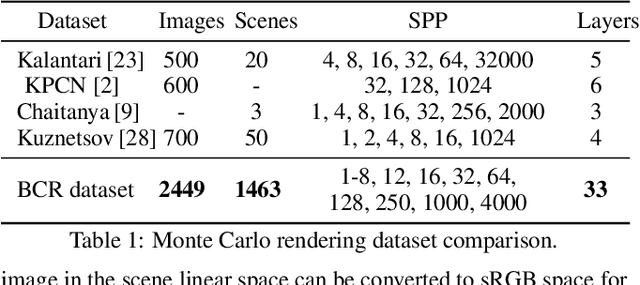

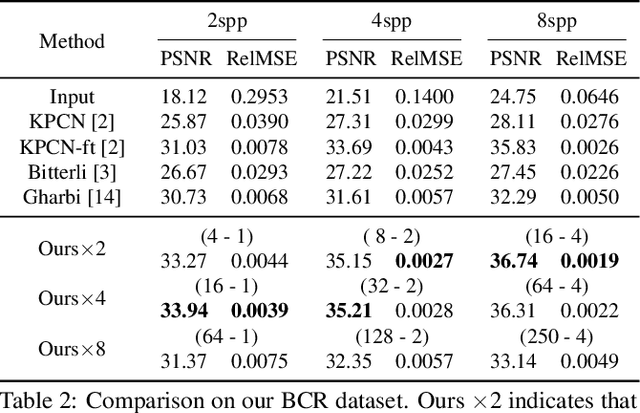
Monte Carlo rendering algorithms are widely used to produce photorealistic computer graphics images. However, these algorithms need to sample a substantial amount of rays per pixel to enable proper global illumination and thus require an immense amount of computation. In this paper, we present a hybrid rendering method to speed up Monte Carlo rendering algorithms. Our method first generates two versions of a rendering: one at a low resolution with a high sample rate (LRHS) and the other at a high resolution with a low sample rate (HRLS). We then develop a deep convolutional neural network to fuse these two renderings into a high-quality image as if it were rendered at a high resolution with a high sample rate. Specifically, we formulate this fusion task as a super resolution problem that generates a high resolution rendering from a low resolution input (LRHS), assisted with the HRLS rendering. The HRLS rendering provides critical high frequency details which are difficult to recover from the LRHS for any super resolution methods. Our experiments show that our hybrid rendering algorithm is significantly faster than the state-of-the-art Monte Carlo denoising methods while rendering high-quality images when tested on both our own BCR dataset and the Gharbi dataset. \url{https://github.com/hqqxyy/msspl}
Context-Aware Image Matting for Simultaneous Foreground and Alpha Estimation
Oct 02, 2019
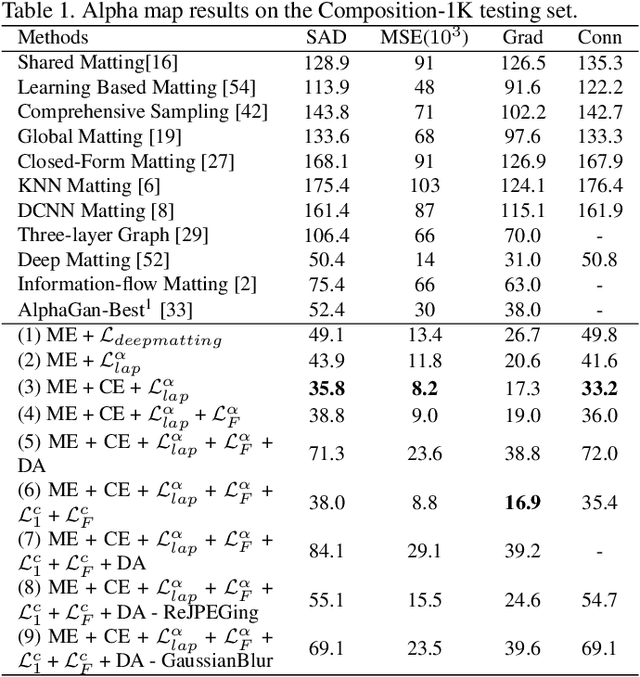
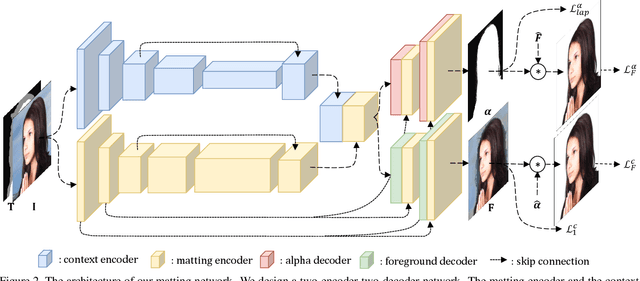
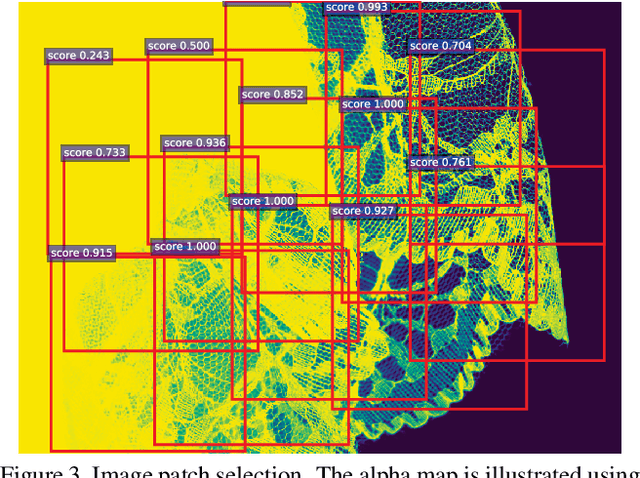
Natural image matting is an important problem in computer vision and graphics. It is an ill-posed problem when only an input image is available without any external information. While the recent deep learning approaches have shown promising results, they only estimate the alpha matte. This paper presents a context-aware natural image matting method for simultaneous foreground and alpha matte estimation. Our method employs two encoder networks to extract essential information for matting. Particularly, we use a matting encoder to learn local features and a context encoder to obtain more global context information. We concatenate the outputs from these two encoders and feed them into decoder networks to simultaneously estimate the foreground and alpha matte. To train this whole deep neural network, we employ both the standard Laplacian loss and the feature loss: the former helps to achieve high numerical performance while the latter leads to more perceptually plausible results. We also report several data augmentation strategies that greatly improve the network's generalization performance. Our qualitative and quantitative experiments show that our method enables high-quality matting for a single natural image. Our inference codes and models have been made publicly available at https://github.com/hqqxyy/Context-Aware-Matting.
Deep Ranking Model by Large Adaptive Margin Learning for Person Re-identification
Sep 17, 2017
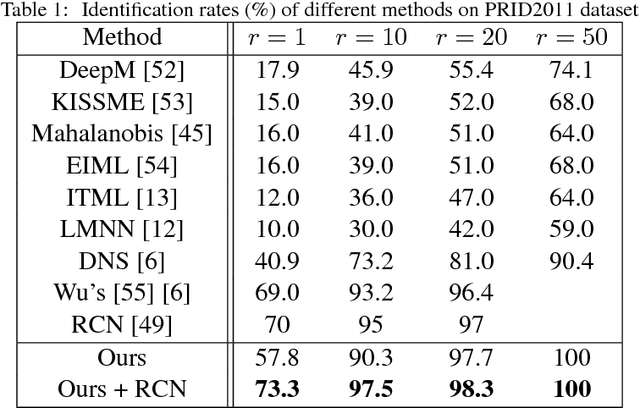
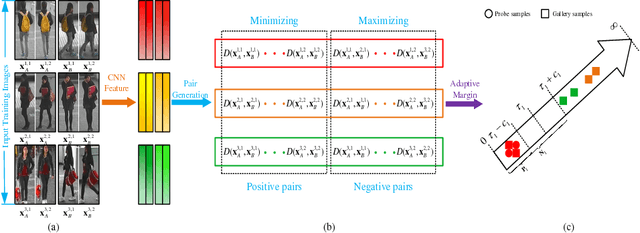
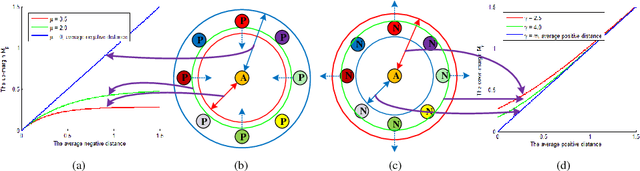
Person re-identification aims to match images of the same person across disjoint camera views, which is a challenging problem in video surveillance. The major challenge of this task lies in how to preserve the similarity of the same person against large variations caused by complex backgrounds, mutual occlusions and different illuminations, while discriminating the different individuals. In this paper, we present a novel deep ranking model with feature learning and fusion by learning a large adaptive margin between the intra-class distance and inter-class distance to solve the person re-identification problem. Specifically, we organize the training images into a batch of pairwise samples. Treating these pairwise samples as inputs, we build a novel part-based deep convolutional neural network (CNN) to learn the layered feature representations by preserving a large adaptive margin. As a result, the final learned model can effectively find out the matched target to the anchor image among a number of candidates in the gallery image set by learning discriminative and stable feature representations. Overcoming the weaknesses of conventional fixed-margin loss functions, our adaptive margin loss function is more appropriate for the dynamic feature space. On four benchmark datasets, PRID2011, Market1501, CUHK01 and 3DPeS, we extensively conduct comparative evaluations to demonstrate the advantages of the proposed method over the state-of-the-art approaches in person re-identification.
Large Margin Learning in Set to Set Similarity Comparison for Person Re-identification
Aug 18, 2017
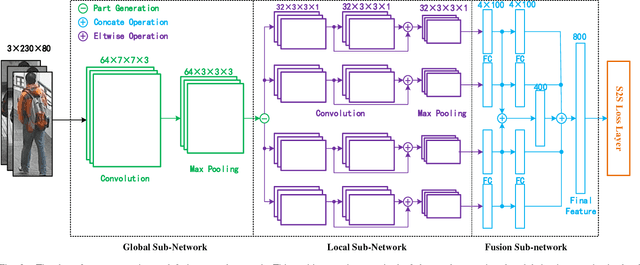
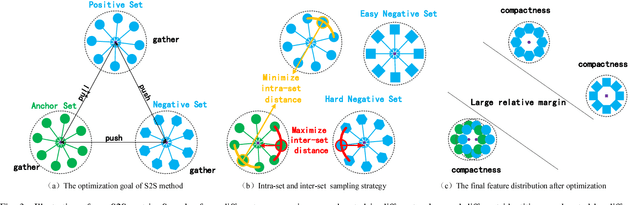
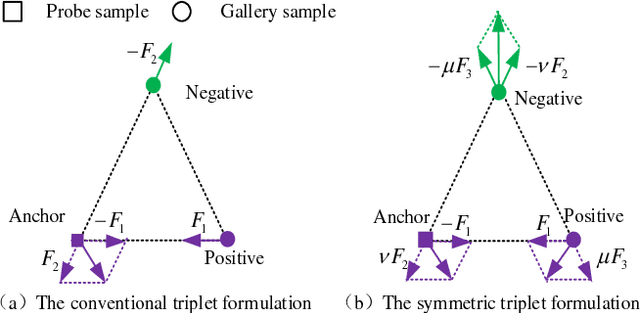
Person re-identification (Re-ID) aims at matching images of the same person across disjoint camera views, which is a challenging problem in multimedia analysis, multimedia editing and content-based media retrieval communities. The major challenge lies in how to preserve similarity of the same person across video footages with large appearance variations, while discriminating different individuals. To address this problem, conventional methods usually consider the pairwise similarity between persons by only measuring the point to point (P2P) distance. In this paper, we propose to use deep learning technique to model a novel set to set (S2S) distance, in which the underline objective focuses on preserving the compactness of intra-class samples for each camera view, while maximizing the margin between the intra-class set and inter-class set. The S2S distance metric is consisted of three terms, namely the class-identity term, the relative distance term and the regularization term. The class-identity term keeps the intra-class samples within each camera view gathering together, the relative distance term maximizes the distance between the intra-class class set and inter-class set across different camera views, and the regularization term smoothness the parameters of deep convolutional neural network (CNN). As a result, the final learned deep model can effectively find out the matched target to the probe object among various candidates in the video gallery by learning discriminative and stable feature representations. Using the CUHK01, CUHK03, PRID2011 and Market1501 benchmark datasets, we extensively conducted comparative evaluations to demonstrate the advantages of our method over the state-of-the-art approaches.