Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Portrait Video Matting via Context Motion Network
Sep 13, 2021
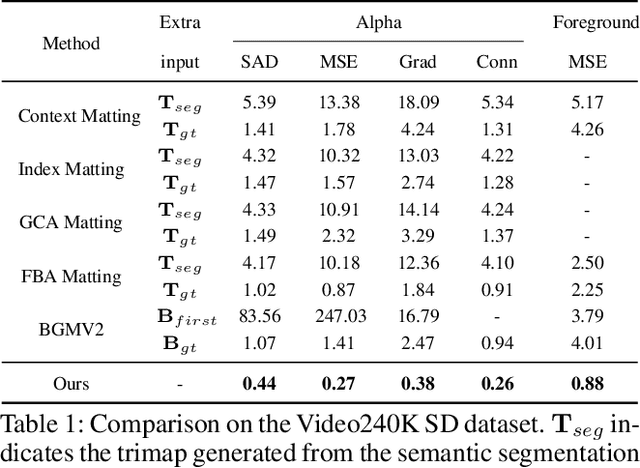
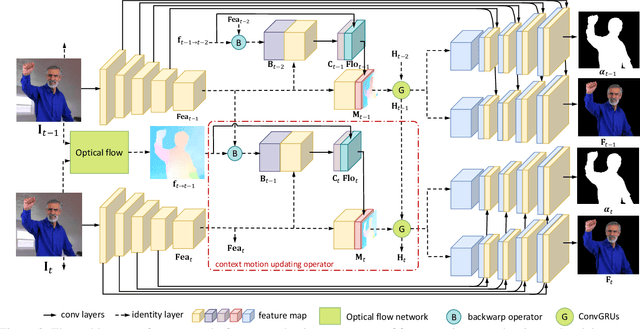
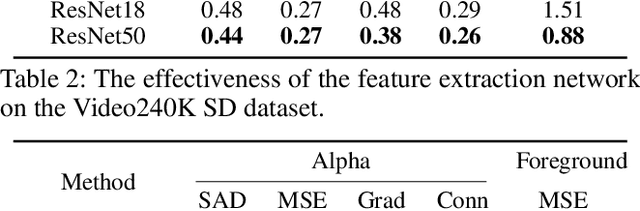
Automatic portrait video matting is an under-constrained problem. Most state-of-the-art methods only exploit the semantic information and process each frame individually. Their performance is compromised due to the lack of temporal information between the frames. To solve this problem, we propose the context motion network to leverage semantic information and motion information. To capture the motion information, we estimate the optical flow and design a context-motion updating operator to integrate features between frames recurrently. Our experiments show that our network outperforms state-of-the-art matting methods significantly on the Video240K SD dataset.
Via