 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Margin Learning in Set to Set Similarity Comparison for Person Re-identification
Paper and Code
Aug 18, 2017
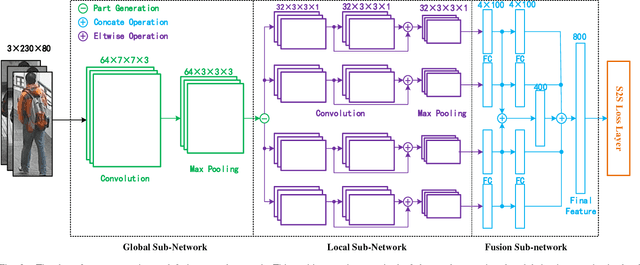
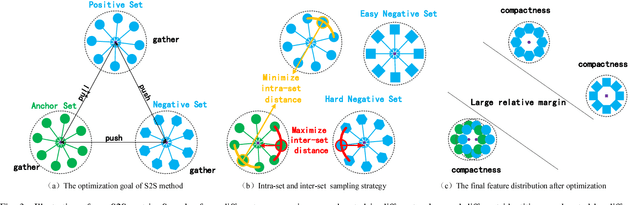
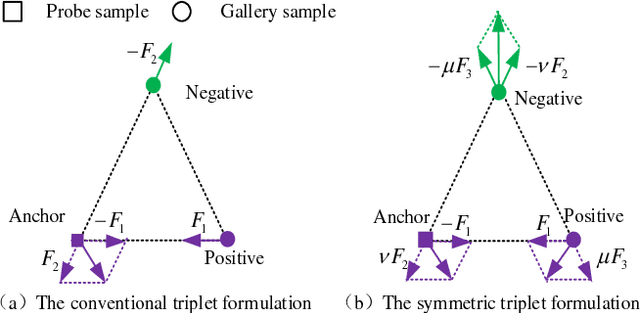
Person re-identification (Re-ID) aims at matching images of the same person across disjoint camera views, which is a challenging problem in multimedia analysis, multimedia editing and content-based media retrieval communities. The major challenge lies in how to preserve similarity of the same person across video footages with large appearance variations, while discriminating different individuals. To address this problem, conventional methods usually consider the pairwise similarity between persons by only measuring the point to point (P2P) distance. In this paper, we propose to use deep learning technique to model a novel set to set (S2S) distance, in which the underline objective focuses on preserving the compactness of intra-class samples for each camera view, while maximizing the margin between the intra-class set and inter-class set. The S2S distance metric is consisted of three terms, namely the class-identity term, the relative distance term and the regularization term. The class-identity term keeps the intra-class samples within each camera view gathering together, the relative distance term maximizes the distance between the intra-class class set and inter-class set across different camera views, and the regularization term smoothness the parameters of deep convolutional neural network (CNN). As a result, the final learned deep model can effectively find out the matched target to the probe object among various candidates in the video gallery by learning discriminative and stable feature representations. Using the CUHK01, CUHK03, PRID2011 and Market1501 benchmark datasets, we extensively conducted comparative evaluations to demonstrate the advantages of our method over the state-of-the-art approaches.