 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAR-IQA: A Lightweight, Accurate, and Robust No-Reference Image Quality Assessment Model
Aug 30, 2024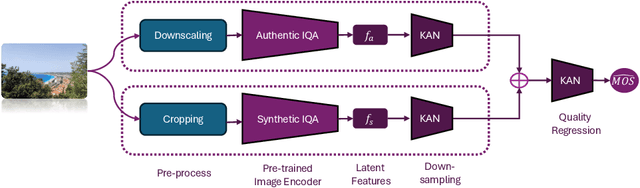
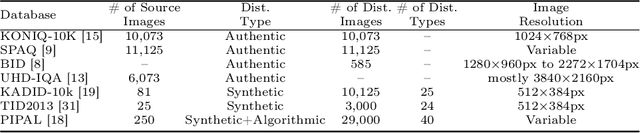
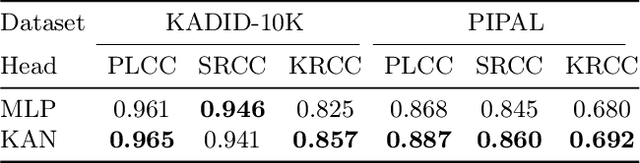
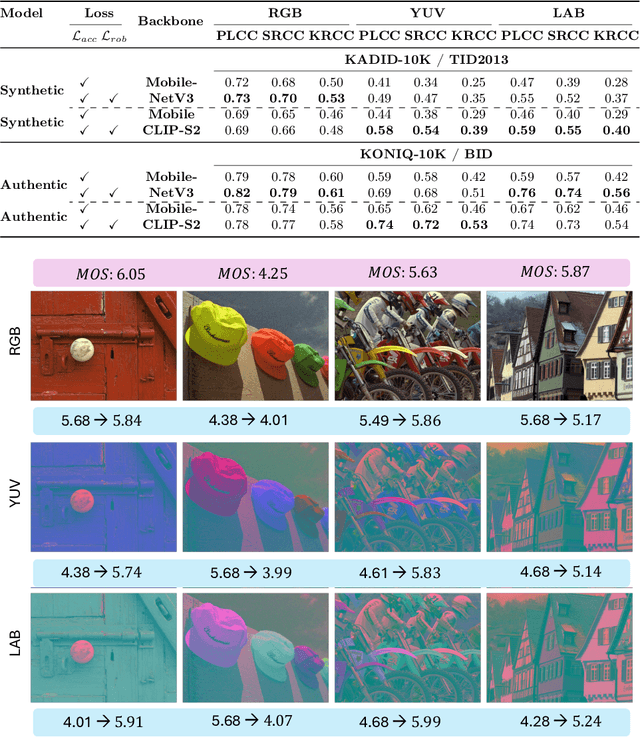
Recent advancements in the field of No-Reference Image Quality Assessment (NR-IQA) using deep learning techniques demonstrate high performance across multiple open-source datasets. However, such models are typically very large and complex making them not so suitable for real-world deployment, especially on resource- and battery-constrained mobile devices. To address this limitation, we propose a compact, lightweight NR-IQA model that achieves state-of-the-art (SOTA) performance on ECCV AIM UHD-IQA challenge validation and test datasets while being also nearly 5.7 times faster than the fastest SOTA model. Our model features a dual-branch architecture, with each branch separately trained on synthetically and authentically distorted images which enhances the model's generalizability across different distortion types. To improve robustness under diverse real-world visual conditions, we additionally incorporate multiple color spaces during the training process. We also demonstrate the higher accuracy of recently proposed Kolmogorov-Arnold Networks (KANs) for final quality regression as compared to the conventional Multi-Layer Perceptrons (MLPs). Our evaluation considering various open-source datasets highlights the practical, high-accuracy, and robust performance of our proposed lightweight model. Code: https://github.com/nasimjamshidi/LAR-IQA.
MSLIQA: Enhancing Learning Representations for Image Quality Assessment through Multi-Scale Learning
Aug 29, 2024No-Reference Image Quality Assessment (NR-IQA) remains a challenging task due to the diversity of distortions and the lack of large annotated datasets. Many studies have attempted to tackle these challenges by developing more accurate NR-IQA models, often employing complex and computationally expensive networks, or by bridging the domain gap between various distortions to enhance performance on test datasets. In our work, we improve the performance of a generic lightweight NR-IQA model by introducing a novel augmentation strategy that boosts its performance by almost 28\%. This augmentation strategy enables the network to better discriminate between different distortions in various parts of the image by zooming in and out. Additionally, the inclusion of test-time augmentation further enhances performance, making our lightweight network's results comparable to the current state-of-the-art models, simply through the use of augmentations.