 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Adaptive Channel Pruning for Communication-Efficient Split Learning
Mar 18, 2026Split learning (SL) transfers most of the training workload to the server, which alleviates computational burden on client devices. However, the transmission of intermediate feature representations, referred to as smashed data, incurs significant communication overhead, particularly when a large number of client devices are involved. To address this challenge, we propose an adaptive channel pruning-aided SL (ACP-SL) scheme. In ACP-SL, a label-aware channel importance scoring (LCIS) module is designed to generate channel importance scores, distinguishing important channels from less important ones. Based on these scores, an adaptive channel pruning (ACP) module is developed to prune less important channels, thereby compressing the corresponding smashed data and reducing the communication overhead. Experimental results show that ACP-SL consistently outperforms benchmark schemes in test accuracy. Furthermore, it reaches a target test accuracy in fewer training rounds, thereby reducing communication overhead.
Exploiting Label-Aware Channel Scoring for Adaptive Channel Pruning in Split Learning
Mar 10, 2026Split learning (SL) transfers most of the training workload to the server, which alleviates computational burden on client devices. However, the transmission of intermediate feature representations, referred to as smashed data, incurs significant communication overhead, particularly when a large number of client devices are involved. To address this challenge, we propose an adaptive channel pruning-aided SL (ACP-SL) scheme. In ACP-SL, a label-aware channel importance scoring (LCIS) module is designed to generate channel importance scores, distinguishing important channels from less important ones. Based on these scores, an adaptive channel pruning (ACP) module is developed to prune less important channels, thereby compressing the corresponding smashed data and reducing the communication overhead. Experimental results show that ACP-SL consistently outperforms benchmark schemes in test accuracy. Furthermore, it reaches a target test accuracy in fewer training rounds, thereby reducing communication overhead.
MWFormer: Multi-Weather Image Restoration Using Degradation-Aware Transformers
Nov 26, 2024



Restoring images captured under adverse weather conditions is a fundamental task for many computer vision applications. However, most existing weather restoration approaches are only capable of handling a specific type of degradation, which is often insufficient in real-world scenarios, such as rainy-snowy or rainy-hazy weather. Towards being able to address these situations, we propose a multi-weather Transformer, or MWFormer for short, which is a holistic vision Transformer that aims to solve multiple weather-induced degradations using a single, unified architecture. MWFormer uses hyper-networks and feature-wise linear modulation blocks to restore images degraded by various weather types using the same set of learned parameters. We first employ contrastive learning to train an auxiliary network that extracts content-independent, distortion-aware feature embeddings that efficiently represent predicted weather types, of which more than one may occur. Guided by these weather-informed predictions, the image restoration Transformer adaptively modulates its parameters to conduct both local and global feature processing, in response to multiple possible weather. Moreover, MWFormer allows for a novel way of tuning, during application, to either a single type of weather restoration or to hybrid weather restoration without any retraining, offering greater controllability than existing methods. Our experimental results on multi-weather restoration benchmarks show that MWFormer achieves significant performance improvements compared to existing state-of-the-art methods, without requiring much computational cost. Moreover, we demonstrate that our methodology of using hyper-networks can be integrated into various network architectures to further boost their performance. The code is available at: https://github.com/taco-group/MWFormer
AIM 2024 Challenge on Compressed Video Quality Assessment: Methods and Results
Aug 21, 2024
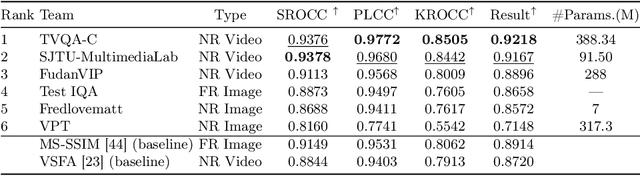
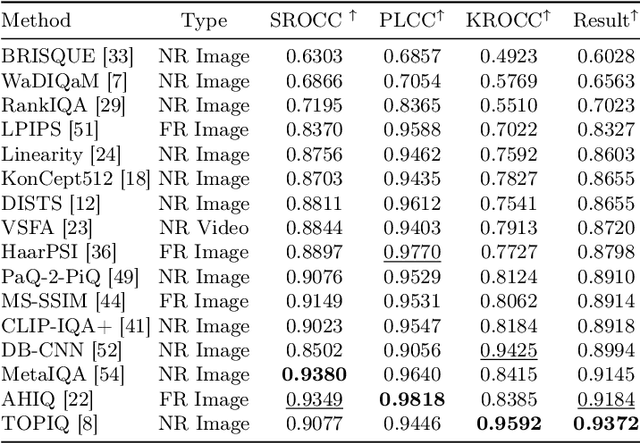
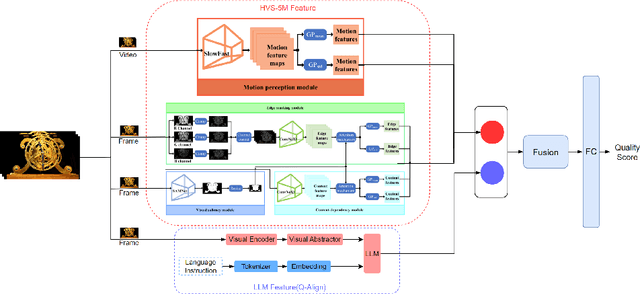
Video quality assessment (VQA) is a crucial task in the development of video compression standards, as it directly impacts the viewer experience. This paper presents the results of the Compressed Video Quality Assessment challenge, held in conjunction with the Advances in Image Manipulation (AIM) workshop at ECCV 2024. The challenge aimed to evaluate the performance of VQA methods on a diverse dataset of 459 videos, encoded with 14 codecs of various compression standards (AVC/H.264, HEVC/H.265, AV1, and VVC/H.266) and containing a comprehensive collection of compression artifacts. To measure the methods performance, we employed traditional correlation coefficients between their predictions and subjective scores, which were collected via large-scale crowdsourced pairwise human comparisons. For training purposes, participants were provided with the Compressed Video Quality Assessment Dataset (CVQAD), a previously developed dataset of 1022 videos. Up to 30 participating teams registered for the challenge, while we report the results of 6 teams, which submitted valid final solutions and code for reproducing the results. Moreover, we calculated and present the performance of state-of-the-art VQA methods on the developed dataset, providing a comprehensive benchmark for future research. The dataset, results, and online leaderboard are publicly available at https://challenges.videoprocessing.ai/challenges/compressed-video-quality-assessment.html.
AIS 2024 Challenge on Video Quality Assessment of User-Generated Content: Methods and Results
Apr 24, 2024



This paper reviews the AIS 2024 Video Quality Assessment (VQA) Challenge, focused on User-Generated Content (UGC). The aim of this challenge is to gather deep learning-based methods capable of estimating the perceptual quality of UGC videos. The user-generated videos from the YouTube UGC Dataset include diverse content (sports, games, lyrics, anime, etc.), quality and resolutions. The proposed methods must process 30 FHD frames under 1 second. In the challenge, a total of 102 participants registered, and 15 submitted code and models. The performance of the top-5 submissions is reviewed and provided here as a survey of diverse deep models for efficient video quality assessment of user-generated content.