 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainable Partial-AIGC Image Quality Assessment
Apr 12, 2025The rapid advancement of AI-driven visual generation technologies has catalyzed significant breakthroughs in image manipulation, particularly in achieving photorealistic localized editing effects on natural scene images (NSIs). Despite extensive research on image quality assessment (IQA) for AI-generated images (AGIs), most studies focus on fully AI-generated outputs (e.g., text-to-image generation), leaving the quality assessment of partial-AIGC images (PAIs)-images with localized AI-driven edits an almost unprecedented field. Motivated by this gap, we construct the first large-scale PAI dataset towards explainable partial-AIGC image quality assessment (EPAIQA), the EPAIQA-15K, which includes 15K images with localized AI manipulation in different regions and over 300K multi-dimensional human ratings. Based on this, we leverage large multi-modal models (LMMs) and propose a three-stage model training paradigm. This paradigm progressively trains the LMM for editing region grounding, quantitative quality scoring, and quality explanation. Finally, we develop the EPAIQA series models, which possess explainable quality feedback capabilities. Our work represents a pioneering effort in the perceptual IQA field for comprehensive PAI quality assessment.
VQA$^2$:Visual Question Answering for Video Quality Assessment
Nov 06, 2024



The advent and proliferation of large multi-modal models (LMMs) have introduced a new paradigm to video-related computer vision fields, including training and inference methods based on visual question answering (VQA). These methods enable models to handle multiple downstream tasks robustly. Video Quality Assessment (VQA), a classic field in low-level visual quality evaluation, originally focused on quantitative video quality scoring. However, driven by advances in LMMs, it is now evolving towards more comprehensive visual quality understanding tasks. Visual question answering has significantly improved low-level visual evaluation within the image domain recently. However, related work is almost nonexistent in the video domain, leaving substantial room for improvement. To address this gap, we introduce the VQA2 Instruction Dataset the first visual question answering instruction dataset entirely focuses on video quality assessment, and based on it, we propose the VQA2 series models The VQA2 Instruction Dataset consists of three stages and covers various video types, containing 157,735 instruction question-answer pairs, including both manually annotated and synthetic data. We conduct extensive experiments on both video quality scoring and video quality understanding tasks. Results demonstrate that the VQA2 series models achieve state-of-the-art (SOTA) performance in quality scoring tasks, and their performance in visual quality question answering surpasses the renowned GPT-4o. Additionally, our final model, the VQA2-Assistant, performs well across both scoring and question-answering tasks, validating its versatility.
AIM 2024 Challenge on Compressed Video Quality Assessment: Methods and Results
Aug 21, 2024
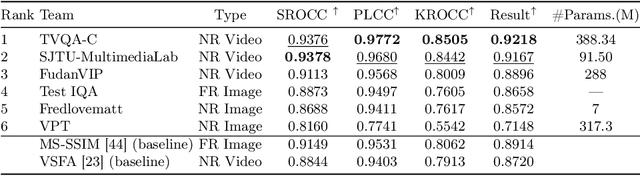
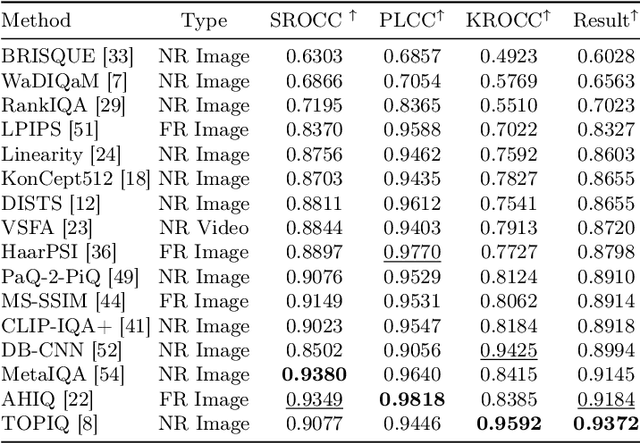
Video quality assessment (VQA) is a crucial task in the development of video compression standards, as it directly impacts the viewer experience. This paper presents the results of the Compressed Video Quality Assessment challenge, held in conjunction with the Advances in Image Manipulation (AIM) workshop at ECCV 2024. The challenge aimed to evaluate the performance of VQA methods on a diverse dataset of 459 videos, encoded with 14 codecs of various compression standards (AVC/H.264, HEVC/H.265, AV1, and VVC/H.266) and containing a comprehensive collection of compression artifacts. To measure the methods performance, we employed traditional correlation coefficients between their predictions and subjective scores, which were collected via large-scale crowdsourced pairwise human comparisons. For training purposes, participants were provided with the Compressed Video Quality Assessment Dataset (CVQAD), a previously developed dataset of 1022 videos. Up to 30 participating teams registered for the challenge, while we report the results of 6 teams, which submitted valid final solutions and code for reproducing the results. Moreover, we calculated and present the performance of state-of-the-art VQA methods on the developed dataset, providing a comprehensive benchmark for future research. The dataset, results, and online leaderboard are publicly available at https://challenges.videoprocessing.ai/challenges/compressed-video-quality-assessment.html.