 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Intrinsic Scale Assessment: Bridging the Gap Between Quality and Resolution
Feb 10, 2025



Image Quality Assessment (IQA) measures and predicts perceived image quality by human observers. Although recent studies have highlighted the critical influence that variations in the scale of an image have on its perceived quality, this relationship has not been systematically quantified. To bridge this gap, we introduce the Image Intrinsic Scale (IIS), defined as the largest scale where an image exhibits its highest perceived quality. We also present the Image Intrinsic Scale Assessment (IISA) task, which involves subjectively measuring and predicting the IIS based on human judgments. We develop a subjective annotation methodology and create the IISA-DB dataset, comprising 785 image-IIS pairs annotated by experts in a rigorously controlled crowdsourcing study. Furthermore, we propose WIISA (Weak-labeling for Image Intrinsic Scale Assessment), a strategy that leverages how the IIS of an image varies with downscaling to generate weak labels. Experiments show that applying WIISA during the training of several IQA methods adapted for IISA consistently improves the performance compared to using only ground-truth labels. We will release the code, dataset, and pre-trained models upon acceptance.
Cross the Gap: Exposing the Intra-modal Misalignment in CLIP via Modality Inversion
Feb 06, 2025



Pre-trained multi-modal Vision-Language Models like CLIP are widely used off-the-shelf for a variety of applications. In this paper, we show that the common practice of individually exploiting the text or image encoders of these powerful multi-modal models is highly suboptimal for intra-modal tasks like image-to-image retrieval. We argue that this is inherently due to the CLIP-style inter-modal contrastive loss that does not enforce any intra-modal constraints, leading to what we call intra-modal misalignment. To demonstrate this, we leverage two optimization-based modality inversion techniques that map representations from their input modality to the complementary one without any need for auxiliary data or additional trained adapters. We empirically show that, in the intra-modal tasks of image-to-image and text-to-text retrieval, approaching these tasks inter-modally significantly improves performance with respect to intra-modal baselines on more than fifteen datasets. Additionally, we demonstrate that approaching a native inter-modal task (e.g. zero-shot image classification) intra-modally decreases performance, further validating our findings. Finally, we show that incorporating an intra-modal term in the pre-training objective or narrowing the modality gap between the text and image feature embedding spaces helps reduce the intra-modal misalignment. The code is publicly available at: https://github.com/miccunifi/Cross-the-Gap.
AIM 2024 Challenge on UHD Blind Photo Quality Assessment
Sep 24, 2024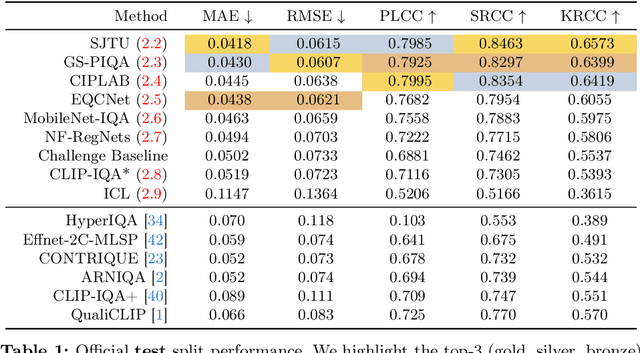
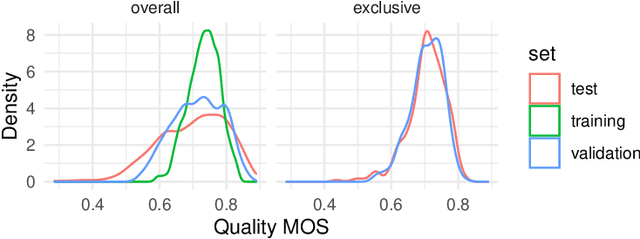
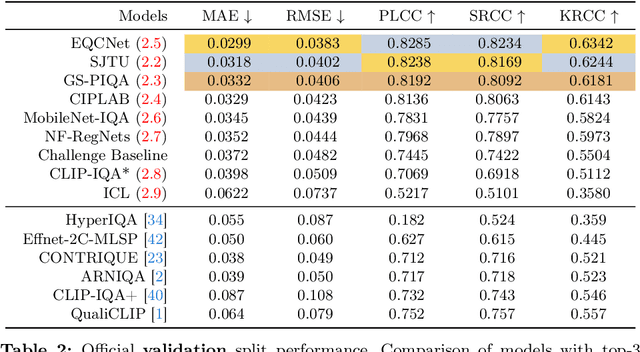
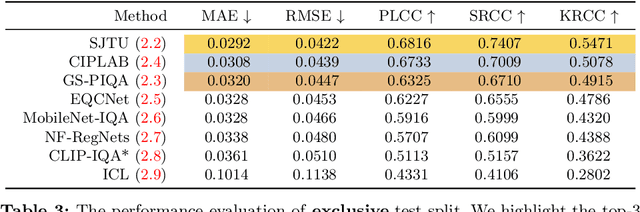
We introduce the AIM 2024 UHD-IQA Challenge, a competition to advance the No-Reference Image Quality Assessment (NR-IQA) task for modern, high-resolution photos. The challenge is based on the recently released UHD-IQA Benchmark Database, which comprises 6,073 UHD-1 (4K) images annotated with perceptual quality ratings from expert raters. Unlike previous NR-IQA datasets, UHD-IQA focuses on highly aesthetic photos of superior technical quality, reflecting the ever-increasing standards of digital photography. This challenge aims to develop efficient and effective NR-IQA models. Participants are tasked with creating novel architectures and training strategies to achieve high predictive performance on UHD-1 images within a computational budget of 50G MACs. This enables model deployment on edge devices and scalable processing of extensive image collections. Winners are determined based on a combination of performance metrics, including correlation measures (SRCC, PLCC, KRCC), absolute error metrics (MAE, RMSE), and computational efficiency (G MACs). To excel in this challenge, participants leverage techniques like knowledge distillation, low-precision inference, and multi-scale training. By pushing the boundaries of NR-IQA for high-resolution photos, the UHD-IQA Challenge aims to stimulate the development of practical models that can keep pace with the rapidly evolving landscape of digital photography. The innovative solutions emerging from this competition will have implications for various applications, from photo curation and enhancement to image compression.
UHD-IQA Benchmark Database: Pushing the Boundaries of Blind Photo Quality Assessment
Jun 25, 2024We introduce a novel Image Quality Assessment (IQA) dataset comprising 6073 UHD-1 (4K) images, annotated at a fixed width of 3840 pixels. Contrary to existing No-Reference (NR) IQA datasets, ours focuses on highly aesthetic photos of high technical quality, filling a gap in the literature. The images, carefully curated to exclude synthetic content, are sufficiently diverse to train general NR-IQA models. The dataset is annotated with perceptual quality ratings obtained through a crowdsourcing study. Ten expert raters, comprising photographers and graphics artists, assessed each image at least twice in multiple sessions spanning several days, resulting in highly reliable labels. Annotators were rigorously selected based on several metrics, including self-consistency, to ensure their reliability. The dataset includes rich metadata with user and machine-generated tags from over 5,000 categories and popularity indicators such as favorites, likes, downloads, and views. With its unique characteristics, such as its focus on high-quality images, reliable crowdsourced annotations, and high annotation resolution, our dataset opens up new opportunities for advancing perceptual image quality assessment research and developing practical NR-IQA models that apply to modern photos. Our dataset is available at https://database.mmsp-kn.de/uhd-iqa-benchmark-database.html
iSEARLE: Improving Textual Inversion for Zero-Shot Composed Image Retrieval
May 05, 2024Given a query consisting of a reference image and a relative caption, Composed Image Retrieval (CIR) aims to retrieve target images visually similar to the reference one while incorporating the changes specified in the relative caption. The reliance of supervised methods on labor-intensive manually labeled datasets hinders their broad applicability. In this work, we introduce a new task, Zero-Shot CIR (ZS-CIR), that addresses CIR without the need for a labeled training dataset. We propose an approach named iSEARLE (improved zero-Shot composEd imAge Retrieval with textuaL invErsion) that involves mapping the visual information of the reference image into a pseudo-word token in CLIP token embedding space and combining it with the relative caption. To foster research on ZS-CIR, we present an open-domain benchmarking dataset named CIRCO (Composed Image Retrieval on Common Objects in context), the first CIR dataset where each query is labeled with multiple ground truths and a semantic categorization. The experimental results illustrate that iSEARLE obtains state-of-the-art performance on three different CIR datasets -- FashionIQ, CIRR, and the proposed CIRCO -- and two additional evaluation settings, namely domain conversion and object composition. The dataset, the code, and the model are publicly available at https://github.com/miccunifi/SEARLE.
Quality-Aware Image-Text Alignment for Real-World Image Quality Assessment
Mar 17, 2024No-Reference Image Quality Assessment (NR-IQA) focuses on designing methods to measure image quality in alignment with human perception when a high-quality reference image is unavailable. The reliance on annotated Mean Opinion Scores (MOS) in the majority of state-of-the-art NR-IQA approaches limits their scalability and broader applicability to real-world scenarios. To overcome this limitation, we propose QualiCLIP (Quality-aware CLIP), a CLIP-based self-supervised opinion-unaware method that does not require labeled MOS. In particular, we introduce a quality-aware image-text alignment strategy to make CLIP generate representations that correlate with the inherent quality of the images. Starting from pristine images, we synthetically degrade them with increasing levels of intensity. Then, we train CLIP to rank these degraded images based on their similarity to quality-related antonym text prompts, while guaranteeing consistent representations for images with comparable quality. Our method achieves state-of-the-art performance on several datasets with authentic distortions. Moreover, despite not requiring MOS, QualiCLIP outperforms supervised methods when their training dataset differs from the testing one, thus proving to be more suitable for real-world scenarios. Furthermore, our approach demonstrates greater robustness and improved explainability than competing methods. The code and the model are publicly available at https://github.com/miccunifi/QualiCLIP.
Perceptual Quality Improvement in Videoconferencing using Keyframes-based GAN
Nov 07, 2023In the latest years, videoconferencing has taken a fundamental role in interpersonal relations, both for personal and business purposes. Lossy video compression algorithms are the enabling technology for videoconferencing, as they reduce the bandwidth required for real-time video streaming. However, lossy video compression decreases the perceived visual quality. Thus, many techniques for reducing compression artifacts and improving video visual quality have been proposed in recent years. In this work, we propose a novel GAN-based method for compression artifacts reduction in videoconferencing. Given that, in this context, the speaker is typically in front of the camera and remains the same for the entire duration of the transmission, we can maintain a set of reference keyframes of the person from the higher-quality I-frames that are transmitted within the video stream and exploit them to guide the visual quality improvement; a novel aspect of this approach is the update policy that maintains and updates a compact and effective set of reference keyframes. First, we extract multi-scale features from the compressed and reference frames. Then, our architecture combines these features in a progressive manner according to facial landmarks. This allows the restoration of the high-frequency details lost after the video compression. Experiments show that the proposed approach improves visual quality and generates photo-realistic results even with high compression rates. Code and pre-trained networks are publicly available at https://github.com/LorenzoAgnolucci/Keyframes-GAN.
Restoration of Analog Videos Using Swin-UNet
Nov 07, 2023In this paper, we present a system to restore analog videos of historical archives. These videos often contain severe visual degradation due to the deterioration of their tape supports that require costly and slow manual interventions to recover the original content. The proposed system uses a multi-frame approach and is able to deal with severe tape mistracking, which results in completely scrambled frames. Tests on real-world videos from a major historical video archive show the effectiveness of our demo system. The code and the pre-trained model are publicly available at https://github.com/miccunifi/analog-video-restoration.
Reference-based Restoration of Digitized Analog Videotapes
Nov 03, 2023Analog magnetic tapes have been the main video data storage device for several decades. Videos stored on analog videotapes exhibit unique degradation patterns caused by tape aging and reader device malfunctioning that are different from those observed in film and digital video restoration tasks. In this work, we present a reference-based approach for the resToration of digitized Analog videotaPEs (TAPE). We leverage CLIP for zero-shot artifact detection to identify the cleanest frames of each video through textual prompts describing different artifacts. Then, we select the clean frames most similar to the input ones and employ them as references. We design a transformer-based Swin-UNet network that exploits both neighboring and reference frames via our Multi-Reference Spatial Feature Fusion (MRSFF) blocks. MRSFF blocks rely on cross-attention and attention pooling to take advantage of the most useful parts of each reference frame. To address the absence of ground truth in real-world videos, we create a synthetic dataset of videos exhibiting artifacts that closely resemble those commonly found in analog videotapes. Both quantitative and qualitative experiments show the effectiveness of our approach compared to other state-of-the-art methods. The code, the model, and the synthetic dataset are publicly available at https://github.com/miccunifi/TAPE.
ARNIQA: Learning Distortion Manifold for Image Quality Assessment
Oct 20, 2023No-Reference Image Quality Assessment (NR-IQA) aims to develop methods to measure image quality in alignment with human perception without the need for a high-quality reference image. In this work, we propose a self-supervised approach named ARNIQA (leArning distoRtion maNifold for Image Quality Assessment) for modeling the image distortion manifold to obtain quality representations in an intrinsic manner. First, we introduce an image degradation model that randomly composes ordered sequences of consecutively applied distortions. In this way, we can synthetically degrade images with a large variety of degradation patterns. Second, we propose to train our model by maximizing the similarity between the representations of patches of different images distorted equally, despite varying content. Therefore, images degraded in the same manner correspond to neighboring positions within the distortion manifold. Finally, we map the image representations to the quality scores with a simple linear regressor, thus without fine-tuning the encoder weights. The experiments show that our approach achieves state-of-the-art performance on several datasets. In addition, ARNIQA demonstrates improved data efficiency, generalization capabilities, and robustness compared to competing methods. The code and the model are publicly available at https://github.com/miccunifi/ARNIQA.