 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross the Gap: Exposing the Intra-modal Misalignment in CLIP via Modality Inversion
Feb 06, 2025



Pre-trained multi-modal Vision-Language Models like CLIP are widely used off-the-shelf for a variety of applications. In this paper, we show that the common practice of individually exploiting the text or image encoders of these powerful multi-modal models is highly suboptimal for intra-modal tasks like image-to-image retrieval. We argue that this is inherently due to the CLIP-style inter-modal contrastive loss that does not enforce any intra-modal constraints, leading to what we call intra-modal misalignment. To demonstrate this, we leverage two optimization-based modality inversion techniques that map representations from their input modality to the complementary one without any need for auxiliary data or additional trained adapters. We empirically show that, in the intra-modal tasks of image-to-image and text-to-text retrieval, approaching these tasks inter-modally significantly improves performance with respect to intra-modal baselines on more than fifteen datasets. Additionally, we demonstrate that approaching a native inter-modal task (e.g. zero-shot image classification) intra-modally decreases performance, further validating our findings. Finally, we show that incorporating an intra-modal term in the pre-training objective or narrowing the modality gap between the text and image feature embedding spaces helps reduce the intra-modal misalignment. The code is publicly available at: https://github.com/miccunifi/Cross-the-Gap.
RE-tune: Incremental Fine Tuning of Biomedical Vision-Language Models for Multi-label Chest X-ray Classification
Oct 23, 2024In this paper we introduce RE-tune, a novel approach for fine-tuning pre-trained Multimodal Biomedical Vision-Language models (VLMs) in Incremental Learning scenarios for multi-label chest disease diagnosis. RE-tune freezes the backbones and only trains simple adaptors on top of the Image and Text encoders of the VLM. By engineering positive and negative text prompts for diseases, we leverage the ability of Large Language Models to steer the training trajectory. We evaluate RE-tune in three realistic incremental learning scenarios: class-incremental, label-incremental, and data-incremental. Our results demonstrate that Biomedical VLMs are natural continual learners and prevent catastrophic forgetting. RE-tune not only achieves accurate multi-label classification results, but also prioritizes patient privacy and it distinguishes itself through exceptional computational efficiency, rendering it highly suitable for broad adoption in real-world healthcare settings.
Improving Zero-shot Generalization of Learned Prompts via Unsupervised Knowledge Distillation
Jul 03, 2024
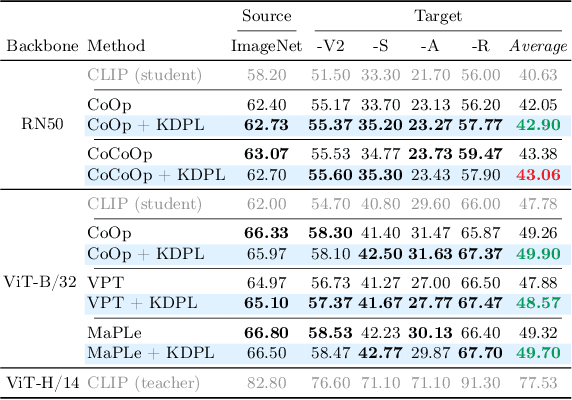

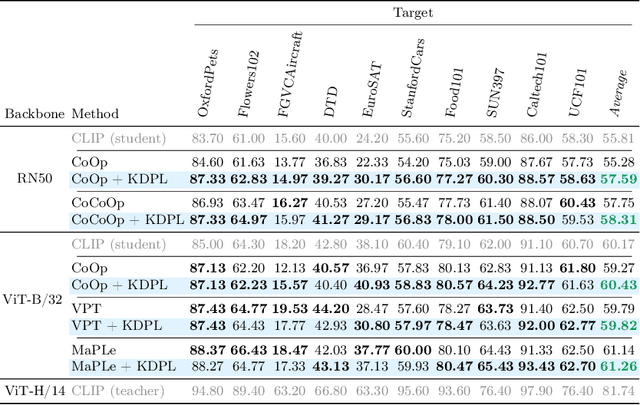
Vision-Language Models (VLMs) demonstrate remarkable zero-shot generalization to unseen tasks, but fall short of the performance of supervised methods in generalizing to downstream tasks with limited data. Prompt learning is emerging as a parameter-efficient method for adapting VLMs, but state-of-the-art approaches require annotated samples. In this paper we propose a novel approach to prompt learning based on unsupervised knowledge distillation from more powerful models. Our approach, which we call Knowledge Distillation Prompt Learning (KDPL), can be integrated into existing prompt learning techniques and eliminates the need for labeled examples during adaptation. Our experiments on more than ten standard benchmark datasets demonstrate that KDPL is very effective at improving generalization of learned prompts for zero-shot domain generalization, zero-shot cross-dataset generalization, and zero-shot base-to-novel class generalization problems. KDPL requires no ground-truth labels for adaptation, and moreover we show that even in the absence of any knowledge of training class names it can be used to effectively transfer knowledge. The code is publicly available at https://github.com/miccunifi/KDPL.