 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRE-tune: Incremental Fine Tuning of Biomedical Vision-Language Models for Multi-label Chest X-ray Classification
Paper and Code
Oct 23, 2024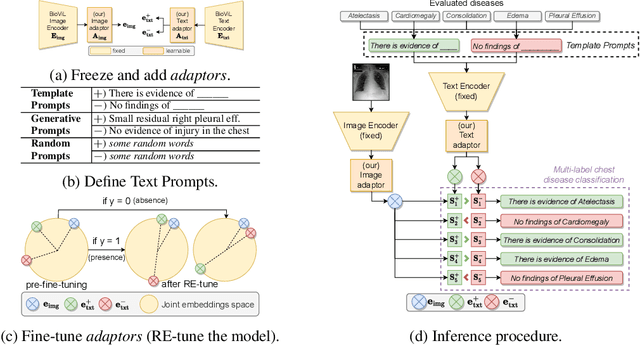

In this paper we introduce RE-tune, a novel approach for fine-tuning pre-trained Multimodal Biomedical Vision-Language models (VLMs) in Incremental Learning scenarios for multi-label chest disease diagnosis. RE-tune freezes the backbones and only trains simple adaptors on top of the Image and Text encoders of the VLM. By engineering positive and negative text prompts for diseases, we leverage the ability of Large Language Models to steer the training trajectory. We evaluate RE-tune in three realistic incremental learning scenarios: class-incremental, label-incremental, and data-incremental. Our results demonstrate that Biomedical VLMs are natural continual learners and prevent catastrophic forgetting. RE-tune not only achieves accurate multi-label classification results, but also prioritizes patient privacy and it distinguishes itself through exceptional computational efficiency, rendering it highly suitable for broad adoption in real-world healthcare settings.