 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISion On Request: Enhanced VLLM efficiency with sparse, dynamically selected, vision-language interactions
Mar 24, 2026Existing approaches for improving the efficiency of Large Vision-Language Models (LVLMs) are largely based on the concept of visual token reduction. This approach, however, creates an information bottleneck that impairs performance, especially on challenging tasks that require fine-grained understanding and reasoning. In this work, we challenge this paradigm by introducing VISion On Request (VISOR), a method that reduces inference cost without discarding visual information. Instead of compressing the image, VISOR improves efficiency by sparsifying the interaction between image and text tokens. Specifically, the language model attends to the full set of high-resolution visual tokens through a small, strategically placed set of attention layers: general visual context is provided by efficient cross-attention between text-image, while a few well-placed and dynamically selected self-attention layers refine the visual representations themselves, enabling complex, high-resolution reasoning when needed. Based on this principle, we first train a single universal network on a range of computational budgets by varying the number of self-attention layers, and then introduce a lightweight policy mechanism that dynamically allocates visual computation based on per-sample complexity. Extensive experiments show that VISOR drastically reduces computational cost while matching or exceeding state-of-the-art results across a diverse suite of benchmarks, and excels in challenging tasks that require detailed visual understanding.
More Images, More Problems? A Controlled Analysis of VLM Failure Modes
Jan 12, 2026Large Vision Language Models (LVLMs) have demonstrated remarkable capabilities, yet their proficiency in understanding and reasoning over multiple images remains largely unexplored. While existing benchmarks have initiated the evaluation of multi-image models, a comprehensive analysis of their core weaknesses and their causes is still lacking. In this work, we introduce MIMIC (Multi-Image Model Insights and Challenges), a new benchmark designed to rigorously evaluate the multi-image capabilities of LVLMs. Using MIMIC, we conduct a series of diagnostic experiments that reveal pervasive issues: LVLMs often fail to aggregate information across images and struggle to track or attend to multiple concepts simultaneously. To address these failures, we propose two novel complementary remedies. On the data side, we present a procedural data-generation strategy that composes single-image annotations into rich, targeted multi-image training examples. On the optimization side, we analyze layer-wise attention patterns and derive an attention-masking scheme tailored for multi-image inputs. Experiments substantially improved cross-image aggregation, while also enhancing performance on existing multi-image benchmarks, outperforming prior state of the art across tasks. Data and code will be made available at https://github.com/anurag-198/MIMIC.
Cross the Gap: Exposing the Intra-modal Misalignment in CLIP via Modality Inversion
Feb 06, 2025



Pre-trained multi-modal Vision-Language Models like CLIP are widely used off-the-shelf for a variety of applications. In this paper, we show that the common practice of individually exploiting the text or image encoders of these powerful multi-modal models is highly suboptimal for intra-modal tasks like image-to-image retrieval. We argue that this is inherently due to the CLIP-style inter-modal contrastive loss that does not enforce any intra-modal constraints, leading to what we call intra-modal misalignment. To demonstrate this, we leverage two optimization-based modality inversion techniques that map representations from their input modality to the complementary one without any need for auxiliary data or additional trained adapters. We empirically show that, in the intra-modal tasks of image-to-image and text-to-text retrieval, approaching these tasks inter-modally significantly improves performance with respect to intra-modal baselines on more than fifteen datasets. Additionally, we demonstrate that approaching a native inter-modal task (e.g. zero-shot image classification) intra-modally decreases performance, further validating our findings. Finally, we show that incorporating an intra-modal term in the pre-training objective or narrowing the modality gap between the text and image feature embedding spaces helps reduce the intra-modal misalignment. The code is publicly available at: https://github.com/miccunifi/Cross-the-Gap.
Improving Zero-shot Generalization of Learned Prompts via Unsupervised Knowledge Distillation
Jul 03, 2024
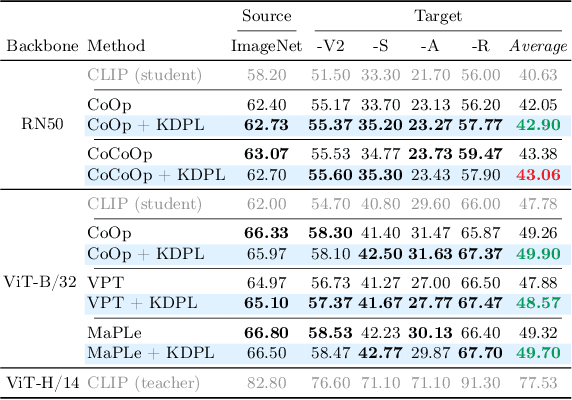

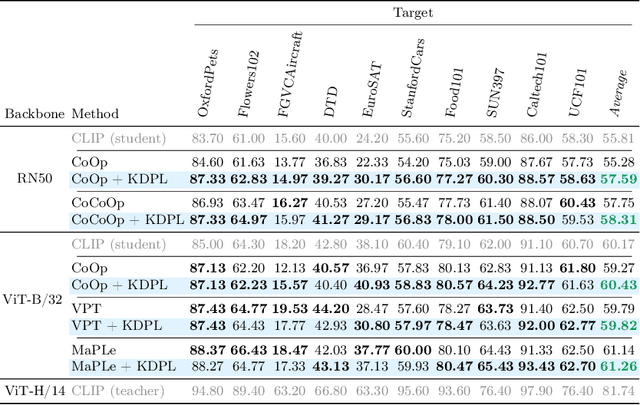
Vision-Language Models (VLMs) demonstrate remarkable zero-shot generalization to unseen tasks, but fall short of the performance of supervised methods in generalizing to downstream tasks with limited data. Prompt learning is emerging as a parameter-efficient method for adapting VLMs, but state-of-the-art approaches require annotated samples. In this paper we propose a novel approach to prompt learning based on unsupervised knowledge distillation from more powerful models. Our approach, which we call Knowledge Distillation Prompt Learning (KDPL), can be integrated into existing prompt learning techniques and eliminates the need for labeled examples during adaptation. Our experiments on more than ten standard benchmark datasets demonstrate that KDPL is very effective at improving generalization of learned prompts for zero-shot domain generalization, zero-shot cross-dataset generalization, and zero-shot base-to-novel class generalization problems. KDPL requires no ground-truth labels for adaptation, and moreover we show that even in the absence of any knowledge of training class names it can be used to effectively transfer knowledge. The code is publicly available at https://github.com/miccunifi/KDPL.
iSEARLE: Improving Textual Inversion for Zero-Shot Composed Image Retrieval
May 05, 2024Given a query consisting of a reference image and a relative caption, Composed Image Retrieval (CIR) aims to retrieve target images visually similar to the reference one while incorporating the changes specified in the relative caption. The reliance of supervised methods on labor-intensive manually labeled datasets hinders their broad applicability. In this work, we introduce a new task, Zero-Shot CIR (ZS-CIR), that addresses CIR without the need for a labeled training dataset. We propose an approach named iSEARLE (improved zero-Shot composEd imAge Retrieval with textuaL invErsion) that involves mapping the visual information of the reference image into a pseudo-word token in CLIP token embedding space and combining it with the relative caption. To foster research on ZS-CIR, we present an open-domain benchmarking dataset named CIRCO (Composed Image Retrieval on Common Objects in context), the first CIR dataset where each query is labeled with multiple ground truths and a semantic categorization. The experimental results illustrate that iSEARLE obtains state-of-the-art performance on three different CIR datasets -- FashionIQ, CIRR, and the proposed CIRCO -- and two additional evaluation settings, namely domain conversion and object composition. The dataset, the code, and the model are publicly available at https://github.com/miccunifi/SEARLE.
Multimodal-Conditioned Latent Diffusion Models for Fashion Image Editing
Mar 25, 2024Fashion illustration is a crucial medium for designers to convey their creative vision and transform design concepts into tangible representations that showcase the interplay between clothing and the human body. In the context of fashion design, computer vision techniques have the potential to enhance and streamline the design process. Departing from prior research primarily focused on virtual try-on, this paper tackles the task of multimodal-conditioned fashion image editing. Our approach aims to generate human-centric fashion images guided by multimodal prompts, including text, human body poses, garment sketches, and fabric textures. To address this problem, we propose extending latent diffusion models to incorporate these multiple modalities and modifying the structure of the denoising network, taking multimodal prompts as input. To condition the proposed architecture on fabric textures, we employ textual inversion techniques and let diverse cross-attention layers of the denoising network attend to textual and texture information, thus incorporating different granularity conditioning details. Given the lack of datasets for the task, we extend two existing fashion datasets, Dress Code and VITON-HD, with multimodal annotations. Experimental evaluations demonstrate the effectiveness of our proposed approach in terms of realism and coherence concerning the provided multimodal inputs.
Mapping Memes to Words for Multimodal Hateful Meme Classification
Oct 12, 2023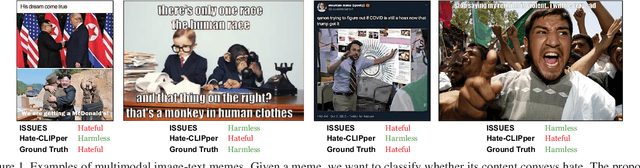
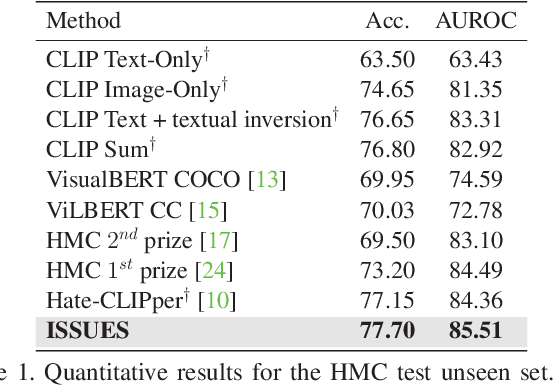
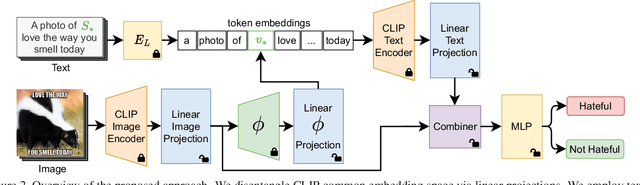
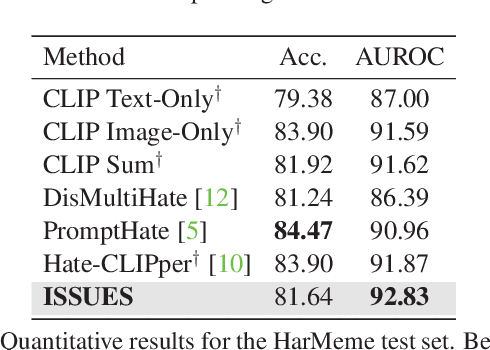
Multimodal image-text memes are prevalent on the internet, serving as a unique form of communication that combines visual and textual elements to convey humor, ideas, or emotions. However, some memes take a malicious turn, promoting hateful content and perpetuating discrimination. Detecting hateful memes within this multimodal context is a challenging task that requires understanding the intertwined meaning of text and images. In this work, we address this issue by proposing a novel approach named ISSUES for multimodal hateful meme classification. ISSUES leverages a pre-trained CLIP vision-language model and the textual inversion technique to effectively capture the multimodal semantic content of the memes. The experiments show that our method achieves state-of-the-art results on the Hateful Memes Challenge and HarMeme datasets. The code and the pre-trained models are publicly available at https://github.com/miccunifi/ISSUES.
Exploiting CLIP-based Multi-modal Approach for Artwork Classification and Retrieval
Sep 21, 2023Given the recent advances in multimodal image pretraining where visual models trained with semantically dense textual supervision tend to have better generalization capabilities than those trained using categorical attributes or through unsupervised techniques, in this work we investigate how recent CLIP model can be applied in several tasks in artwork domain. We perform exhaustive experiments on the NoisyArt dataset which is a dataset of artwork images crawled from public resources on the web. On such dataset CLIP achieves impressive results on (zero-shot) classification and promising results in both artwork-to-artwork and description-to-artwork domain.
OpenFashionCLIP: Vision-and-Language Contrastive Learning with Open-Source Fashion Data
Sep 11, 2023The inexorable growth of online shopping and e-commerce demands scalable and robust machine learning-based solutions to accommodate customer requirements. In the context of automatic tagging classification and multimodal retrieval, prior works either defined a low generalizable supervised learning approach or more reusable CLIP-based techniques while, however, training on closed source data. In this work, we propose OpenFashionCLIP, a vision-and-language contrastive learning method that only adopts open-source fashion data stemming from diverse domains, and characterized by varying degrees of specificity. Our approach is extensively validated across several tasks and benchmarks, and experimental results highlight a significant out-of-domain generalization capability and consistent improvements over state-of-the-art methods both in terms of accuracy and recall. Source code and trained models are publicly available at: https://github.com/aimagelab/open-fashion-clip.
Composed Image Retrieval using Contrastive Learning and Task-oriented CLIP-based Features
Aug 22, 2023Given a query composed of a reference image and a relative caption, the Composed Image Retrieval goal is to retrieve images visually similar to the reference one that integrates the modifications expressed by the caption. Given that recent research has demonstrated the efficacy of large-scale vision and language pre-trained (VLP) models in various tasks, we rely on features from the OpenAI CLIP model to tackle the considered task. We initially perform a task-oriented fine-tuning of both CLIP encoders using the element-wise sum of visual and textual features. Then, in the second stage, we train a Combiner network that learns to combine the image-text features integrating the bimodal information and providing combined features used to perform the retrieval. We use contrastive learning in both stages of training. Starting from the bare CLIP features as a baseline, experimental results show that the task-oriented fine-tuning and the carefully crafted Combiner network are highly effective and outperform more complex state-of-the-art approaches on FashionIQ and CIRR, two popular and challenging datasets for composed image retrieval. Code and pre-trained models are available at https://github.com/ABaldrati/CLIP4Cir