 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECO: Ensembling Context Optimization for Vision-Language Models
Jul 26, 2023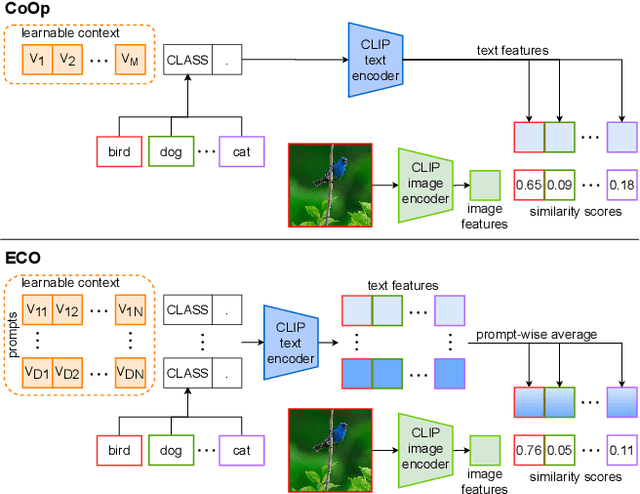
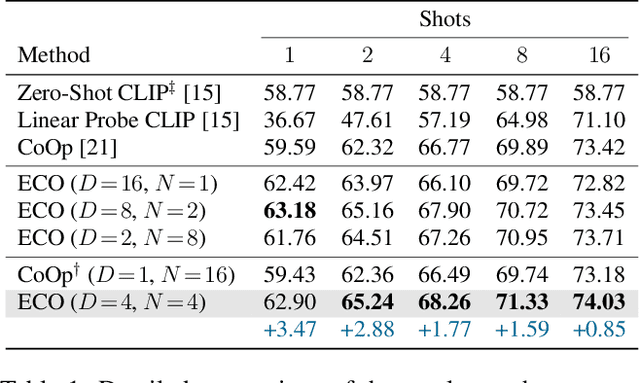
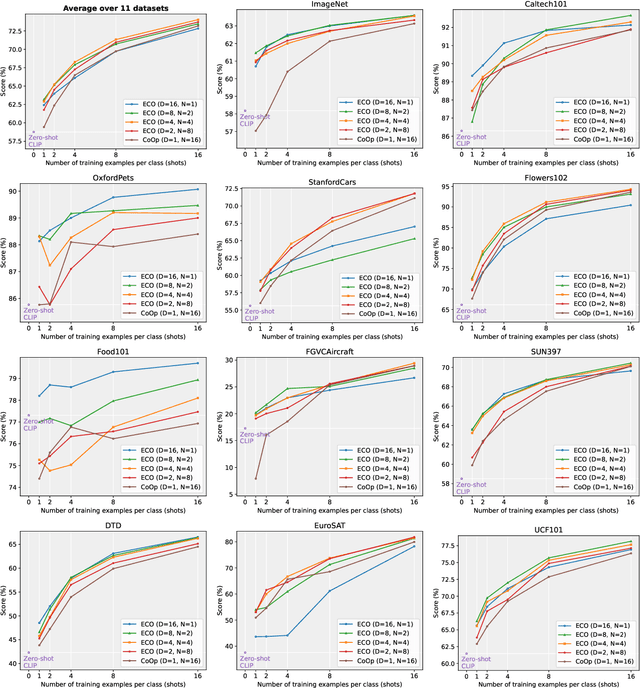
Image recognition has recently witnessed a paradigm shift, where vision-language models are now used to perform few-shot classification based on textual prompts. Among these, the CLIP model has shown remarkable capabilities for zero-shot transfer by matching an image and a custom textual prompt in its latent space. This has paved the way for several works that focus on engineering or learning textual contexts for maximizing CLIP's classification capabilities. In this paper, we follow this trend by learning an ensemble of prompts for image classification. We show that learning diverse and possibly shorter contexts improves considerably and consistently the results rather than relying on a single trainable prompt. In particular, we report better few-shot capabilities with no additional cost at inference time. We demonstrate the capabilities of our approach on 11 different benchmarks.