 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashion-RAG: Multimodal Fashion Image Editing via Retrieval-Augmented Generation
Apr 18, 2025



In recent years, the fashion industry has increasingly adopted AI technologies to enhance customer experience, driven by the proliferation of e-commerce platforms and virtual applications. Among the various tasks, virtual try-on and multimodal fashion image editing -- which utilizes diverse input modalities such as text, garment sketches, and body poses -- have become a key area of research. Diffusion models have emerged as a leading approach for such generative tasks, offering superior image quality and diversity. However, most existing virtual try-on methods rely on having a specific garment input, which is often impractical in real-world scenarios where users may only provide textual specifications. To address this limitation, in this work we introduce Fashion Retrieval-Augmented Generation (Fashion-RAG), a novel method that enables the customization of fashion items based on user preferences provided in textual form. Our approach retrieves multiple garments that match the input specifications and generates a personalized image by incorporating attributes from the retrieved items. To achieve this, we employ textual inversion techniques, where retrieved garment images are projected into the textual embedding space of the Stable Diffusion text encoder, allowing seamless integration of retrieved elements into the generative process. Experimental results on the Dress Code dataset demonstrate that Fashion-RAG outperforms existing methods both qualitatively and quantitatively, effectively capturing fine-grained visual details from retrieved garments. To the best of our knowledge, this is the first work to introduce a retrieval-augmented generation approach specifically tailored for multimodal fashion image editing.
Multimodal-Conditioned Latent Diffusion Models for Fashion Image Editing
Mar 25, 2024Fashion illustration is a crucial medium for designers to convey their creative vision and transform design concepts into tangible representations that showcase the interplay between clothing and the human body. In the context of fashion design, computer vision techniques have the potential to enhance and streamline the design process. Departing from prior research primarily focused on virtual try-on, this paper tackles the task of multimodal-conditioned fashion image editing. Our approach aims to generate human-centric fashion images guided by multimodal prompts, including text, human body poses, garment sketches, and fabric textures. To address this problem, we propose extending latent diffusion models to incorporate these multiple modalities and modifying the structure of the denoising network, taking multimodal prompts as input. To condition the proposed architecture on fabric textures, we employ textual inversion techniques and let diverse cross-attention layers of the denoising network attend to textual and texture information, thus incorporating different granularity conditioning details. Given the lack of datasets for the task, we extend two existing fashion datasets, Dress Code and VITON-HD, with multimodal annotations. Experimental evaluations demonstrate the effectiveness of our proposed approach in terms of realism and coherence concerning the provided multimodal inputs.
OpenFashionCLIP: Vision-and-Language Contrastive Learning with Open-Source Fashion Data
Sep 11, 2023The inexorable growth of online shopping and e-commerce demands scalable and robust machine learning-based solutions to accommodate customer requirements. In the context of automatic tagging classification and multimodal retrieval, prior works either defined a low generalizable supervised learning approach or more reusable CLIP-based techniques while, however, training on closed source data. In this work, we propose OpenFashionCLIP, a vision-and-language contrastive learning method that only adopts open-source fashion data stemming from diverse domains, and characterized by varying degrees of specificity. Our approach is extensively validated across several tasks and benchmarks, and experimental results highlight a significant out-of-domain generalization capability and consistent improvements over state-of-the-art methods both in terms of accuracy and recall. Source code and trained models are publicly available at: https://github.com/aimagelab/open-fashion-clip.
LaDI-VTON: Latent Diffusion Textual-Inversion Enhanced Virtual Try-On
May 22, 2023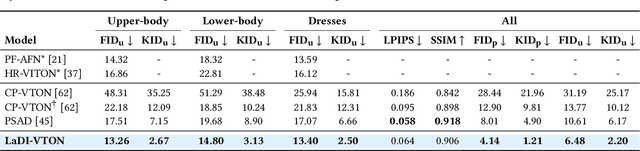
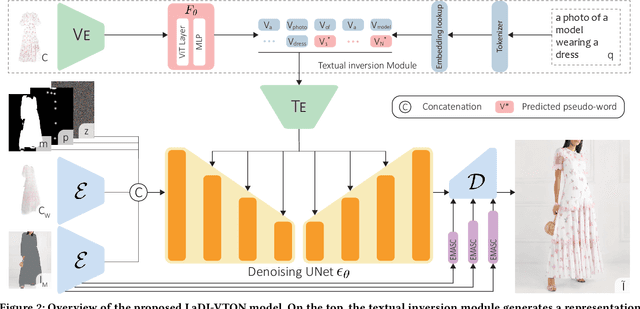
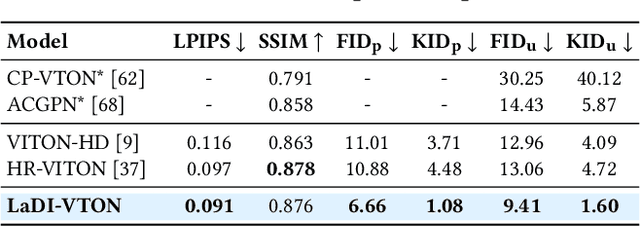
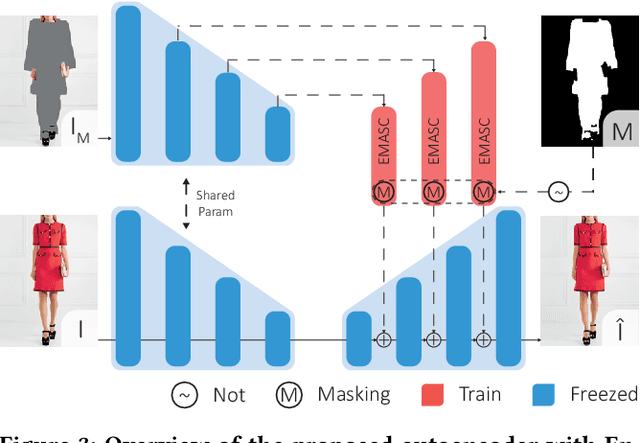
The rapidly evolving fields of e-commerce and metaverse continue to seek innovative approaches to enhance the consumer experience. At the same time, recent advancements in the development of diffusion models have enabled generative networks to create remarkably realistic images. In this context, image-based virtual try-on, which consists in generating a novel image of a target model wearing a given in-shop garment, has yet to capitalize on the potential of these powerful generative solutions. This work introduces LaDI-VTON, the first Latent Diffusion textual Inversion-enhanced model for the Virtual Try-ON task. The proposed architecture relies on a latent diffusion model extended with a novel additional autoencoder module that exploits learnable skip connections to enhance the generation process preserving the model's characteristics. To effectively maintain the texture and details of the in-shop garment, we propose a textual inversion component that can map the visual features of the garment to the CLIP token embedding space and thus generate a set of pseudo-word token embeddings capable of conditioning the generation process. Experimental results on Dress Code and VITON-HD datasets demonstrate that our approach outperforms the competitors by a consistent margin, achieving a significant milestone for the task. Source code and trained models will be publicly released at: https://github.com/miccunifi/ladi-vton.
Multimodal Garment Designer: Human-Centric Latent Diffusion Models for Fashion Image Editing
Apr 04, 2023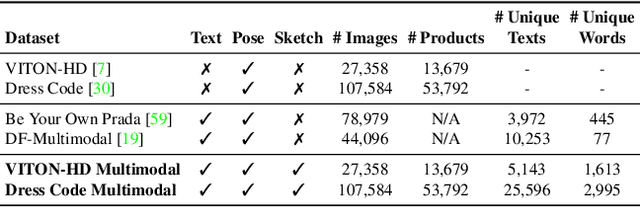
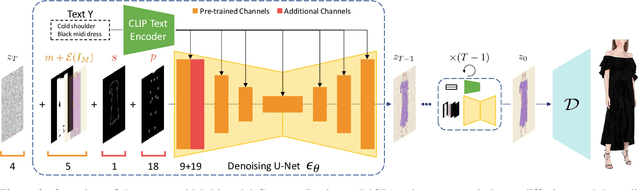
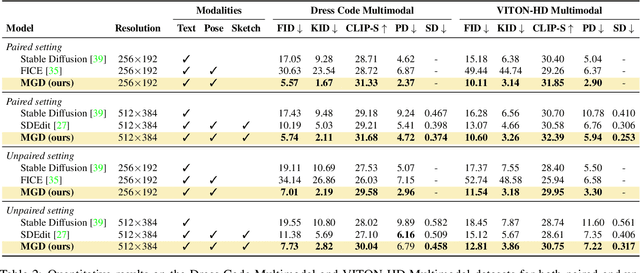

Fashion illustration is used by designers to communicate their vision and to bring the design idea from conceptualization to realization, showing how clothes interact with the human body. In this context, computer vision can thus be used to improve the fashion design process. Differently from previous works that mainly focused on the virtual try-on of garments, we propose the task of multimodal-conditioned fashion image editing, guiding the generation of human-centric fashion images by following multimodal prompts, such as text, human body poses, and garment sketches. We tackle this problem by proposing a new architecture based on latent diffusion models, an approach that has not been used before in the fashion domain. Given the lack of existing datasets suitable for the task, we also extend two existing fashion datasets, namely Dress Code and VITON-HD, with multimodal annotations collected in a semi-automatic manner. Experimental results on these new datasets demonstrate the effectiveness of our proposal, both in terms of realism and coherence with the given multimodal inputs. Source code and collected multimodal annotations will be publicly released at: https://github.com/aimagelab/multimodal-garment-designer.
Parents and Children: Distinguishing Multimodal DeepFakes from Natural Images
Apr 02, 2023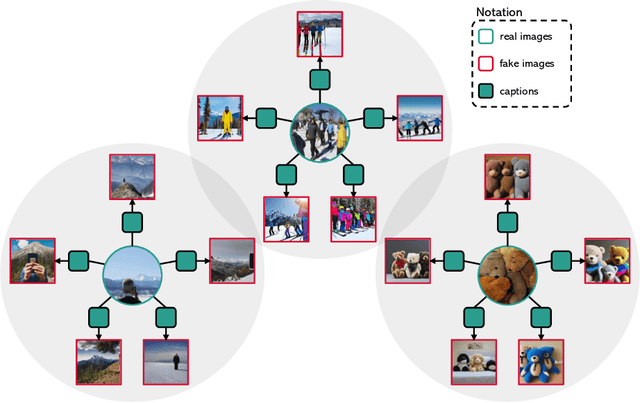
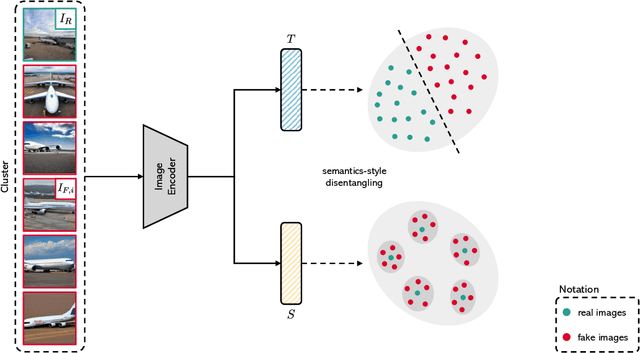
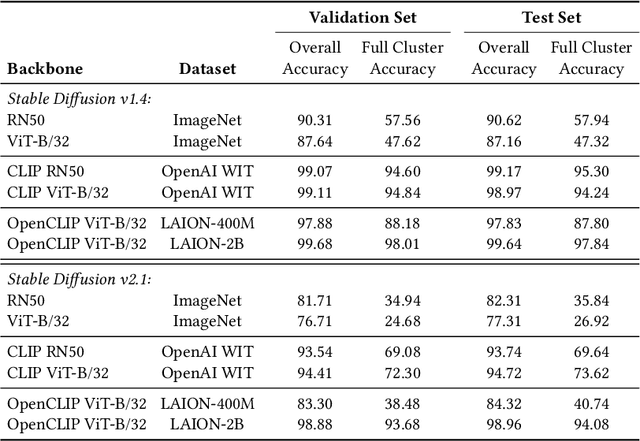
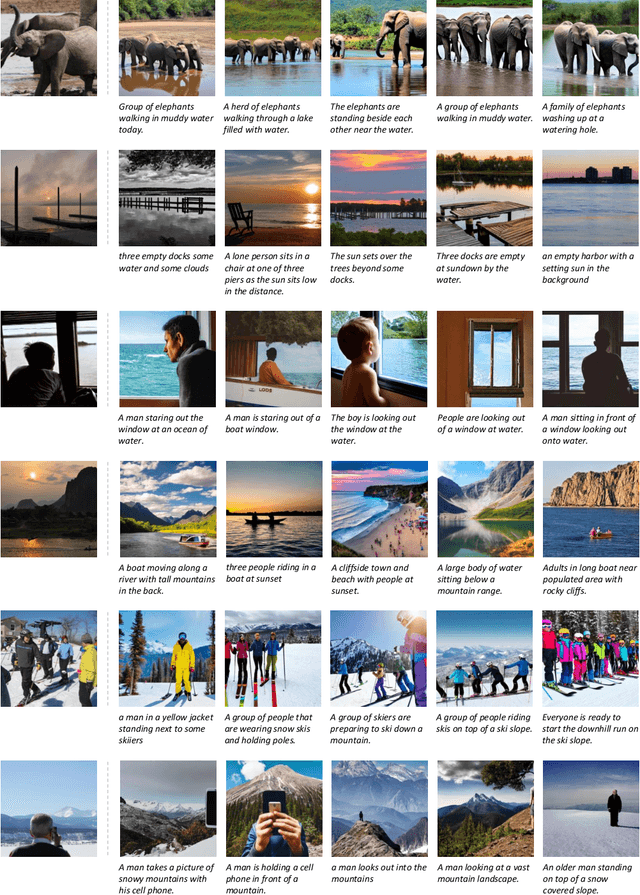
Recent advancements in diffusion models have enabled the generation of realistic deepfakes by writing textual prompts in natural language. While these models have numerous benefits across various sectors, they have also raised concerns about the potential misuse of fake images and cast new pressures on fake image detection. In this work, we pioneer a systematic study of the authenticity of fake images generated by state-of-the-art diffusion models. Firstly, we conduct a comprehensive study on the performance of contrastive and classification-based visual features. Our analysis demonstrates that fake images share common low-level cues, which render them easily recognizable. Further, we devise a multimodal setting wherein fake images are synthesized by different textual captions, which are used as seeds for a generator. Under this setting, we quantify the performance of fake detection strategies and introduce a contrastive-based disentangling strategy which let us analyze the role of the semantics of textual descriptions and low-level perceptual cues. Finally, we release a new dataset, called COCOFake, containing about 600k images generated from original COCO images.
Dress Code: High-Resolution Multi-Category Virtual Try-On
Apr 18, 2022



Image-based virtual try-on strives to transfer the appearance of a clothing item onto the image of a target person. Prior work focuses mainly on upper-body clothes (e.g. t-shirts, shirts, and tops) and neglects full-body or lower-body items. This shortcoming arises from a main factor: current publicly available datasets for image-based virtual try-on do not account for this variety, thus limiting progress in the field. To address this deficiency, we introduce Dress Code, which contains images of multi-category clothes. Dress Code is more than 3x larger than publicly available datasets for image-based virtual try-on and features high-resolution paired images (1024 x 768) with front-view, full-body reference models. To generate HD try-on images with high visual quality and rich in details, we propose to learn fine-grained discriminating features. Specifically, we leverage a semantic-aware discriminator that makes predictions at pixel-level instead of image- or patch-level. Extensive experimental evaluation demonstrates that the proposed approach surpasses the baselines and state-of-the-art competitors in terms of visual quality and quantitative results. The Dress Code dataset is publicly available at https://github.com/aimagelab/dress-code.
Development of a dynamic type 2 diabetes risk prediction tool: a UK Biobank study
Apr 20, 2021Diabetes affects over 400 million people and is among the leading causes of morbidity worldwide. Identification of high-risk individuals can support early diagnosis and prevention of disease development through lifestyle changes. However, the majority of existing risk scores require information about blood-based factors which are not obtainable outside of the clinic. Here, we aimed to develop an accessible solution that could be deployed digitally and at scale. We developed a predictive 10-year type 2 diabetes risk score using 301 features derived from 472,830 participants in the UK Biobank dataset while excluding any features which are not easily obtainable by a smartphone. Using a data-driven feature selection process, 19 features were included in the final reduced model. A Cox proportional hazards model slightly overperformed a DeepSurv model trained using the same features, achieving a concordance index of 0.818 (95% CI: 0.812-0.823), compared to 0.811 (95% CI: 0.806-0.815). The final model showed good calibration. This tool can be used for clinical screening of individuals at risk of developing type 2 diabetes and to foster patient empowerment by broadening their knowledge of the factors affecting their personal risk.
Development of an accessible 10-year Digital CArdioVAscular risk assessment: a UK Biobank study
Apr 20, 2021
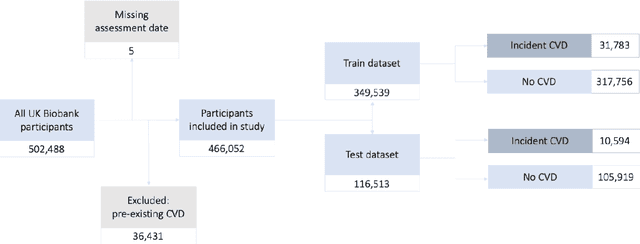
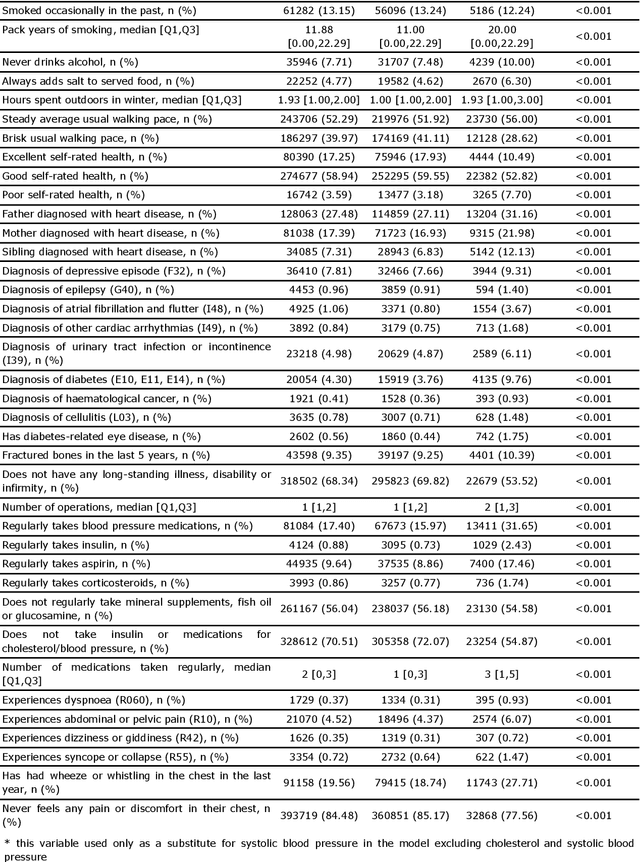
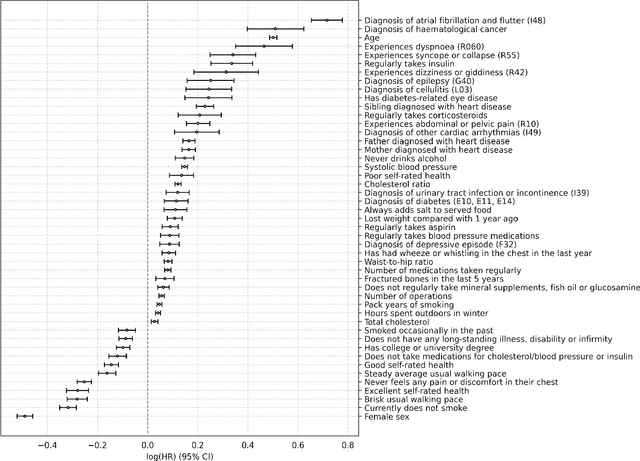
Background: Cardiovascular diseases (CVDs) are among the leading causes of death worldwide. Predictive scores providing personalised risk of developing CVD are increasingly used in clinical practice. Most scores, however, utilise a homogenous set of features and require the presence of a physician. Objective: The aim was to develop a new risk model (DiCAVA) using statistical and machine learning techniques that could be applied in a remote setting. A secondary goal was to identify new patient-centric variables that could be incorporated into CVD risk assessments. Methods: Across 466,052 participants, Cox proportional hazards (CPH) and DeepSurv models were trained using 608 variables derived from the UK Biobank to investigate the 10-year risk of developing a CVD. Data-driven feature selection reduced the number of features to 47, after which reduced models were trained. Both models were compared to the Framingham score. Results: The reduced CPH model achieved a c-index of 0.7443, whereas DeepSurv achieved a c-index of 0.7446. Both CPH and DeepSurv were superior in determining the CVD risk compared to Framingham score. Minimal difference was observed when cholesterol and blood pressure were excluded from the models (CPH: 0.741, DeepSurv: 0.739). The models show very good calibration and discrimination on the test data. Conclusion: We developed a cardiovascular risk model that has very good predictive capacity and encompasses new variables. The score could be incorporated into clinical practice and utilised in a remote setting, without the need of including cholesterol. Future studies will focus on external validation across heterogeneous samples.
DropIn: Making Reservoir Computing Neural Networks Robust to Missing Inputs by Dropout
May 07, 2017



The paper presents a novel, principled approach to train recurrent neural networks from the Reservoir Computing family that are robust to missing part of the input features at prediction time. By building on the ensembling properties of Dropout regularization, we propose a methodology, named DropIn, which efficiently trains a neural model as a committee machine of subnetworks, each capable of predicting with a subset of the original input features. We discuss the application of the DropIn methodology in the context of Reservoir Computing models and targeting applications characterized by input sources that are unreliable or prone to be disconnected, such as in pervasive wireless sensor networks and ambient intelligence. We provide an experimental assessment using real-world data from such application domains, showing how the Dropin methodology allows to maintain predictive performances comparable to those of a model without missing features, even when 20\%-50\% of the inputs are not available.