 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of a dynamic type 2 diabetes risk prediction tool: a UK Biobank study
Apr 20, 2021Diabetes affects over 400 million people and is among the leading causes of morbidity worldwide. Identification of high-risk individuals can support early diagnosis and prevention of disease development through lifestyle changes. However, the majority of existing risk scores require information about blood-based factors which are not obtainable outside of the clinic. Here, we aimed to develop an accessible solution that could be deployed digitally and at scale. We developed a predictive 10-year type 2 diabetes risk score using 301 features derived from 472,830 participants in the UK Biobank dataset while excluding any features which are not easily obtainable by a smartphone. Using a data-driven feature selection process, 19 features were included in the final reduced model. A Cox proportional hazards model slightly overperformed a DeepSurv model trained using the same features, achieving a concordance index of 0.818 (95% CI: 0.812-0.823), compared to 0.811 (95% CI: 0.806-0.815). The final model showed good calibration. This tool can be used for clinical screening of individuals at risk of developing type 2 diabetes and to foster patient empowerment by broadening their knowledge of the factors affecting their personal risk.
Development of an accessible 10-year Digital CArdioVAscular risk assessment: a UK Biobank study
Apr 20, 2021
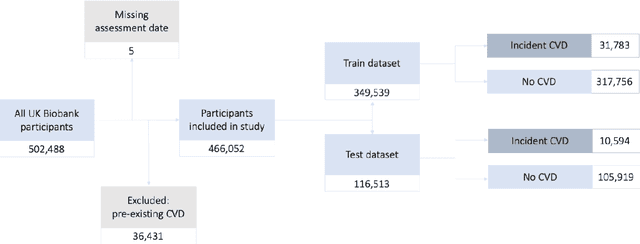
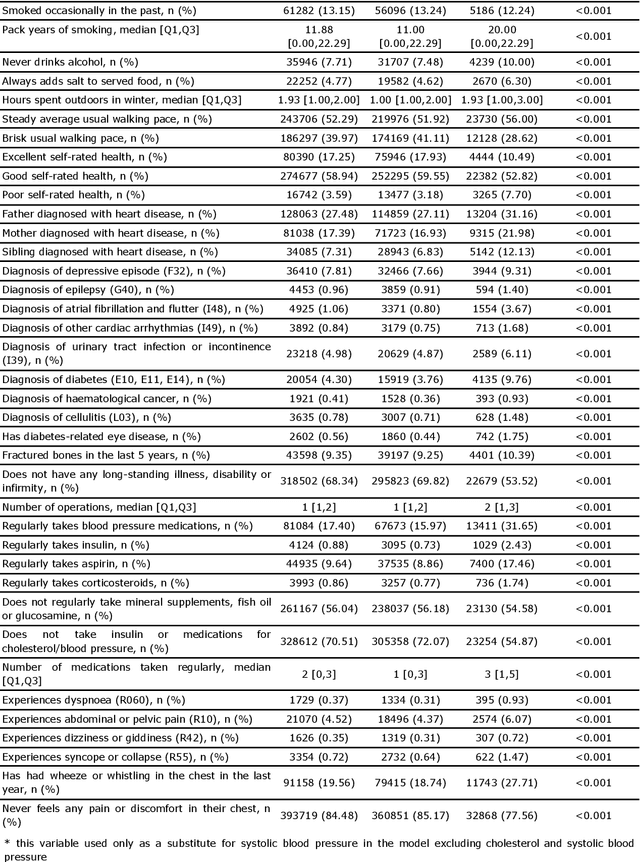
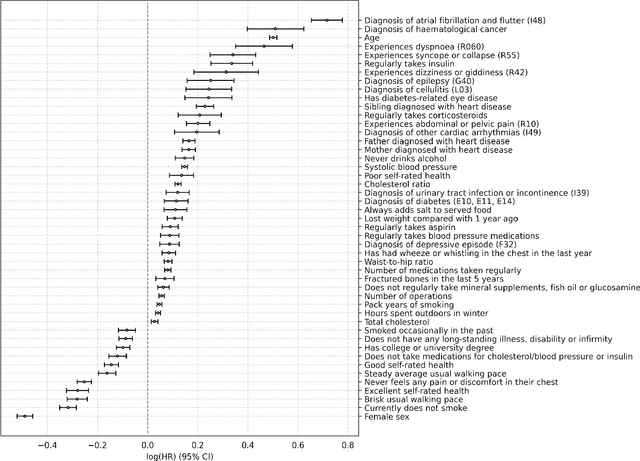
Background: Cardiovascular diseases (CVDs) are among the leading causes of death worldwide. Predictive scores providing personalised risk of developing CVD are increasingly used in clinical practice. Most scores, however, utilise a homogenous set of features and require the presence of a physician. Objective: The aim was to develop a new risk model (DiCAVA) using statistical and machine learning techniques that could be applied in a remote setting. A secondary goal was to identify new patient-centric variables that could be incorporated into CVD risk assessments. Methods: Across 466,052 participants, Cox proportional hazards (CPH) and DeepSurv models were trained using 608 variables derived from the UK Biobank to investigate the 10-year risk of developing a CVD. Data-driven feature selection reduced the number of features to 47, after which reduced models were trained. Both models were compared to the Framingham score. Results: The reduced CPH model achieved a c-index of 0.7443, whereas DeepSurv achieved a c-index of 0.7446. Both CPH and DeepSurv were superior in determining the CVD risk compared to Framingham score. Minimal difference was observed when cholesterol and blood pressure were excluded from the models (CPH: 0.741, DeepSurv: 0.739). The models show very good calibration and discrimination on the test data. Conclusion: We developed a cardiovascular risk model that has very good predictive capacity and encompasses new variables. The score could be incorporated into clinical practice and utilised in a remote setting, without the need of including cholesterol. Future studies will focus on external validation across heterogeneous samples.