 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFADER: Fast Adversarial Example Rejection
Oct 18, 2020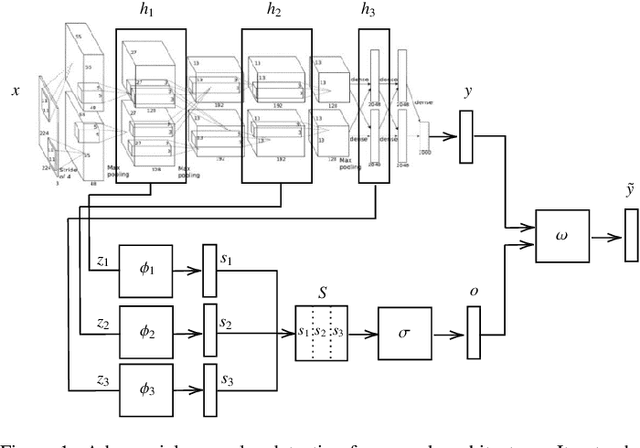
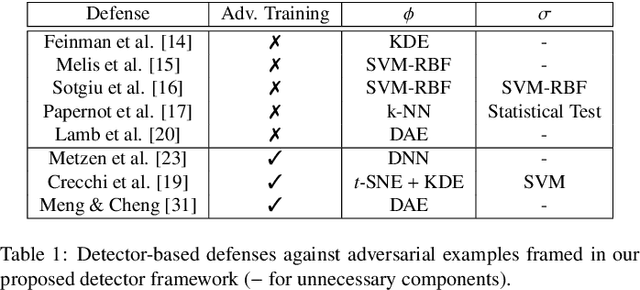
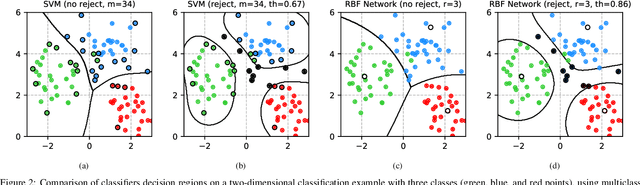

Deep neural networks are vulnerable to adversarial examples, i.e., carefully-crafted inputs that mislead classification at test time. Recent defenses have been shown to improve adversarial robustness by detecting anomalous deviations from legitimate training samples at different layer representations - a behavior normally exhibited by adversarial attacks. Despite technical differences, all aforementioned methods share a common backbone structure that we formalize and highlight in this contribution, as it can help in identifying promising research directions and drawbacks of existing methods. The first main contribution of this work is the review of these detection methods in the form of a unifying framework designed to accommodate both existing defenses and newer ones to come. In terms of drawbacks, the overmentioned defenses require comparing input samples against an oversized number of reference prototypes, possibly at different representation layers, dramatically worsening the test-time efficiency. Besides, such defenses are typically based on ensembling classifiers with heuristic methods, rather than optimizing the whole architecture in an end-to-end manner to better perform detection. As a second main contribution of this work, we introduce FADER, a novel technique for speeding up detection-based methods. FADER overcome the issues above by employing RBF networks as detectors: by fixing the number of required prototypes, the runtime complexity of adversarial examples detectors can be controlled. Our experiments outline up to 73x prototypes reduction compared to analyzed detectors for MNIST dataset and up to 50x for CIFAR10 dataset respectively, without sacrificing classification accuracy on both clean and adversarial data.
Perplexity-free Parametric t-SNE
Oct 03, 2020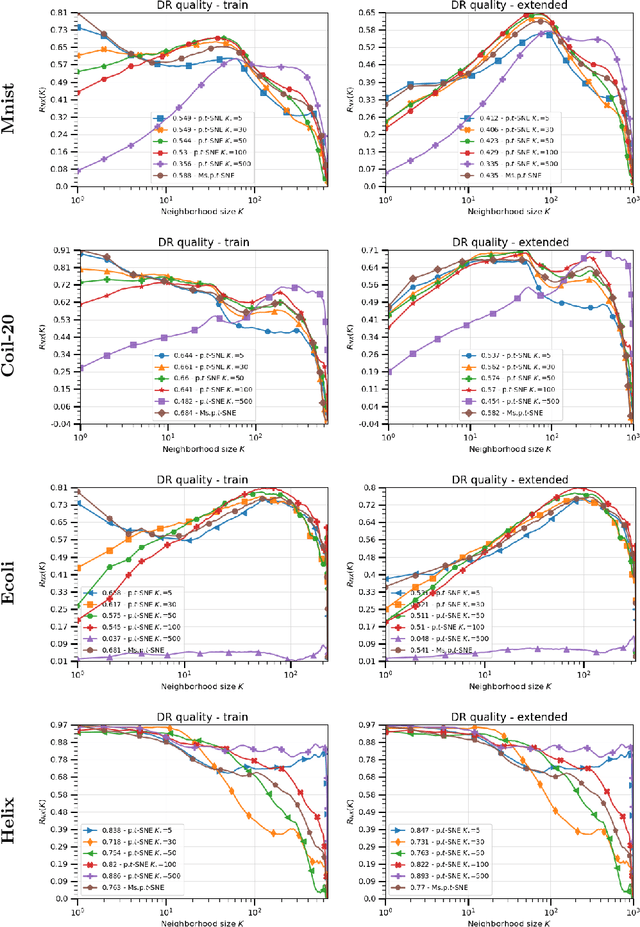
The t-distributed Stochastic Neighbor Embedding (t-SNE) algorithm is a ubiquitously employed dimensionality reduction (DR) method. Its non-parametric nature and impressive efficacy motivated its parametric extension. It is however bounded to a user-defined perplexity parameter, restricting its DR quality compared to recently developed multi-scale perplexity-free approaches. This paper hence proposes a multi-scale parametric t-SNE scheme, relieved from the perplexity tuning and with a deep neural network implementing the mapping. It produces reliable embeddings with out-of-sample extensions, competitive with the best perplexity adjustments in terms of neighborhood preservation on multiple data sets.
Detecting Adversarial Examples through Nonlinear Dimensionality Reduction
May 01, 2019
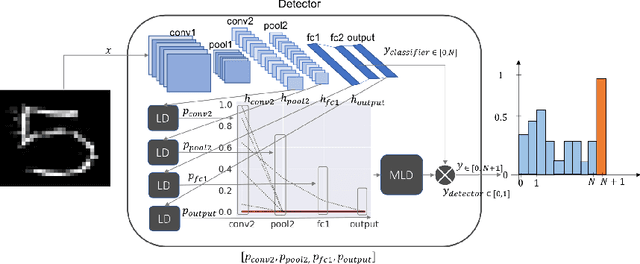


Deep neural networks are vulnerable to adversarial examples, i.e., carefully-perturbed inputs aimed to mislead classification. This work proposes a detection method based on combining non-linear dimensionality reduction and density estimation techniques. Our empirical findings show that the proposed approach is able to effectively detect adversarial examples crafted by non-adaptive attackers, i.e., not specifically tuned to bypass the detection method. Given our promising results, we plan to extend our analysis to adaptive attackers in future work.
DropIn: Making Reservoir Computing Neural Networks Robust to Missing Inputs by Dropout
May 07, 2017



The paper presents a novel, principled approach to train recurrent neural networks from the Reservoir Computing family that are robust to missing part of the input features at prediction time. By building on the ensembling properties of Dropout regularization, we propose a methodology, named DropIn, which efficiently trains a neural model as a committee machine of subnetworks, each capable of predicting with a subset of the original input features. We discuss the application of the DropIn methodology in the context of Reservoir Computing models and targeting applications characterized by input sources that are unreliable or prone to be disconnected, such as in pervasive wireless sensor networks and ambient intelligence. We provide an experimental assessment using real-world data from such application domains, showing how the Dropin methodology allows to maintain predictive performances comparable to those of a model without missing features, even when 20\%-50\% of the inputs are not available.