 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTPP-Gaze: Modelling Gaze Dynamics in Space and Time with Neural Temporal Point Processes
Oct 30, 2024

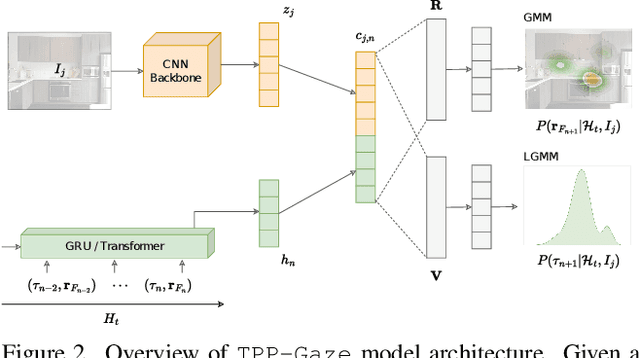

Attention guides our gaze to fixate the proper location of the scene and holds it in that location for the deserved amount of time given current processing demands, before shifting to the next one. As such, gaze deployment crucially is a temporal process. Existing computational models have made significant strides in predicting spatial aspects of observer's visual scanpaths (where to look), while often putting on the background the temporal facet of attention dynamics (when). In this paper we present TPP-Gaze, a novel and principled approach to model scanpath dynamics based on Neural Temporal Point Process (TPP), that jointly learns the temporal dynamics of fixations position and duration, integrating deep learning methodologies with point process theory. We conduct extensive experiments across five publicly available datasets. Our results show the overall superior performance of the proposed model compared to state-of-the-art approaches. Source code and trained models are publicly available at: https://github.com/phuselab/tppgaze.
Unveiling the Truth: Exploring Human Gaze Patterns in Fake Images
Mar 13, 2024


Creating high-quality and realistic images is now possible thanks to the impressive advancements in image generation. A description in natural language of your desired output is all you need to obtain breathtaking results. However, as the use of generative models grows, so do concerns about the propagation of malicious content and misinformation. Consequently, the research community is actively working on the development of novel fake detection techniques, primarily focusing on low-level features and possible fingerprints left by generative models during the image generation process. In a different vein, in our work, we leverage human semantic knowledge to investigate the possibility of being included in frameworks of fake image detection. To achieve this, we collect a novel dataset of partially manipulated images using diffusion models and conduct an eye-tracking experiment to record the eye movements of different observers while viewing real and fake stimuli. A preliminary statistical analysis is conducted to explore the distinctive patterns in how humans perceive genuine and altered images. Statistical findings reveal that, when perceiving counterfeit samples, humans tend to focus on more confined regions of the image, in contrast to the more dispersed observational pattern observed when viewing genuine images. Our dataset is publicly available at: https://github.com/aimagelab/unveiling-the-truth.
Trends, Applications, and Challenges in Human Attention Modelling
Feb 28, 2024

Human attention modelling has proven, in recent years, to be particularly useful not only for understanding the cognitive processes underlying visual exploration, but also for providing support to artificial intelligence models that aim to solve problems in various domains, including image and video processing, vision-and-language applications, and language modelling. This survey offers a reasoned overview of recent efforts to integrate human attention mechanisms into contemporary deep learning models and discusses future research directions and challenges. For a comprehensive overview on the ongoing research refer to our dedicated repository available at https://github.com/aimagelab/awesome-human-visual-attention.
OpenFashionCLIP: Vision-and-Language Contrastive Learning with Open-Source Fashion Data
Sep 11, 2023The inexorable growth of online shopping and e-commerce demands scalable and robust machine learning-based solutions to accommodate customer requirements. In the context of automatic tagging classification and multimodal retrieval, prior works either defined a low generalizable supervised learning approach or more reusable CLIP-based techniques while, however, training on closed source data. In this work, we propose OpenFashionCLIP, a vision-and-language contrastive learning method that only adopts open-source fashion data stemming from diverse domains, and characterized by varying degrees of specificity. Our approach is extensively validated across several tasks and benchmarks, and experimental results highlight a significant out-of-domain generalization capability and consistent improvements over state-of-the-art methods both in terms of accuracy and recall. Source code and trained models are publicly available at: https://github.com/aimagelab/open-fashion-clip.
LaDI-VTON: Latent Diffusion Textual-Inversion Enhanced Virtual Try-On
May 22, 2023
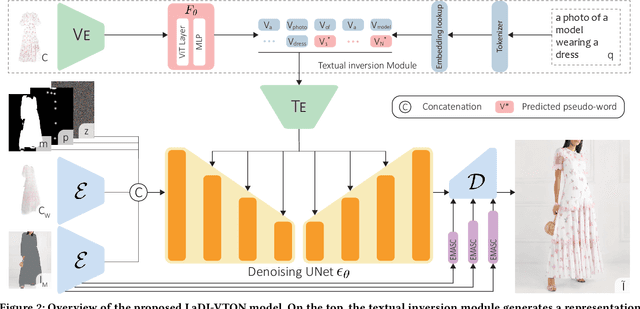
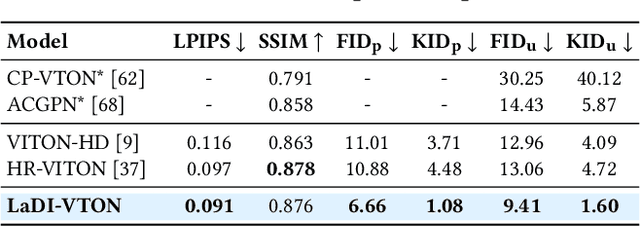
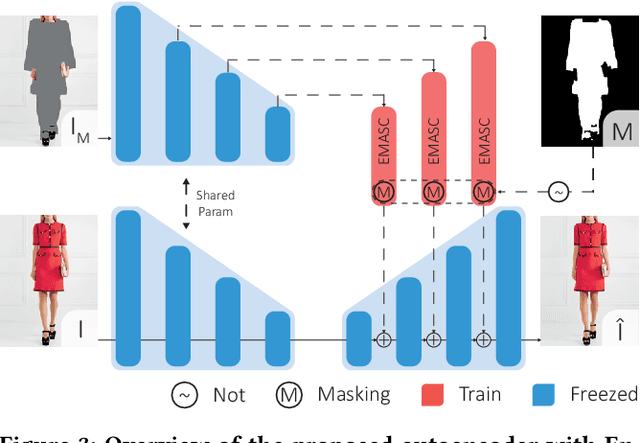
The rapidly evolving fields of e-commerce and metaverse continue to seek innovative approaches to enhance the consumer experience. At the same time, recent advancements in the development of diffusion models have enabled generative networks to create remarkably realistic images. In this context, image-based virtual try-on, which consists in generating a novel image of a target model wearing a given in-shop garment, has yet to capitalize on the potential of these powerful generative solutions. This work introduces LaDI-VTON, the first Latent Diffusion textual Inversion-enhanced model for the Virtual Try-ON task. The proposed architecture relies on a latent diffusion model extended with a novel additional autoencoder module that exploits learnable skip connections to enhance the generation process preserving the model's characteristics. To effectively maintain the texture and details of the in-shop garment, we propose a textual inversion component that can map the visual features of the garment to the CLIP token embedding space and thus generate a set of pseudo-word token embeddings capable of conditioning the generation process. Experimental results on Dress Code and VITON-HD datasets demonstrate that our approach outperforms the competitors by a consistent margin, achieving a significant milestone for the task. Source code and trained models will be publicly released at: https://github.com/miccunifi/ladi-vton.
Multimodal Garment Designer: Human-Centric Latent Diffusion Models for Fashion Image Editing
Apr 04, 2023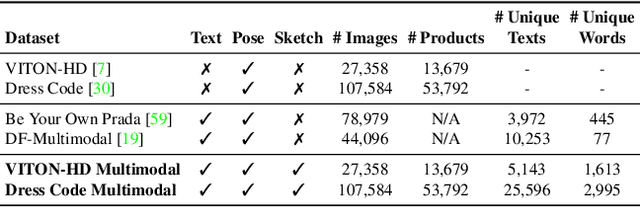
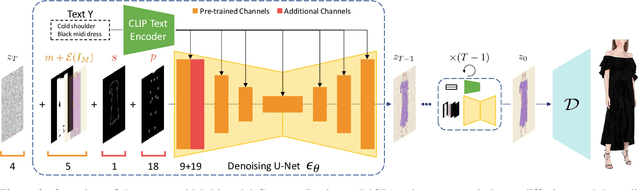
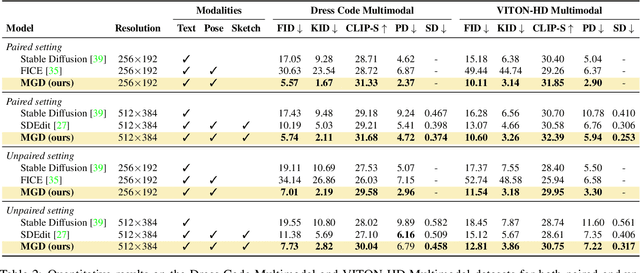

Fashion illustration is used by designers to communicate their vision and to bring the design idea from conceptualization to realization, showing how clothes interact with the human body. In this context, computer vision can thus be used to improve the fashion design process. Differently from previous works that mainly focused on the virtual try-on of garments, we propose the task of multimodal-conditioned fashion image editing, guiding the generation of human-centric fashion images by following multimodal prompts, such as text, human body poses, and garment sketches. We tackle this problem by proposing a new architecture based on latent diffusion models, an approach that has not been used before in the fashion domain. Given the lack of existing datasets suitable for the task, we also extend two existing fashion datasets, namely Dress Code and VITON-HD, with multimodal annotations collected in a semi-automatic manner. Experimental results on these new datasets demonstrate the effectiveness of our proposal, both in terms of realism and coherence with the given multimodal inputs. Source code and collected multimodal annotations will be publicly released at: https://github.com/aimagelab/multimodal-garment-designer.