 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveFix: Spatio-Temporally Coherent Driving Scene Restoration
Mar 17, 2026Recent advancements in 4D scene reconstruction, particularly those leveraging diffusion priors, have shown promise for novel view synthesis in autonomous driving. However, these methods often process frames independently or in a view-by-view manner, leading to a critical lack of spatio-temporal synergy. This results in spatial misalignment across cameras and temporal drift in sequences. We propose DriveFix, a novel multi-view restoration framework that ensures spatio-temporal coherence for driving scenes. Our approach employs an interleaved diffusion transformer architecture with specialized blocks to explicitly model both temporal dependencies and cross-camera spatial consistency. By conditioning the generation on historical context and integrating geometry-aware training losses, DriveFix enforces that the restored views adhere to a unified 3D geometry. This enables the consistent propagation of high-fidelity textures and significantly reduces artifacts. Extensive evaluations on the Waymo, nuScenes, and PandaSet datasets demonstrate that DriveFix achieves state-of-the-art performance in both reconstruction and novel view synthesis, marking a substantial step toward robust 4D world modeling for real-world deployment.
FAR-Drive: Frame-AutoRegressive Video Generation in Closed-Loop Autonomous Driving
Mar 16, 2026Despite rapid progress in autonomous driving, reliable training and evaluation of driving systems remain fundamentally constrained by the lack of scalable and interactive simulation environments. Recent generative video models achieve remarkable visual fidelity, yet most operate in open-loop settings and fail to support fine-grained frame-level interaction between agent actions and environment evolution. Building a learning-based closed-loop simulator for autonomous driving poses three major challenges: maintaining long-horizon temporal and cross-view consistency, mitigating autoregressive degradation under iterative self-conditioning, and satisfying low-latency inference constraints. In this work, we propose FAR-Drive, a frame-level autoregressive video generation framework for autonomous driving. We introduce a multi-view diffusion transformer with fine-grained structured control, enabling geometrically consistent multi-camera generation. To address long-horizon consistency and iterative degradation, we design a two-stage training strategy consisting of adaptive reference horizon conditioning and blend-forcing autoregressive training, which progressively improves consistency and robustness under self-conditioning. To meet low-latency interaction requirements, we further integrate system-level efficiency optimizations for inference acceleration. Experiments on the nuScenes dataset demonstrate that our method achieves state-of-the-art performance among existing closed-loop autonomous driving simulation approaches, while maintaining sub-second latency on a single GPU.
Embodied Navigation at the Art Gallery
Apr 19, 2022

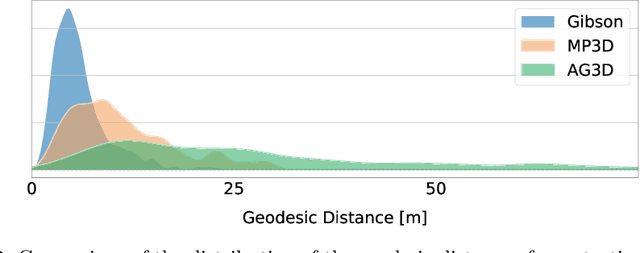
Embodied agents, trained to explore and navigate indoor photorealistic environments, have achieved impressive results on standard datasets and benchmarks. So far, experiments and evaluations have involved domestic and working scenes like offices, flats, and houses. In this paper, we build and release a new 3D space with unique characteristics: the one of a complete art museum. We name this environment ArtGallery3D (AG3D). Compared with existing 3D scenes, the collected space is ampler, richer in visual features, and provides very sparse occupancy information. This feature is challenging for occupancy-based agents which are usually trained in crowded domestic environments with plenty of occupancy information. Additionally, we annotate the coordinates of the main points of interest inside the museum, such as paintings, statues, and other items. Thanks to this manual process, we deliver a new benchmark for PointGoal navigation inside this new space. Trajectories in this dataset are far more complex and lengthy than existing ground-truth paths for navigation in Gibson and Matterport3D. We carry on extensive experimental evaluation using our new space for evaluation and prove that existing methods hardly adapt to this scenario. As such, we believe that the availability of this 3D model will foster future research and help improve existing solutions.
Dress Code: High-Resolution Multi-Category Virtual Try-On
Apr 18, 2022



Image-based virtual try-on strives to transfer the appearance of a clothing item onto the image of a target person. Prior work focuses mainly on upper-body clothes (e.g. t-shirts, shirts, and tops) and neglects full-body or lower-body items. This shortcoming arises from a main factor: current publicly available datasets for image-based virtual try-on do not account for this variety, thus limiting progress in the field. To address this deficiency, we introduce Dress Code, which contains images of multi-category clothes. Dress Code is more than 3x larger than publicly available datasets for image-based virtual try-on and features high-resolution paired images (1024 x 768) with front-view, full-body reference models. To generate HD try-on images with high visual quality and rich in details, we propose to learn fine-grained discriminating features. Specifically, we leverage a semantic-aware discriminator that makes predictions at pixel-level instead of image- or patch-level. Extensive experimental evaluation demonstrates that the proposed approach surpasses the baselines and state-of-the-art competitors in terms of visual quality and quantitative results. The Dress Code dataset is publicly available at https://github.com/aimagelab/dress-code.
Spot the Difference: A Novel Task for Embodied Agents in Changing Environments
Apr 18, 2022



Embodied AI is a recent research area that aims at creating intelligent agents that can move and operate inside an environment. Existing approaches in this field demand the agents to act in completely new and unexplored scenes. However, this setting is far from realistic use cases that instead require executing multiple tasks in the same environment. Even if the environment changes over time, the agent could still count on its global knowledge about the scene while trying to adapt its internal representation to the current state of the environment. To make a step towards this setting, we propose Spot the Difference: a novel task for Embodied AI where the agent has access to an outdated map of the environment and needs to recover the correct layout in a fixed time budget. To this end, we collect a new dataset of occupancy maps starting from existing datasets of 3D spaces and generating a number of possible layouts for a single environment. This dataset can be employed in the popular Habitat simulator and is fully compliant with existing methods that employ reconstructed occupancy maps during navigation. Furthermore, we propose an exploration policy that can take advantage of previous knowledge of the environment and identify changes in the scene faster and more effectively than existing agents. Experimental results show that the proposed architecture outperforms existing state-of-the-art models for exploration on this new setting.
Focus on Impact: Indoor Exploration with Intrinsic Motivation
Sep 14, 2021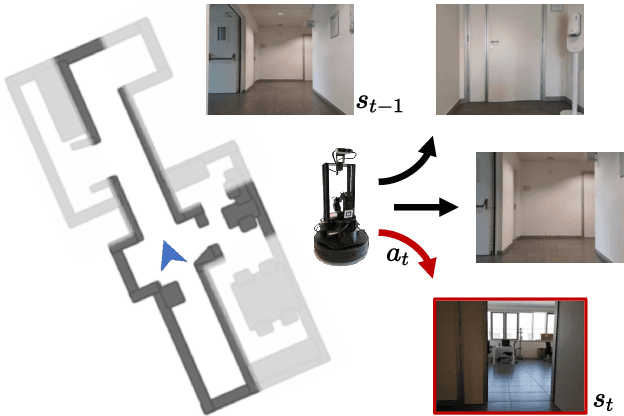
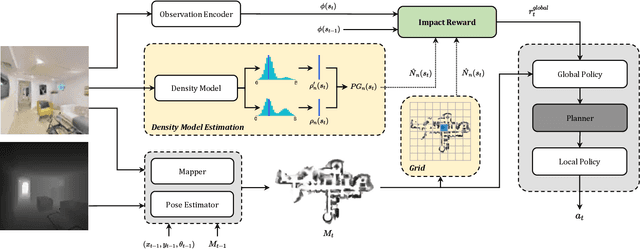

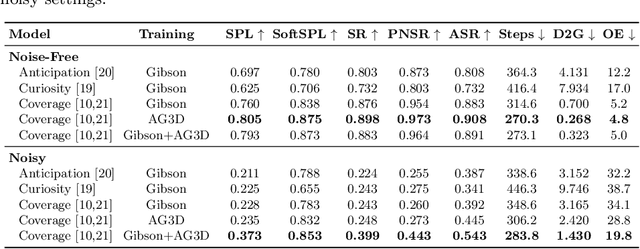
Exploration of indoor environments has recently experienced a significant interest, also thanks to the introduction of deep neural agents built in a hierarchical fashion and trained with Deep Reinforcement Learning (DRL) on simulated environments. Current state-of-the-art methods employ a dense extrinsic reward that requires the complete a priori knowledge of the layout of the training environment to learn an effective exploration policy. However, such information is expensive to gather in terms of time and resources. In this work, we propose to train the model with a purely intrinsic reward signal to guide exploration, which is based on the impact of the robot's actions on the environment. So far, impact-based rewards have been employed for simple tasks and in procedurally generated synthetic environments with countable states. Since the number of states observable by the agent in realistic indoor environments is non-countable, we include a neural-based density model and replace the traditional count-based regularization with an estimated pseudo-count of previously visited states. The proposed exploration approach outperforms DRL-based competitors relying on intrinsic rewards and surpasses the agents trained with a dense extrinsic reward computed with the environment layouts. We also show that a robot equipped with the proposed approach seamlessly adapts to point-goal navigation and real-world deployment.
Working Memory Connections for LSTM
Aug 31, 2021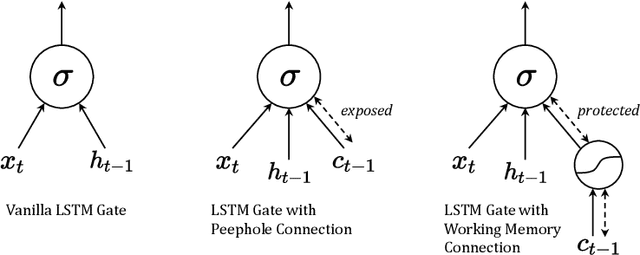
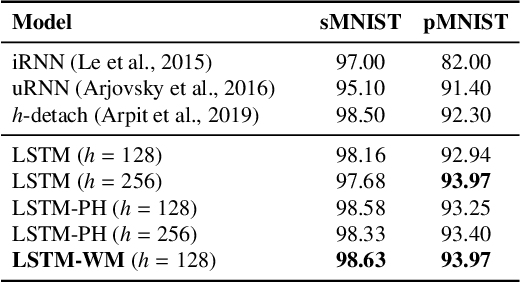
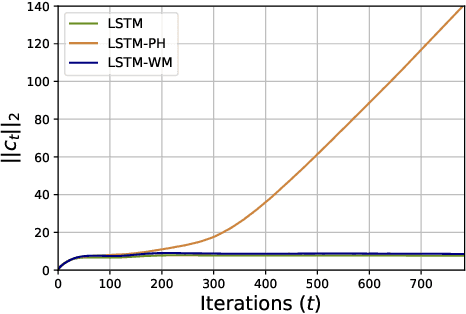

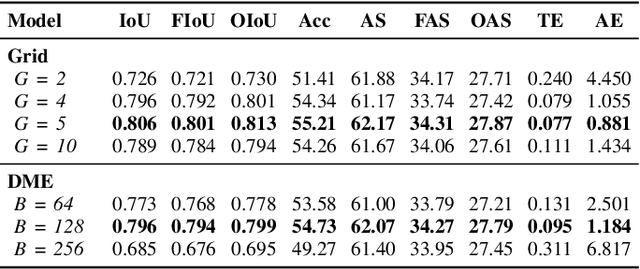
Recurrent Neural Networks with Long Short-Term Memory (LSTM) make use of gating mechanisms to mitigate exploding and vanishing gradients when learning long-term dependencies. For this reason, LSTMs and other gated RNNs are widely adopted, being the standard de facto for many sequence modeling tasks. Although the memory cell inside the LSTM contains essential information, it is not allowed to influence the gating mechanism directly. In this work, we improve the gate potential by including information coming from the internal cell state. The proposed modification, named Working Memory Connection, consists in adding a learnable nonlinear projection of the cell content into the network gates. This modification can fit into the classical LSTM gates without any assumption on the underlying task, being particularly effective when dealing with longer sequences. Previous research effort in this direction, which goes back to the early 2000s, could not bring a consistent improvement over vanilla LSTM. As part of this paper, we identify a key issue tied to previous connections that heavily limits their effectiveness, hence preventing a successful integration of the knowledge coming from the internal cell state. We show through extensive experimental evaluation that Working Memory Connections constantly improve the performance of LSTMs on a variety of tasks. Numerical results suggest that the cell state contains useful information that is worth including in the gate structure.
Out of the Box: Embodied Navigation in the Real World
May 12, 2021


The research field of Embodied AI has witnessed substantial progress in visual navigation and exploration thanks to powerful simulating platforms and the availability of 3D data of indoor and photorealistic environments. These two factors have opened the doors to a new generation of intelligent agents capable of achieving nearly perfect PointGoal Navigation. However, such architectures are commonly trained with millions, if not billions, of frames and tested in simulation. Together with great enthusiasm, these results yield a question: how many researchers will effectively benefit from these advances? In this work, we detail how to transfer the knowledge acquired in simulation into the real world. To that end, we describe the architectural discrepancies that damage the Sim2Real adaptation ability of models trained on the Habitat simulator and propose a novel solution tailored towards the deployment in real-world scenarios. We then deploy our models on a LoCoBot, a Low-Cost Robot equipped with a single Intel RealSense camera. Different from previous work, our testing scene is unavailable to the agent in simulation. The environment is also inaccessible to the agent beforehand, so it cannot count on scene-specific semantic priors. In this way, we reproduce a setting in which a research group (potentially from other fields) needs to employ the agent visual navigation capabilities as-a-Service. Our experiments indicate that it is possible to achieve satisfying results when deploying the obtained model in the real world. Our code and models are available at https://github.com/aimagelab/LoCoNav.
Explore and Explain: Self-supervised Navigation and Recounting
Jul 14, 2020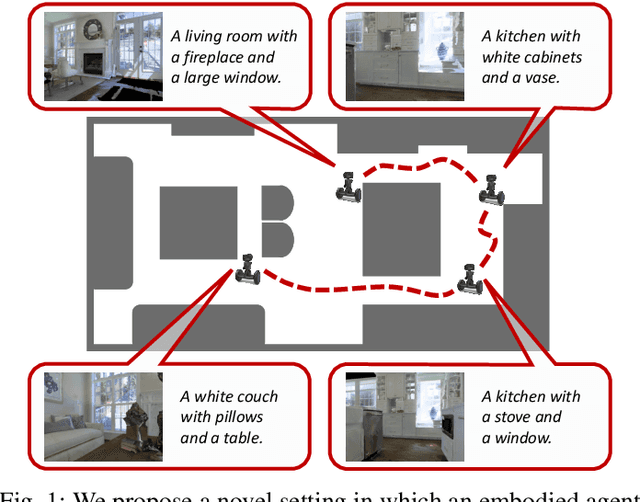



Embodied AI has been recently gaining attention as it aims to foster the development of autonomous and intelligent agents. In this paper, we devise a novel embodied setting in which an agent needs to explore a previously unknown environment while recounting what it sees during the path. In this context, the agent needs to navigate the environment driven by an exploration goal, select proper moments for description, and output natural language descriptions of relevant objects and scenes. Our model integrates a novel self-supervised exploration module with penalty, and a fully-attentive captioning model for explanation. Also, we investigate different policies for selecting proper moments for explanation, driven by information coming from both the environment and the navigation. Experiments are conducted on photorealistic environments from the Matterport3D dataset and investigate the navigation and explanation capabilities of the agent as well as the role of their interactions.
Perceive, Transform, and Act: Multi-Modal Attention Networks for Vision-and-Language Navigation
Nov 27, 2019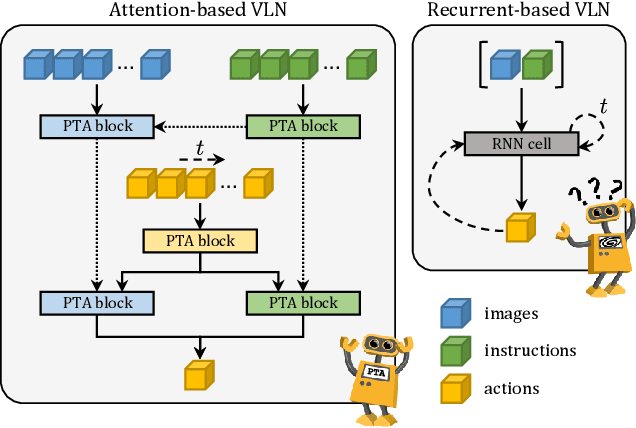
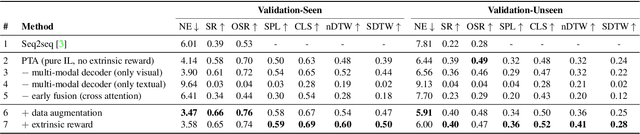
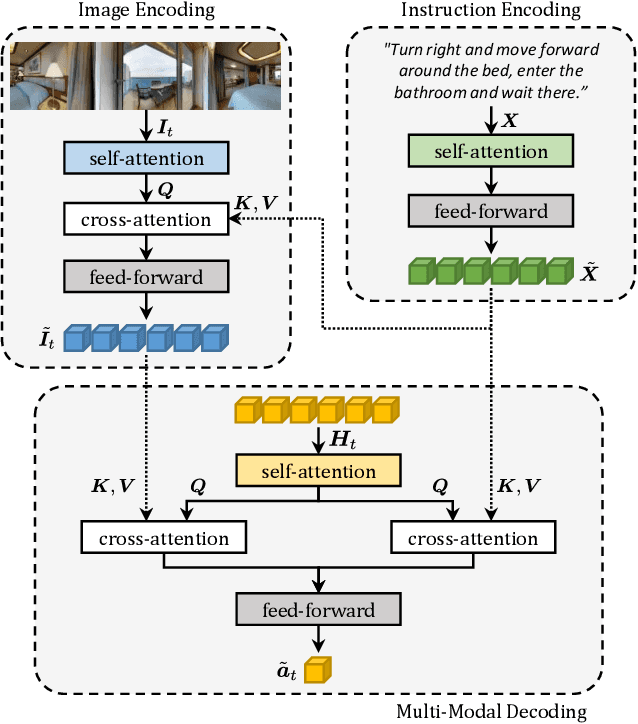
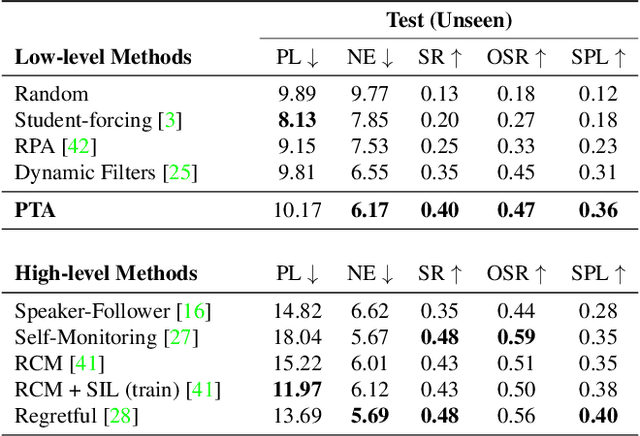
Vision-and-Language Navigation (VLN) is a challenging task in which an agent needs to follow a language-specified path to reach a target destination. In this paper, we strive for the creation of an agent able to tackle three key issues: multi-modality, long-term dependencies, and adaptability towards different locomotive settings. To that end, we devise "Perceive, Transform, and Act" (PTA): a fully-attentive VLN architecture that leaves the recurrent approach behind and the first Transformer-like architecture incorporating three different modalities - natural language, images, and discrete actions for the agent control. In particular, we adopt an early fusion strategy to merge lingual and visual information efficiently in our encoder. We then propose to refine the decoding phase with a late fusion extension between the agent's history of actions and the perception modalities. We experimentally validate our model on two datasets and two different action settings. PTA surpasses previous state-of-the-art architectures for low-level VLN on R2R and achieves the first place for both setups in the recently proposed R4R benchmark. Our code is publicly available at https://github.com/aimagelab/perceive-transform-and-act.