 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Embodied Agents: When Robotics Meets Deep Learning Reasoning
May 02, 2025The increase in available computing power and the Deep Learning revolution have allowed the exploration of new topics and frontiers in Artificial Intelligence research. A new field called Embodied Artificial Intelligence, which places at the intersection of Computer Vision, Robotics, and Decision Making, has been gaining importance during the last few years, as it aims to foster the development of smart autonomous robots and their deployment in society. The recent availability of large collections of 3D models for photorealistic robotic simulation has allowed faster and safe training of learning-based agents for millions of frames and a careful evaluation of their behavior before deploying the models on real robotic platforms. These intelligent agents are intended to perform a certain task in a possibly unknown environment. To this end, during the training in simulation, the agents learn to perform continuous interactions with the surroundings, such as gathering information from the environment, encoding and extracting useful cues for the task, and performing actions towards the final goal; where every action of the agent influences the interactions. This dissertation follows the complete creation process of embodied agents for indoor environments, from their concept to their implementation and deployment. We aim to contribute to research in Embodied AI and autonomous agents, in order to foster future work in this field. We present a detailed analysis of the procedure behind implementing an intelligent embodied agent, comprehending a thorough description of the current state-of-the-art in literature, technical explanations of the proposed methods, and accurate experimental studies on relevant robotic tasks.
Personalized Instance-based Navigation Toward User-Specific Objects in Realistic Environments
Oct 23, 2024



In the last years, the research interest in visual navigation towards objects in indoor environments has grown significantly. This growth can be attributed to the recent availability of large navigation datasets in photo-realistic simulated environments, like Gibson and Matterport3D. However, the navigation tasks supported by these datasets are often restricted to the objects present in the environment at acquisition time. Also, they fail to account for the realistic scenario in which the target object is a user-specific instance that can be easily confused with similar objects and may be found in multiple locations within the environment. To address these limitations, we propose a new task denominated Personalized Instance-based Navigation (PIN), in which an embodied agent is tasked with locating and reaching a specific personal object by distinguishing it among multiple instances of the same category. The task is accompanied by PInNED, a dedicated new dataset composed of photo-realistic scenes augmented with additional 3D objects. In each episode, the target object is presented to the agent using two modalities: a set of visual reference images on a neutral background and manually annotated textual descriptions. Through comprehensive evaluations and analyses, we showcase the challenges of the PIN task as well as the performance and shortcomings of currently available methods designed for object-driven navigation, considering modular and end-to-end agents.
UNMuTe: Unifying Navigation and Multimodal Dialogue-like Text Generation
Aug 08, 2024
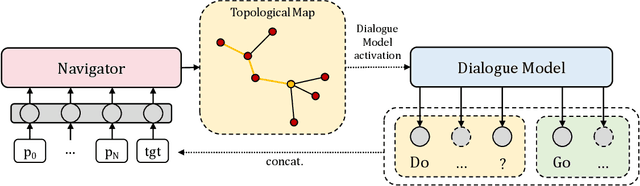
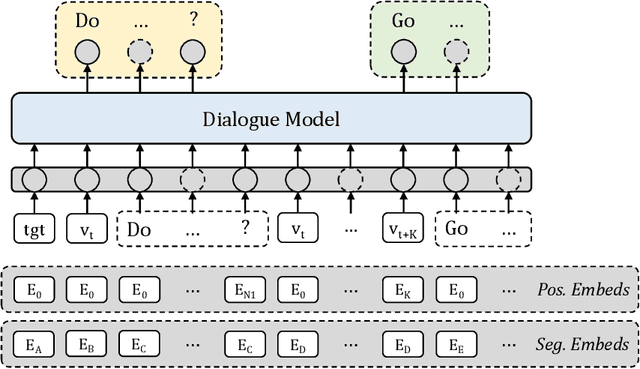
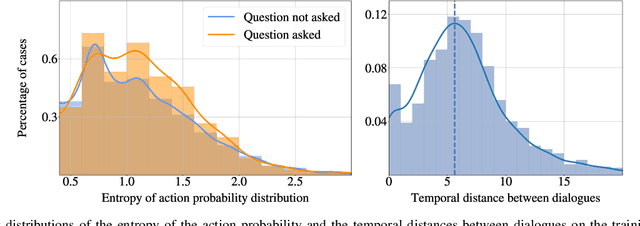
Smart autonomous agents are becoming increasingly important in various real-life applications, including robotics and autonomous vehicles. One crucial skill that these agents must possess is the ability to interact with their surrounding entities, such as other agents or humans. In this work, we aim at building an intelligent agent that can efficiently navigate in an environment while being able to interact with an oracle (or human) in natural language and ask for directions when it is unsure about its navigation performance. The interaction is started by the agent that produces a question, which is then answered by the oracle on the basis of the shortest trajectory to the goal. The process can be performed multiple times during navigation, thus enabling the agent to hold a dialogue with the oracle. To this end, we propose a novel computational model, named UNMuTe, that consists of two main components: a dialogue model and a navigator. Specifically, the dialogue model is based on a GPT-2 decoder that handles multimodal data consisting of both text and images. First, the dialogue model is trained to generate question-answer pairs: the question is generated using the current image, while the answer is produced leveraging future images on the path toward the goal. Subsequently, a VLN model is trained to follow the dialogue predicting navigation actions or triggering the dialogue model if it needs help. In our experimental analysis, we show that UNMuTe achieves state-of-the-art performance on the main navigation tasks implying dialogue, i.e. Cooperative Vision and Dialogue Navigation (CVDN) and Navigation from Dialogue History (NDH), proving that our approach is effective in generating useful questions and answers to guide navigation.
AIGeN: An Adversarial Approach for Instruction Generation in VLN
Apr 15, 2024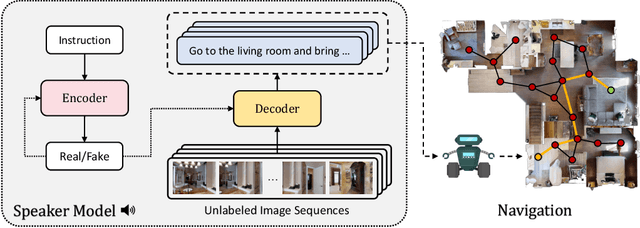
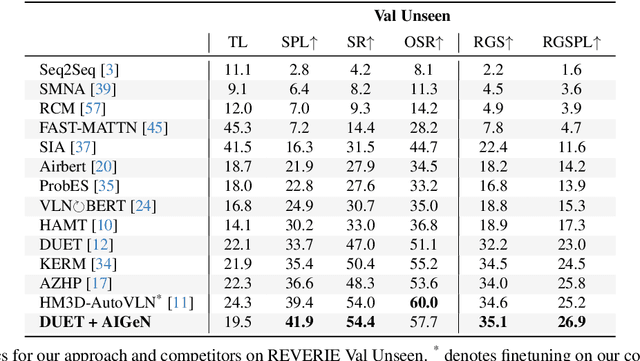
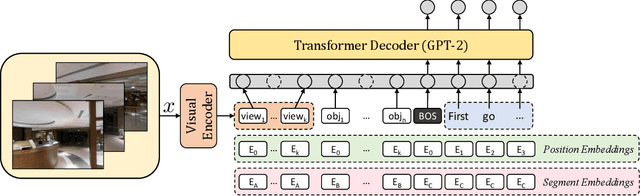
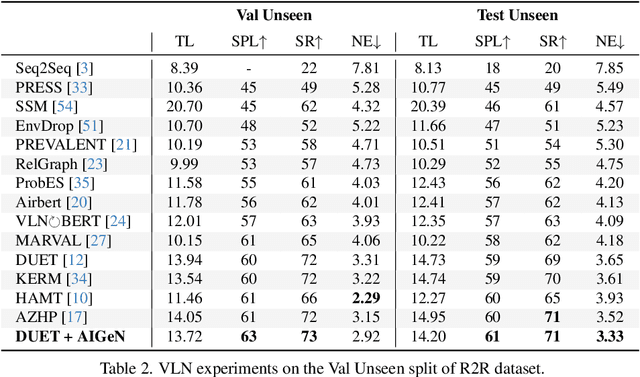
In the last few years, the research interest in Vision-and-Language Navigation (VLN) has grown significantly. VLN is a challenging task that involves an agent following human instructions and navigating in a previously unknown environment to reach a specified goal. Recent work in literature focuses on different ways to augment the available datasets of instructions for improving navigation performance by exploiting synthetic training data. In this work, we propose AIGeN, a novel architecture inspired by Generative Adversarial Networks (GANs) that produces meaningful and well-formed synthetic instructions to improve navigation agents' performance. The model is composed of a Transformer decoder (GPT-2) and a Transformer encoder (BERT). During the training phase, the decoder generates sentences for a sequence of images describing the agent's path to a particular point while the encoder discriminates between real and fake instructions. Experimentally, we evaluate the quality of the generated instructions and perform extensive ablation studies. Additionally, we generate synthetic instructions for 217K trajectories using AIGeN on Habitat-Matterport 3D Dataset (HM3D) and show an improvement in the performance of an off-the-shelf VLN method. The validation analysis of our proposal is conducted on REVERIE and R2R and highlights the promising aspects of our proposal, achieving state-of-the-art performance.
Mapping High-level Semantic Regions in Indoor Environments without Object Recognition
Mar 11, 2024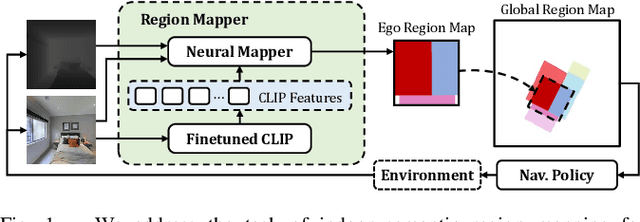

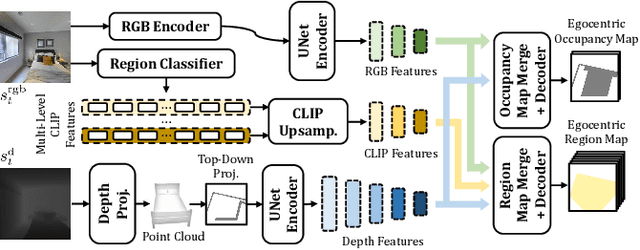
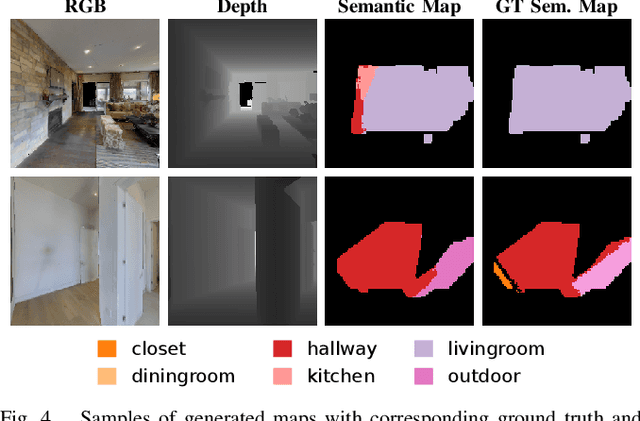
Robots require a semantic understanding of their surroundings to operate in an efficient and explainable way in human environments. In the literature, there has been an extensive focus on object labeling and exhaustive scene graph generation; less effort has been focused on the task of purely identifying and mapping large semantic regions. The present work proposes a method for semantic region mapping via embodied navigation in indoor environments, generating a high-level representation of the knowledge of the agent. To enable region identification, the method uses a vision-to-language model to provide scene information for mapping. By projecting egocentric scene understanding into the global frame, the proposed method generates a semantic map as a distribution over possible region labels at each location. This mapping procedure is paired with a trained navigation policy to enable autonomous map generation. The proposed method significantly outperforms a variety of baselines, including an object-based system and a pretrained scene classifier, in experiments in a photorealistic simulator.
Embodied Agents for Efficient Exploration and Smart Scene Description
Jan 17, 2023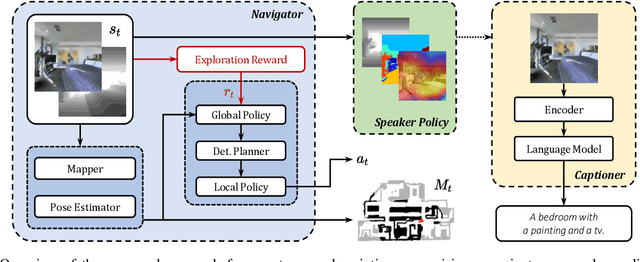



The development of embodied agents that can communicate with humans in natural language has gained increasing interest over the last years, as it facilitates the diffusion of robotic platforms in human-populated environments. As a step towards this objective, in this work, we tackle a setting for visual navigation in which an autonomous agent needs to explore and map an unseen indoor environment while portraying interesting scenes with natural language descriptions. To this end, we propose and evaluate an approach that combines recent advances in visual robotic exploration and image captioning on images generated through agent-environment interaction. Our approach can generate smart scene descriptions that maximize semantic knowledge of the environment and avoid repetitions. Further, such descriptions offer user-understandable insights into the robot's representation of the environment by highlighting the prominent objects and the correlation between them as encountered during the exploration. To quantitatively assess the performance of the proposed approach, we also devise a specific score that takes into account both exploration and description skills. The experiments carried out on both photorealistic simulated environments and real-world ones demonstrate that our approach can effectively describe the robot's point of view during exploration, improving the human-friendly interpretability of its observations.
Embodied Navigation at the Art Gallery
Apr 19, 2022

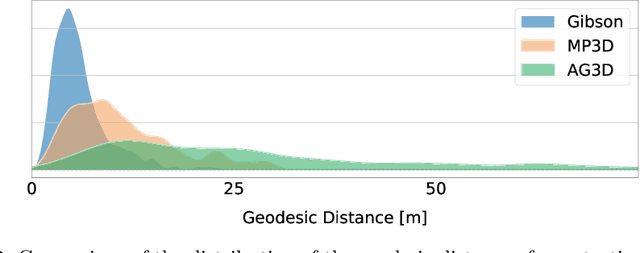
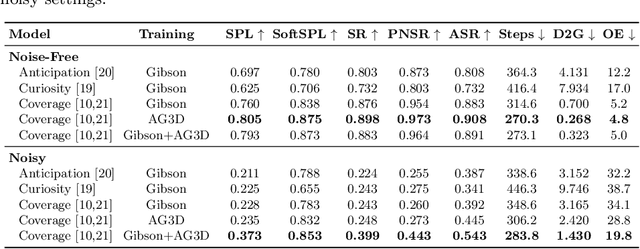
Embodied agents, trained to explore and navigate indoor photorealistic environments, have achieved impressive results on standard datasets and benchmarks. So far, experiments and evaluations have involved domestic and working scenes like offices, flats, and houses. In this paper, we build and release a new 3D space with unique characteristics: the one of a complete art museum. We name this environment ArtGallery3D (AG3D). Compared with existing 3D scenes, the collected space is ampler, richer in visual features, and provides very sparse occupancy information. This feature is challenging for occupancy-based agents which are usually trained in crowded domestic environments with plenty of occupancy information. Additionally, we annotate the coordinates of the main points of interest inside the museum, such as paintings, statues, and other items. Thanks to this manual process, we deliver a new benchmark for PointGoal navigation inside this new space. Trajectories in this dataset are far more complex and lengthy than existing ground-truth paths for navigation in Gibson and Matterport3D. We carry on extensive experimental evaluation using our new space for evaluation and prove that existing methods hardly adapt to this scenario. As such, we believe that the availability of this 3D model will foster future research and help improve existing solutions.
Spot the Difference: A Novel Task for Embodied Agents in Changing Environments
Apr 18, 2022



Embodied AI is a recent research area that aims at creating intelligent agents that can move and operate inside an environment. Existing approaches in this field demand the agents to act in completely new and unexplored scenes. However, this setting is far from realistic use cases that instead require executing multiple tasks in the same environment. Even if the environment changes over time, the agent could still count on its global knowledge about the scene while trying to adapt its internal representation to the current state of the environment. To make a step towards this setting, we propose Spot the Difference: a novel task for Embodied AI where the agent has access to an outdated map of the environment and needs to recover the correct layout in a fixed time budget. To this end, we collect a new dataset of occupancy maps starting from existing datasets of 3D spaces and generating a number of possible layouts for a single environment. This dataset can be employed in the popular Habitat simulator and is fully compliant with existing methods that employ reconstructed occupancy maps during navigation. Furthermore, we propose an exploration policy that can take advantage of previous knowledge of the environment and identify changes in the scene faster and more effectively than existing agents. Experimental results show that the proposed architecture outperforms existing state-of-the-art models for exploration on this new setting.
Focus on Impact: Indoor Exploration with Intrinsic Motivation
Sep 14, 2021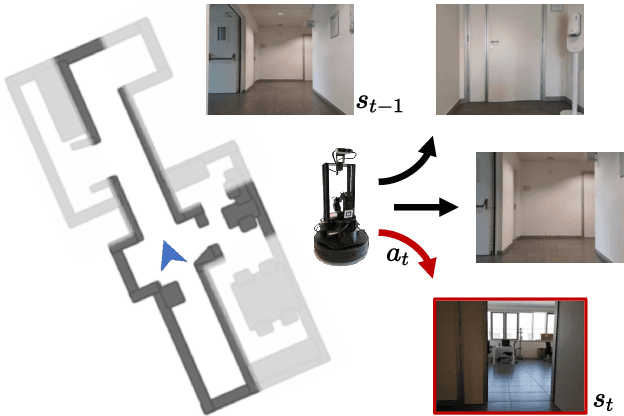
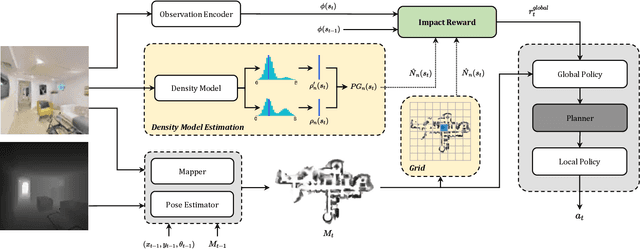

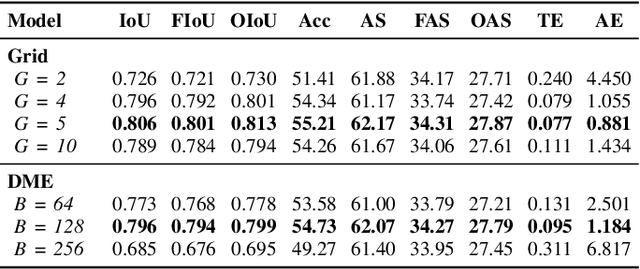
Exploration of indoor environments has recently experienced a significant interest, also thanks to the introduction of deep neural agents built in a hierarchical fashion and trained with Deep Reinforcement Learning (DRL) on simulated environments. Current state-of-the-art methods employ a dense extrinsic reward that requires the complete a priori knowledge of the layout of the training environment to learn an effective exploration policy. However, such information is expensive to gather in terms of time and resources. In this work, we propose to train the model with a purely intrinsic reward signal to guide exploration, which is based on the impact of the robot's actions on the environment. So far, impact-based rewards have been employed for simple tasks and in procedurally generated synthetic environments with countable states. Since the number of states observable by the agent in realistic indoor environments is non-countable, we include a neural-based density model and replace the traditional count-based regularization with an estimated pseudo-count of previously visited states. The proposed exploration approach outperforms DRL-based competitors relying on intrinsic rewards and surpasses the agents trained with a dense extrinsic reward computed with the environment layouts. We also show that a robot equipped with the proposed approach seamlessly adapts to point-goal navigation and real-world deployment.
Out of the Box: Embodied Navigation in the Real World
May 12, 2021


The research field of Embodied AI has witnessed substantial progress in visual navigation and exploration thanks to powerful simulating platforms and the availability of 3D data of indoor and photorealistic environments. These two factors have opened the doors to a new generation of intelligent agents capable of achieving nearly perfect PointGoal Navigation. However, such architectures are commonly trained with millions, if not billions, of frames and tested in simulation. Together with great enthusiasm, these results yield a question: how many researchers will effectively benefit from these advances? In this work, we detail how to transfer the knowledge acquired in simulation into the real world. To that end, we describe the architectural discrepancies that damage the Sim2Real adaptation ability of models trained on the Habitat simulator and propose a novel solution tailored towards the deployment in real-world scenarios. We then deploy our models on a LoCoBot, a Low-Cost Robot equipped with a single Intel RealSense camera. Different from previous work, our testing scene is unavailable to the agent in simulation. The environment is also inaccessible to the agent beforehand, so it cannot count on scene-specific semantic priors. In this way, we reproduce a setting in which a research group (potentially from other fields) needs to employ the agent visual navigation capabilities as-a-Service. Our experiments indicate that it is possible to achieve satisfying results when deploying the obtained model in the real world. Our code and models are available at https://github.com/aimagelab/LoCoNav.