 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNMuTe: Unifying Navigation and Multimodal Dialogue-like Text Generation
Aug 08, 2024
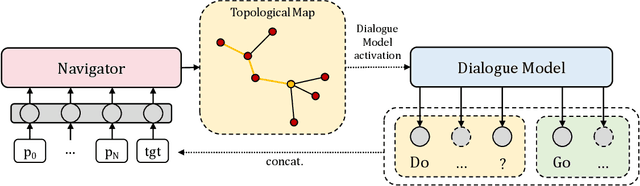
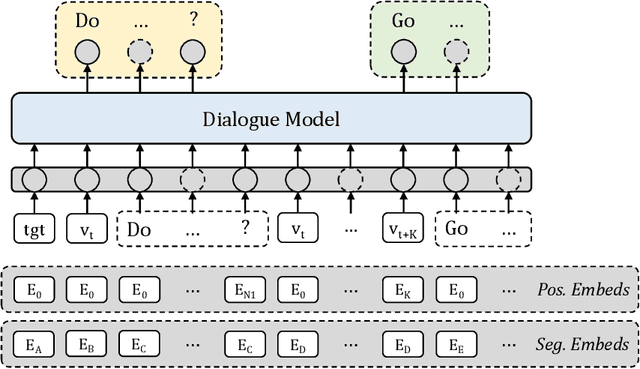
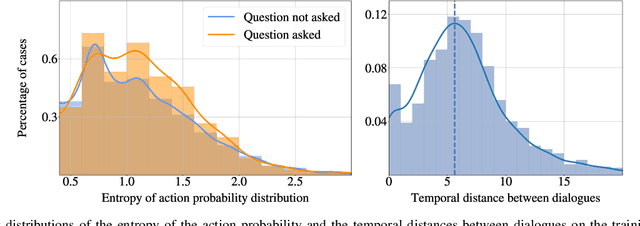
Smart autonomous agents are becoming increasingly important in various real-life applications, including robotics and autonomous vehicles. One crucial skill that these agents must possess is the ability to interact with their surrounding entities, such as other agents or humans. In this work, we aim at building an intelligent agent that can efficiently navigate in an environment while being able to interact with an oracle (or human) in natural language and ask for directions when it is unsure about its navigation performance. The interaction is started by the agent that produces a question, which is then answered by the oracle on the basis of the shortest trajectory to the goal. The process can be performed multiple times during navigation, thus enabling the agent to hold a dialogue with the oracle. To this end, we propose a novel computational model, named UNMuTe, that consists of two main components: a dialogue model and a navigator. Specifically, the dialogue model is based on a GPT-2 decoder that handles multimodal data consisting of both text and images. First, the dialogue model is trained to generate question-answer pairs: the question is generated using the current image, while the answer is produced leveraging future images on the path toward the goal. Subsequently, a VLN model is trained to follow the dialogue predicting navigation actions or triggering the dialogue model if it needs help. In our experimental analysis, we show that UNMuTe achieves state-of-the-art performance on the main navigation tasks implying dialogue, i.e. Cooperative Vision and Dialogue Navigation (CVDN) and Navigation from Dialogue History (NDH), proving that our approach is effective in generating useful questions and answers to guide navigation.
AIGeN: An Adversarial Approach for Instruction Generation in VLN
Apr 15, 2024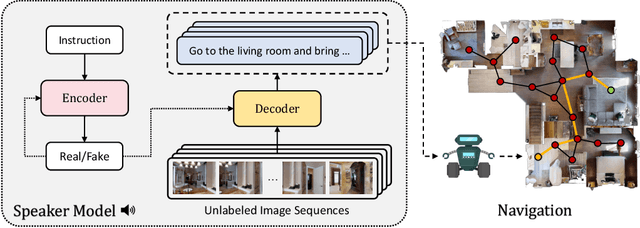
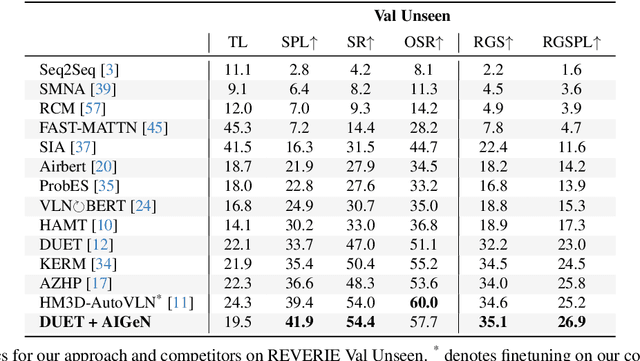
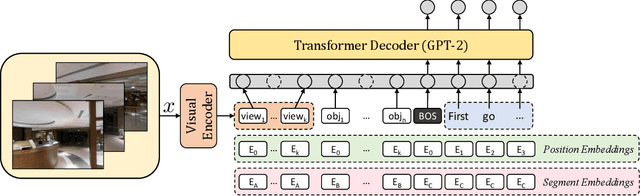
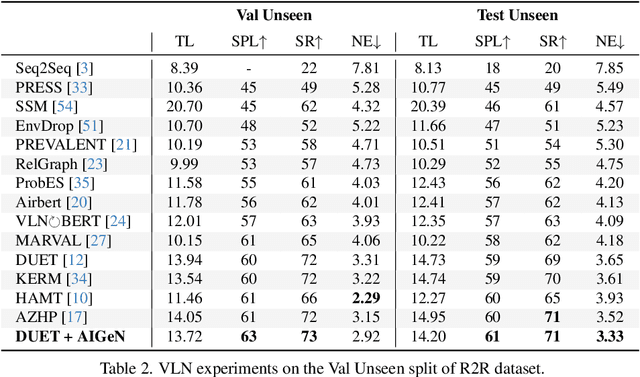
In the last few years, the research interest in Vision-and-Language Navigation (VLN) has grown significantly. VLN is a challenging task that involves an agent following human instructions and navigating in a previously unknown environment to reach a specified goal. Recent work in literature focuses on different ways to augment the available datasets of instructions for improving navigation performance by exploiting synthetic training data. In this work, we propose AIGeN, a novel architecture inspired by Generative Adversarial Networks (GANs) that produces meaningful and well-formed synthetic instructions to improve navigation agents' performance. The model is composed of a Transformer decoder (GPT-2) and a Transformer encoder (BERT). During the training phase, the decoder generates sentences for a sequence of images describing the agent's path to a particular point while the encoder discriminates between real and fake instructions. Experimentally, we evaluate the quality of the generated instructions and perform extensive ablation studies. Additionally, we generate synthetic instructions for 217K trajectories using AIGeN on Habitat-Matterport 3D Dataset (HM3D) and show an improvement in the performance of an off-the-shelf VLN method. The validation analysis of our proposal is conducted on REVERIE and R2R and highlights the promising aspects of our proposal, achieving state-of-the-art performance.
Facial emotion expressions in human-robot interaction: A survey
Mar 12, 2021
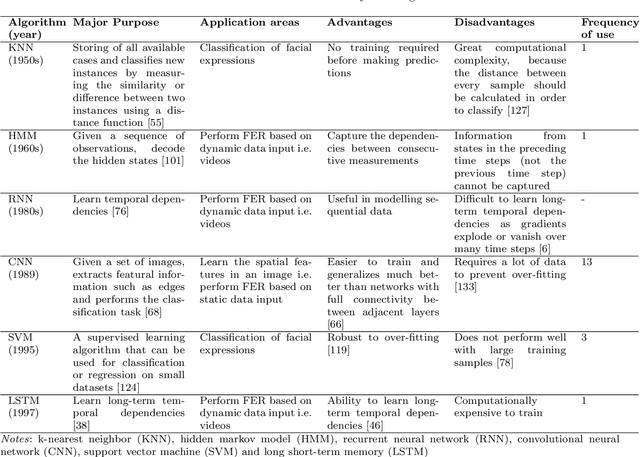
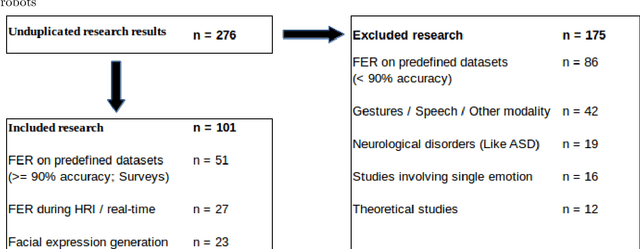
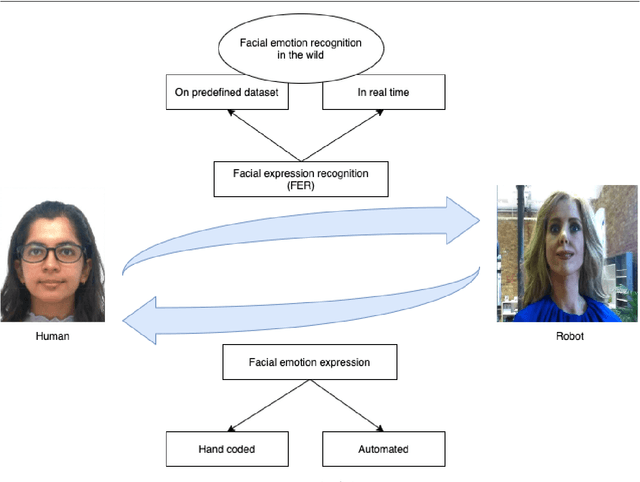
Facial expressions are an ideal means of communicating one's emotions or intentions to others. This overview will focus on human facial expression recognition as well as robotic facial expression generation. In case of human facial expression recognition, both facial expression recognition on predefined datasets as well as in real time will be covered. For robotic facial expression generation, hand coded and automated methods i.e., facial expressions of a robot are generated by moving the features (eyes, mouth) of the robot by hand coding or automatically using machine learning techniques, will also be covered. There are already plenty of studies that achieve high accuracy for emotion expression recognition on predefined datasets, but the accuracy for facial expression recognition in real time is comparatively lower. In case of expression generation in robots, while most of the robots are capable of making basic facial expressions, there are not many studies that enable robots to do so automatically.