 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagLab: A human-centric AI system for interactive semantic segmentation
Dec 23, 2021
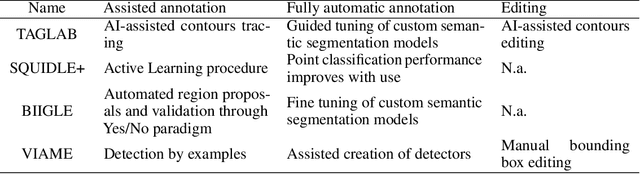


Fully automatic semantic segmentation of highly specific semantic classes and complex shapes may not meet the accuracy standards demanded by scientists. In such cases, human-centered AI solutions, able to assist operators while preserving human control over complex tasks, are a good trade-off to speed up image labeling while maintaining high accuracy levels. TagLab is an open-source AI-assisted software for annotating large orthoimages which takes advantage of different degrees of automation; it speeds up image annotation from scratch through assisted tools, creates custom fully automatic semantic segmentation models, and, finally, allows the quick edits of automatic predictions. Since the orthoimages analysis applies to several scientific disciplines, TagLab has been designed with a flexible labeling pipeline. We report our results in two different scenarios, marine ecology, and architectural heritage.
Perceive, Transform, and Act: Multi-Modal Attention Networks for Vision-and-Language Navigation
Nov 27, 2019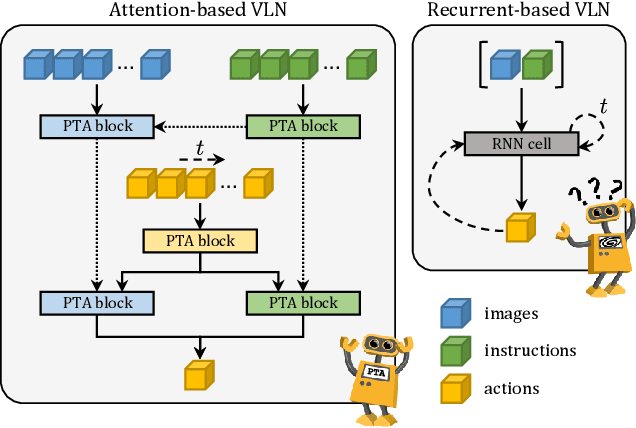
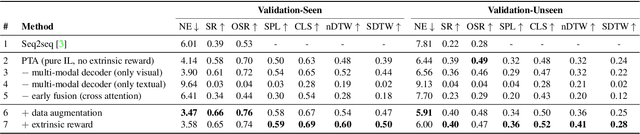
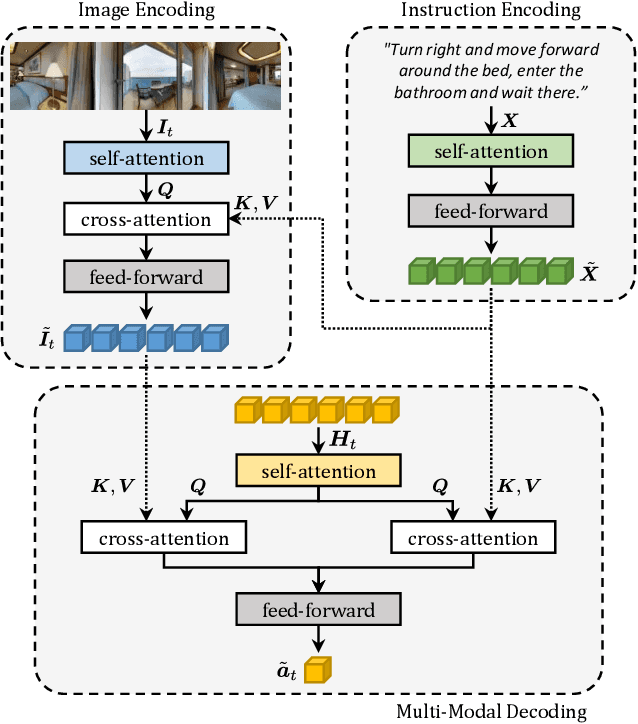
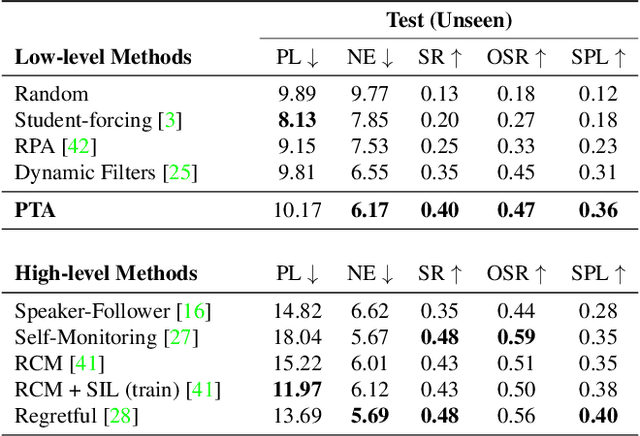
Vision-and-Language Navigation (VLN) is a challenging task in which an agent needs to follow a language-specified path to reach a target destination. In this paper, we strive for the creation of an agent able to tackle three key issues: multi-modality, long-term dependencies, and adaptability towards different locomotive settings. To that end, we devise "Perceive, Transform, and Act" (PTA): a fully-attentive VLN architecture that leaves the recurrent approach behind and the first Transformer-like architecture incorporating three different modalities - natural language, images, and discrete actions for the agent control. In particular, we adopt an early fusion strategy to merge lingual and visual information efficiently in our encoder. We then propose to refine the decoding phase with a late fusion extension between the agent's history of actions and the perception modalities. We experimentally validate our model on two datasets and two different action settings. PTA surpasses previous state-of-the-art architectures for low-level VLN on R2R and achieves the first place for both setups in the recently proposed R4R benchmark. Our code is publicly available at https://github.com/aimagelab/perceive-transform-and-act.
Embodied Vision-and-Language Navigation with Dynamic Convolutional Filters
Jul 05, 2019
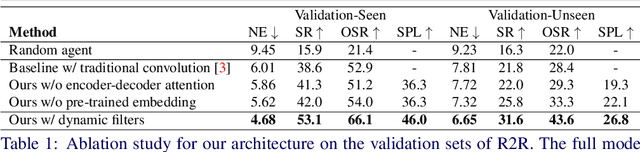
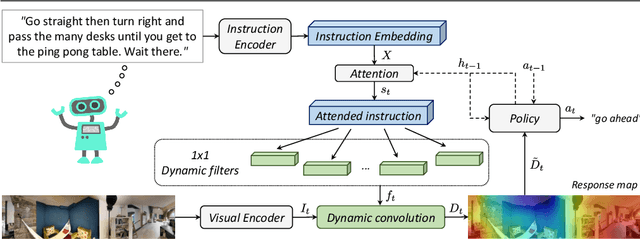
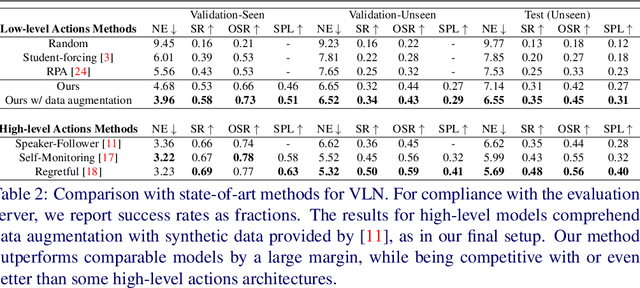
In Vision-and-Language Navigation (VLN), an embodied agent needs to reach a target destination with the only guidance of a natural language instruction. To explore the environment and progress towards the target location, the agent must perform a series of low-level actions, such as rotate, before stepping ahead. In this paper, we propose to exploit dynamic convolutional filters to encode the visual information and the lingual description in an efficient way. Differently from some previous works that abstract from the agent perspective and use high-level navigation spaces, we design a policy which decodes the information provided by dynamic convolution into a series of low-level, agent friendly actions. Results show that our model exploiting dynamic filters performs better than other architectures with traditional convolution, being the new state of the art for embodied VLN in the low-level action space. Additionally, we attempt to categorize recent work on VLN depending on their architectural choices and distinguish two main groups: we call them low-level actions and high-level actions models. To the best of our knowledge, we are the first to propose this analysis and categorization for VLN.