 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe:Draw -- Context Aware Translation as a Controllable Method for Artistic Production
Jan 07, 2024
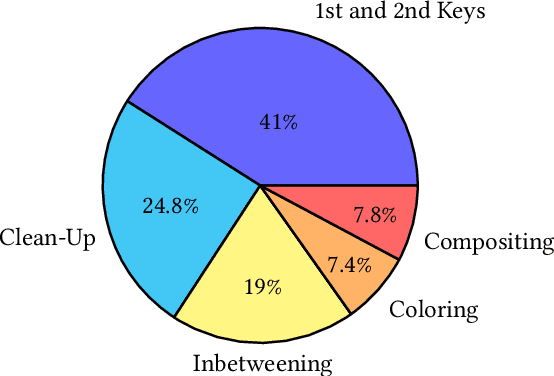
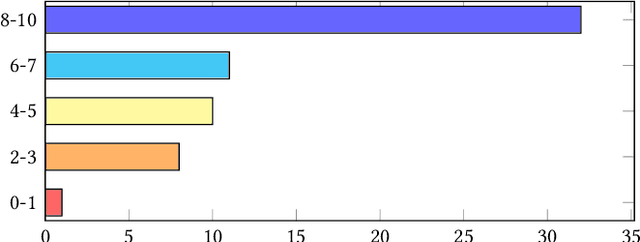
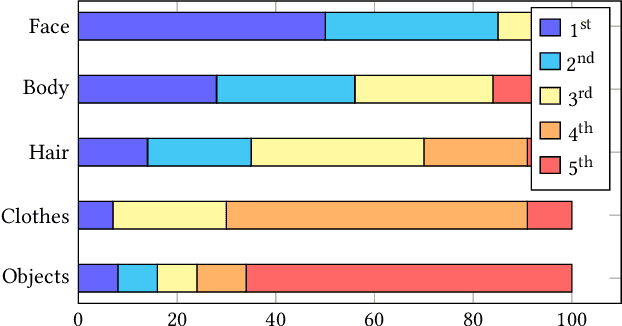
We introduce context-aware translation, a novel method that combines the benefits of inpainting and image-to-image translation, respecting simultaneously the original input and contextual relevance -- where existing methods fall short. By doing so, our method opens new avenues for the controllable use of AI within artistic creation, from animation to digital art. As an use case, we apply our method to redraw any hand-drawn animated character eyes based on any design specifications - eyes serve as a focal point that captures viewer attention and conveys a range of emotions, however, the labor-intensive nature of traditional animation often leads to compromises in the complexity and consistency of eye design. Furthermore, we remove the need for production data for training and introduce a new character recognition method that surpasses existing work by not requiring fine-tuning to specific productions. This proposed use case could help maintain consistency throughout production and unlock bolder and more detailed design choices without the production cost drawbacks. A user study shows context-aware translation is preferred over existing work 95.16% of the time.
TagLab: A human-centric AI system for interactive semantic segmentation
Dec 23, 2021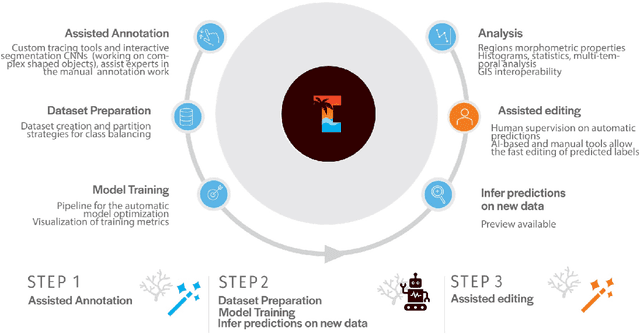
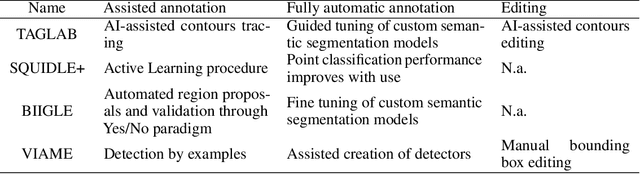


Fully automatic semantic segmentation of highly specific semantic classes and complex shapes may not meet the accuracy standards demanded by scientists. In such cases, human-centered AI solutions, able to assist operators while preserving human control over complex tasks, are a good trade-off to speed up image labeling while maintaining high accuracy levels. TagLab is an open-source AI-assisted software for annotating large orthoimages which takes advantage of different degrees of automation; it speeds up image annotation from scratch through assisted tools, creates custom fully automatic semantic segmentation models, and, finally, allows the quick edits of automatic predictions. Since the orthoimages analysis applies to several scientific disciplines, TagLab has been designed with a flexible labeling pipeline. We report our results in two different scenarios, marine ecology, and architectural heritage.
DeepFlash: Turning a Flash Selfie into a Studio Portrait
Jan 14, 2019

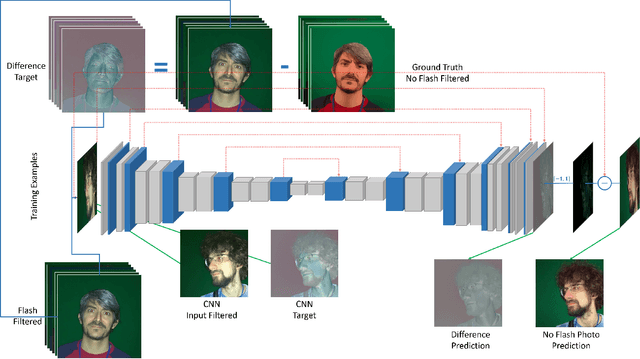

We present a method for turning a flash selfie taken with a smartphone into a photograph as if it was taken in a studio setting with uniform lighting. Our method uses a convolutional neural network trained on a set of pairs of photographs acquired in an ad-hoc acquisition campaign. Each pair consists of one photograph of a subject's face taken with the camera flash enabled and another one of the same subject in the same pose illuminated using a photographic studio-lighting setup. We show how our method can amend defects introduced by a close-up camera flash, such as specular highlights, shadows, skin shine, and flattened images.