 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes 3D Gaussian Splatting Need Accurate Volumetric Rendering?
Feb 26, 2025
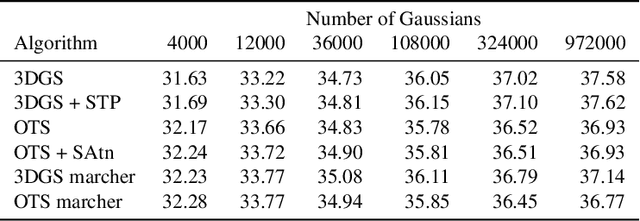
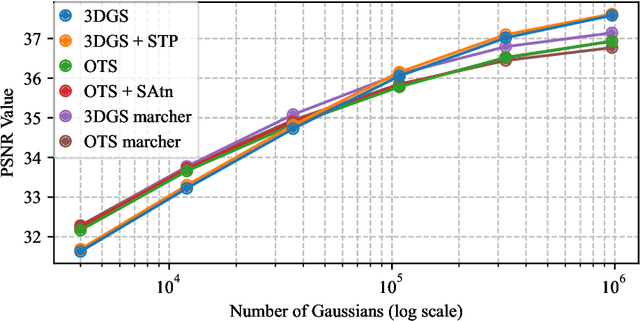
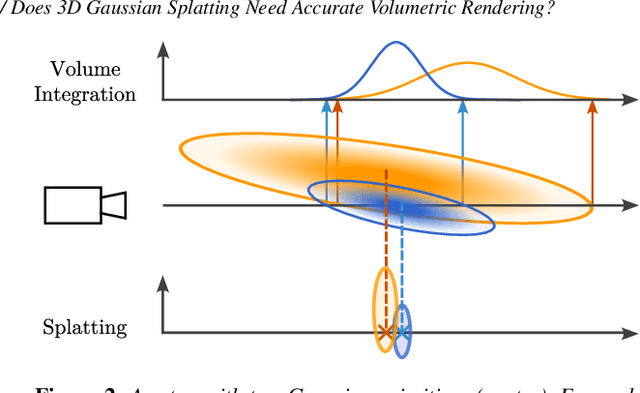
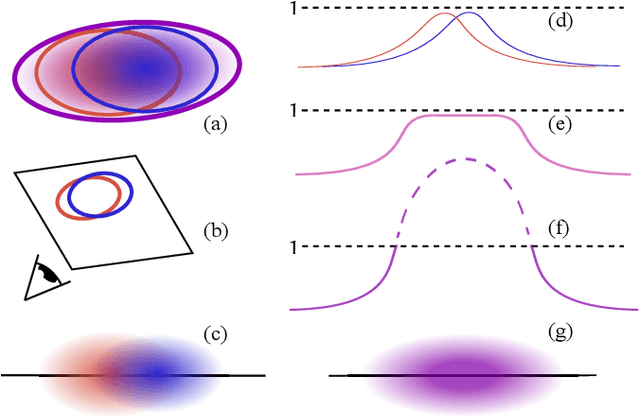
Since its introduction, 3D Gaussian Splatting (3DGS) has become an important reference method for learning 3D representations of a captured scene, allowing real-time novel-view synthesis with high visual quality and fast training times. Neural Radiance Fields (NeRFs), which preceded 3DGS, are based on a principled ray-marching approach for volumetric rendering. In contrast, while sharing a similar image formation model with NeRF, 3DGS uses a hybrid rendering solution that builds on the strengths of volume rendering and primitive rasterization. A crucial benefit of 3DGS is its performance, achieved through a set of approximations, in many cases with respect to volumetric rendering theory. A naturally arising question is whether replacing these approximations with more principled volumetric rendering solutions can improve the quality of 3DGS. In this paper, we present an in-depth analysis of the various approximations and assumptions used by the original 3DGS solution. We demonstrate that, while more accurate volumetric rendering can help for low numbers of primitives, the power of efficient optimization and the large number of Gaussians allows 3DGS to outperform volumetric rendering despite its approximations.
A Hierarchical 3D Gaussian Representation for Real-Time Rendering of Very Large Datasets
Jun 17, 2024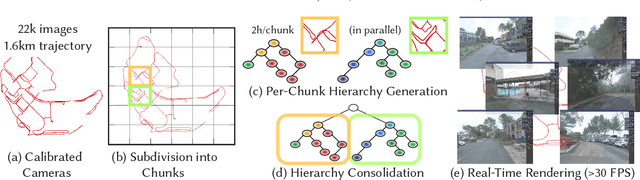
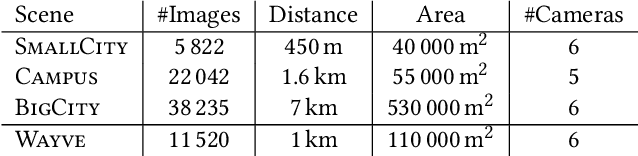
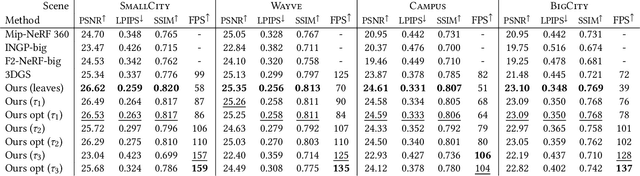
Novel view synthesis has seen major advances in recent years, with 3D Gaussian splatting offering an excellent level of visual quality, fast training and real-time rendering. However, the resources needed for training and rendering inevitably limit the size of the captured scenes that can be represented with good visual quality. We introduce a hierarchy of 3D Gaussians that preserves visual quality for very large scenes, while offering an efficient Level-of-Detail (LOD) solution for efficient rendering of distant content with effective level selection and smooth transitions between levels.We introduce a divide-and-conquer approach that allows us to train very large scenes in independent chunks. We consolidate the chunks into a hierarchy that can be optimized to further improve visual quality of Gaussians merged into intermediate nodes. Very large captures typically have sparse coverage of the scene, presenting many challenges to the original 3D Gaussian splatting training method; we adapt and regularize training to account for these issues. We present a complete solution, that enables real-time rendering of very large scenes and can adapt to available resources thanks to our LOD method. We show results for captured scenes with up to tens of thousands of images with a simple and affordable rig, covering trajectories of up to several kilometers and lasting up to one hour. Project Page: https://repo-sam.inria.fr/fungraph/hierarchical-3d-gaussians/
* Project Page: https://repo-sam.inria.fr/fungraph/hierarchical-3d-gaussians/
Re:Draw -- Context Aware Translation as a Controllable Method for Artistic Production
Jan 07, 2024
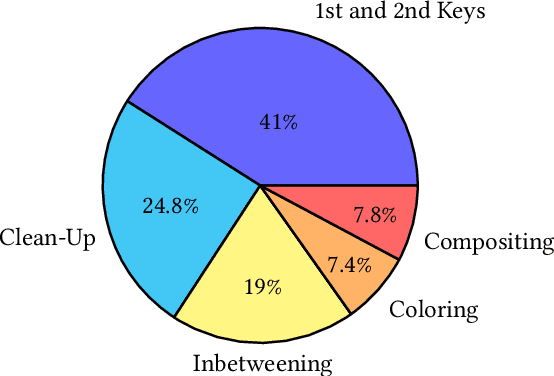
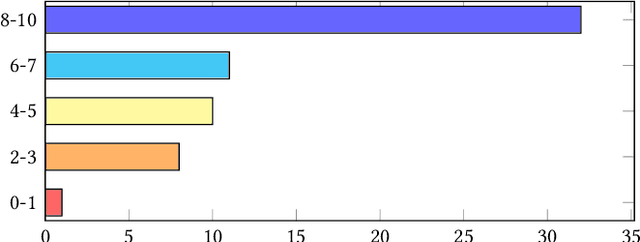
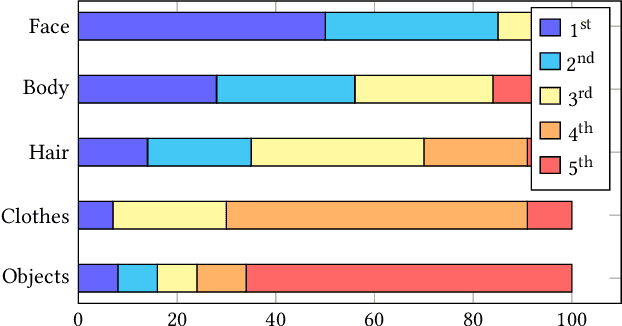
We introduce context-aware translation, a novel method that combines the benefits of inpainting and image-to-image translation, respecting simultaneously the original input and contextual relevance -- where existing methods fall short. By doing so, our method opens new avenues for the controllable use of AI within artistic creation, from animation to digital art. As an use case, we apply our method to redraw any hand-drawn animated character eyes based on any design specifications - eyes serve as a focal point that captures viewer attention and conveys a range of emotions, however, the labor-intensive nature of traditional animation often leads to compromises in the complexity and consistency of eye design. Furthermore, we remove the need for production data for training and introduce a new character recognition method that surpasses existing work by not requiring fine-tuning to specific productions. This proposed use case could help maintain consistency throughout production and unlock bolder and more detailed design choices without the production cost drawbacks. A user study shows context-aware translation is preferred over existing work 95.16% of the time.
Training and Predicting Visual Error for Real-Time Applications
Oct 13, 2023
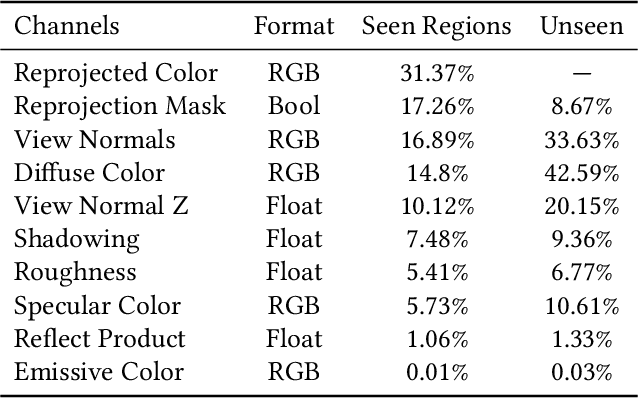
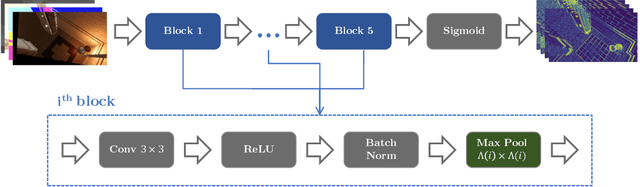
Visual error metrics play a fundamental role in the quantification of perceived image similarity. Most recently, use cases for them in real-time applications have emerged, such as content-adaptive shading and shading reuse to increase performance and improve efficiency. A wide range of different metrics has been established, with the most sophisticated being capable of capturing the perceptual characteristics of the human visual system. However, their complexity, computational expense, and reliance on reference images to compare against prevent their generalized use in real-time, restricting such applications to using only the simplest available metrics. In this work, we explore the abilities of convolutional neural networks to predict a variety of visual metrics without requiring either reference or rendered images. Specifically, we train and deploy a neural network to estimate the visual error resulting from reusing shading or using reduced shading rates. The resulting models account for 70%-90% of the variance while achieving up to an order of magnitude faster computation times. Our solution combines image-space information that is readily available in most state-of-the-art deferred shading pipelines with reprojection from previous frames to enable an adequate estimate of visual errors, even in previously unseen regions. We describe a suitable convolutional network architecture and considerations for data preparation for training. We demonstrate the capability of our network to predict complex error metrics at interactive rates in a real-time application that implements content-adaptive shading in a deferred pipeline. Depending on the portion of unseen image regions, our approach can achieve up to $2\times$ performance compared to state-of-the-art methods.
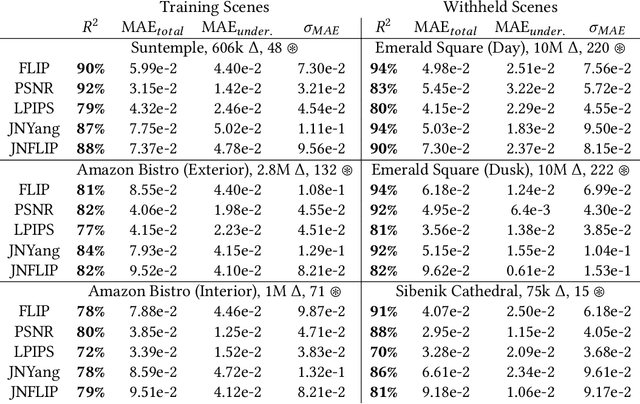
* Published at Proceedings of the ACM in Computer Graphics and Interactive Techniques. 14 Pages, 16 Figures, 3 Tables. For paper website and higher quality figures, see https://jaliborc.github.io/rt-percept/
Assesment of material layers in building walls using GeoRadar
Aug 25, 2022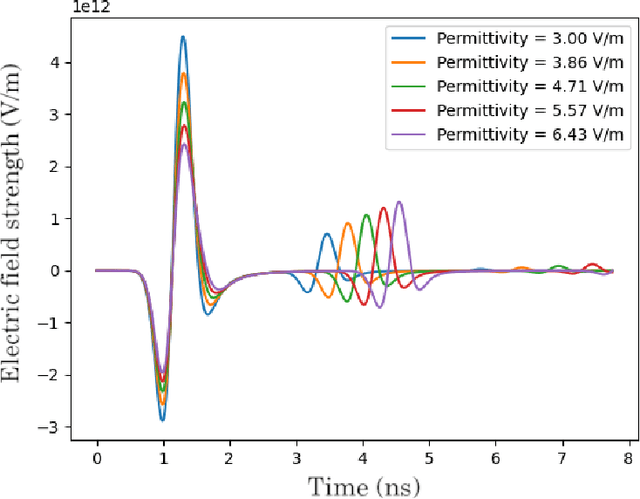
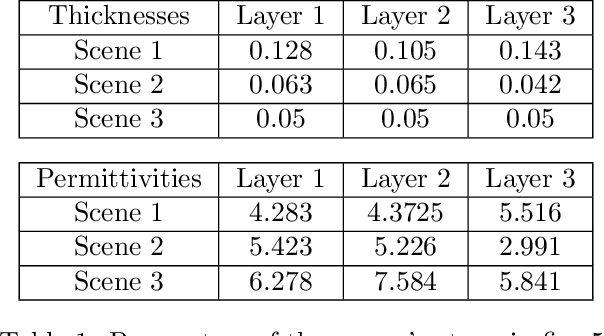
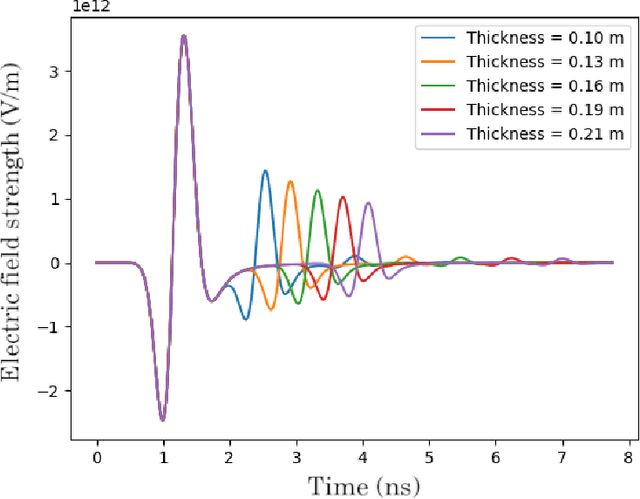
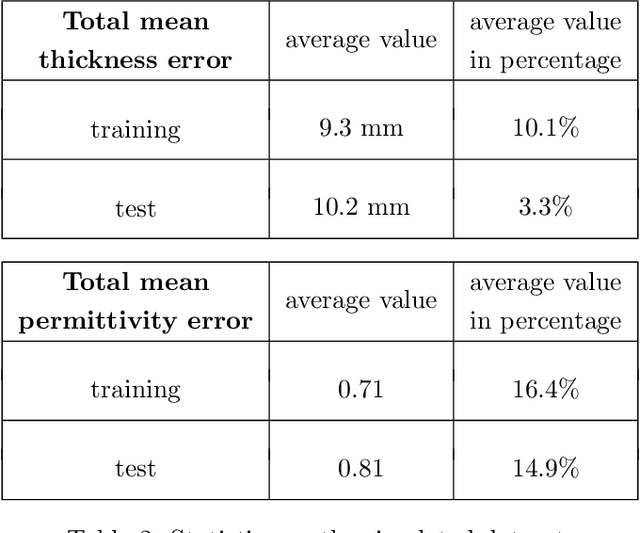
Assessing the structure of a building with non-invasive methods is an important problem. One of the possible approaches is to use GeoRadar to examine wall structures by analyzing the data obtained from the scans. We propose a data-driven approach to evaluate the material composition of a wall from its GPR radargrams. In order to generate training data, we use gprMax to model the scanning process. Using simulation data, we use a convolutional neural network to predict the thicknesses and dielectric properties of walls per layer. We evaluate the generalization abilities of the trained model on data collected from real buildings.
Gaussian Mixture Convolution Networks
Feb 18, 2022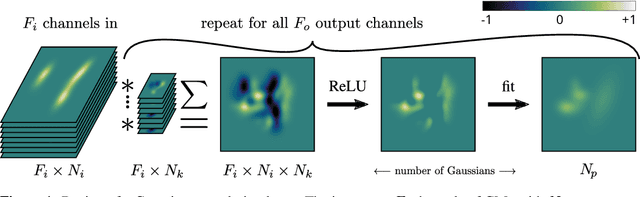
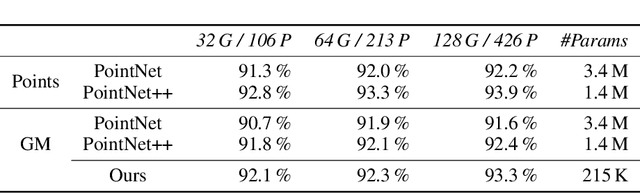


This paper proposes a novel method for deep learning based on the analytical convolution of multidimensional Gaussian mixtures. In contrast to tensors, these do not suffer from the curse of dimensionality and allow for a compact representation, as data is only stored where details exist. Convolution kernels and data are Gaussian mixtures with unconstrained weights, positions, and covariance matrices. Similar to discrete convolutional networks, each convolution step produces several feature channels, represented by independent Gaussian mixtures. Since traditional transfer functions like ReLUs do not produce Gaussian mixtures, we propose using a fitting of these functions instead. This fitting step also acts as a pooling layer if the number of Gaussian components is reduced appropriately. We demonstrate that networks based on this architecture reach competitive accuracy on Gaussian mixtures fitted to the MNIST and ModelNet data sets.
Points2Surf: Learning Implicit Surfaces from Point Cloud Patches
Jul 20, 2020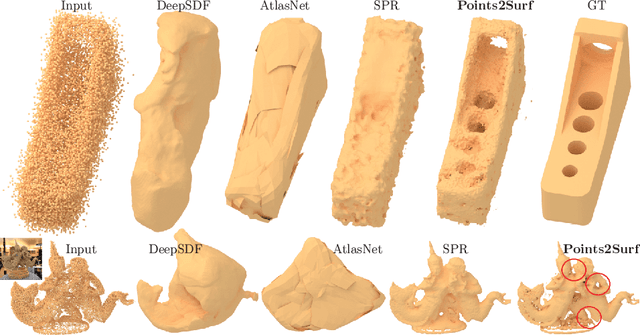
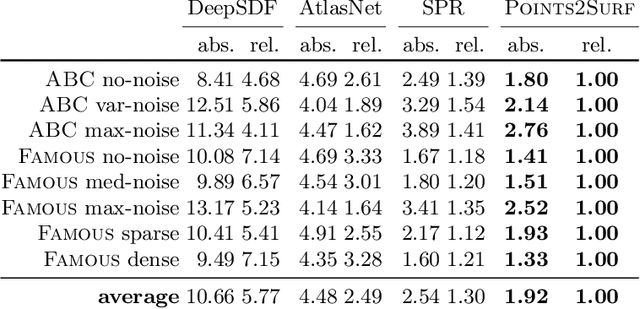

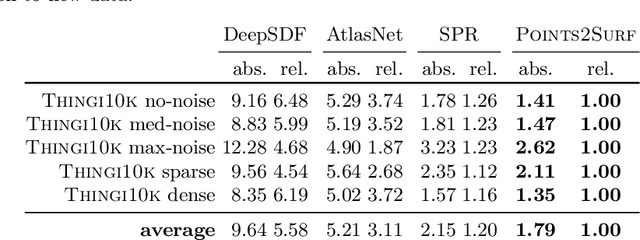
A key step in any scanning-based asset creation workflow is to convert unordered point clouds to a surface. Classical methods (e.g., Poisson reconstruction) start to degrade in the presence of noisy and partial scans. Hence, deep learning based methods have recently been proposed to produce complete surfaces, even from partial scans. However, such data-driven methods struggle to generalize to new shapes with large geometric and topological variations. We present Points2Surf, a novel patch-based learning framework that produces accurate surfaces directly from raw scans without normals. Learning a prior over a combination of detailed local patches and coarse global information improves generalization performance and reconstruction accuracy. Our extensive comparison on both synthetic and real data demonstrates a clear advantage of our method over state-of-the-art alternatives on previously unseen classes (on average, Points2Surf brings down reconstruction error by 30\% over SPR and by 270\%+ over deep learning based SotA methods) at the cost of longer computation times and a slight increase in small-scale topological noise in some cases. Our source code, pre-trained model, and dataset are available on: https://github.com/ErlerPhilipp/points2surf
Photorealistic Material Editing Through Direct Image Manipulation
Sep 12, 2019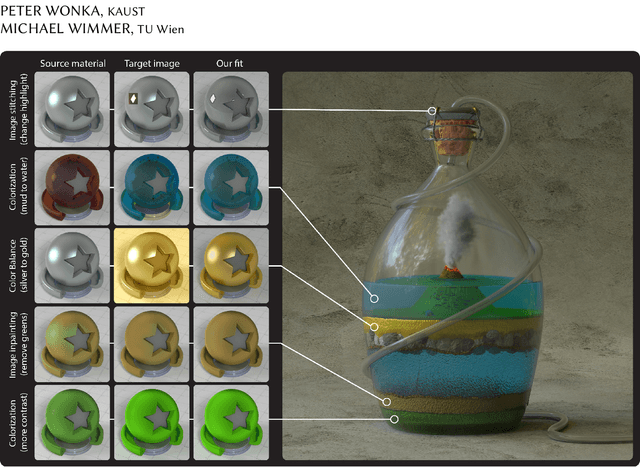
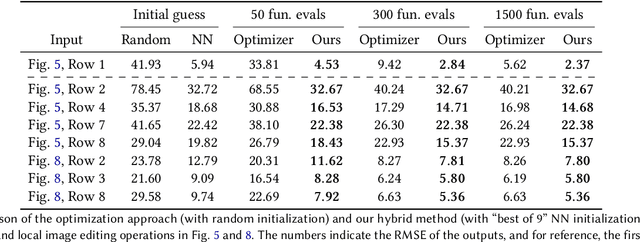
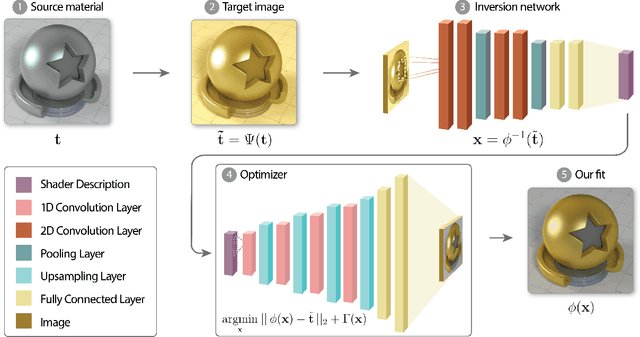
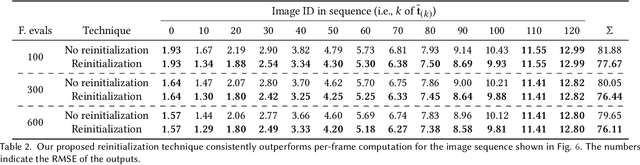
Creating photorealistic materials for light transport algorithms requires carefully fine-tuning a set of material properties to achieve a desired artistic effect. This is typically a lengthy process that involves a trained artist with specialized knowledge. In this work, we present a technique that aims to empower novice and intermediate-level users to synthesize high-quality photorealistic materials by only requiring basic image processing knowledge. In the proposed workflow, the user starts with an input image and applies a few intuitive transforms (e.g., colorization, image inpainting) within a 2D image editor of their choice, and in the next step, our technique produces a photorealistic result that approximates this target image. Our method combines the advantages of a neural network-augmented optimizer and an encoder neural network to produce high-quality output results within 30 seconds. We also demonstrate that it is resilient against poorly-edited target images and propose a simple extension to predict image sequences with a strict time budget of 1-2 seconds per image.
Gaussian Material Synthesis
Apr 23, 2018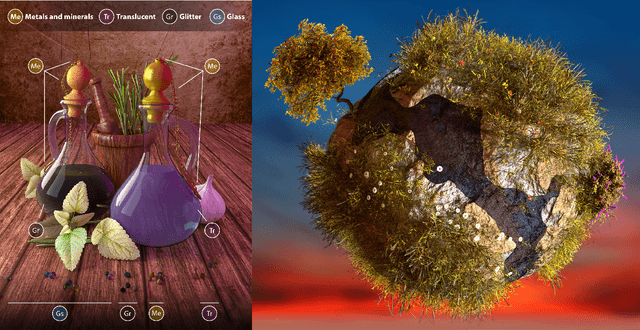


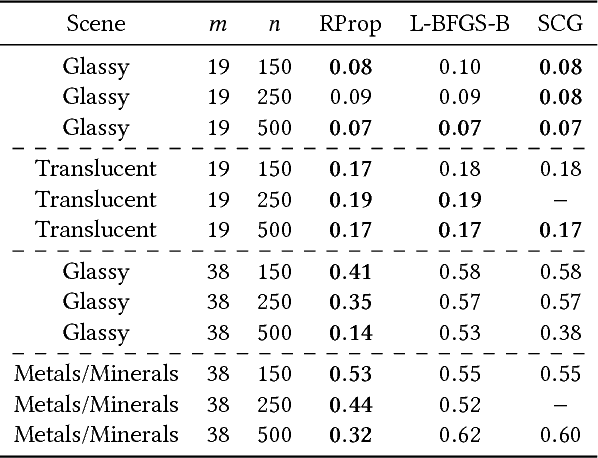
We present a learning-based system for rapid mass-scale material synthesis that is useful for novice and expert users alike. The user preferences are learned via Gaussian Process Regression and can be easily sampled for new recommendations. Typically, each recommendation takes 40-60 seconds to render with global illumination, which makes this process impracticable for real-world workflows. Our neural network eliminates this bottleneck by providing high-quality image predictions in real time, after which it is possible to pick the desired materials from a gallery and assign them to a scene in an intuitive manner. Workflow timings against Disney's "principled" shader reveal that our system scales well with the number of sought materials, thus empowering even novice users to generate hundreds of high-quality material models without any expertise in material modeling. Similarly, expert users experience a significant decrease in the total modeling time when populating a scene with materials. Furthermore, our proposed solution also offers controllable recommendations and a novel latent space variant generation step to enable the real-time fine-tuning of materials without requiring any domain expertise.
* Supplementary data and source code: https://users.cg.tuwien.ac.at/zsolnai/gfx/gaussian-material-synthesis/