 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing the Memory Footprint of 3D Gaussian Splatting
Jun 24, 20243D Gaussian splatting provides excellent visual quality for novel view synthesis, with fast training and real-time rendering; unfortunately, the memory requirements of this method for storing and transmission are unreasonably high. We first analyze the reasons for this, identifying three main areas where storage can be reduced: the number of 3D Gaussian primitives used to represent a scene, the number of coefficients for the spherical harmonics used to represent directional radiance, and the precision required to store Gaussian primitive attributes. We present a solution to each of these issues. First, we propose an efficient, resolution-aware primitive pruning approach, reducing the primitive count by half. Second, we introduce an adaptive adjustment method to choose the number of coefficients used to represent directional radiance for each Gaussian primitive, and finally a codebook-based quantization method, together with a half-float representation for further memory reduction. Taken together, these three components result in a 27 reduction in overall size on disk on the standard datasets we tested, along with a 1.7 speedup in rendering speed. We demonstrate our method on standard datasets and show how our solution results in significantly reduced download times when using the method on a mobile device.
* Project website: https://repo-sam.inria.fr/fungraph/reduced_3dgs/
A Hierarchical 3D Gaussian Representation for Real-Time Rendering of Very Large Datasets
Jun 17, 2024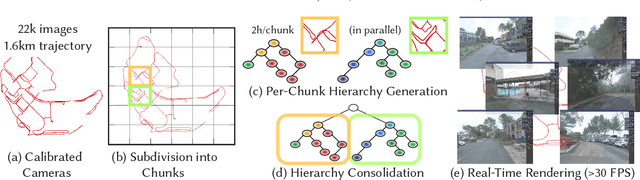
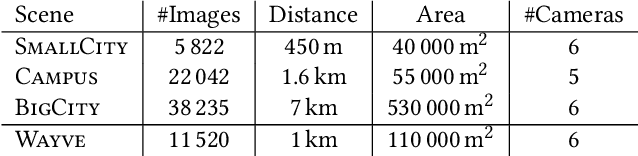
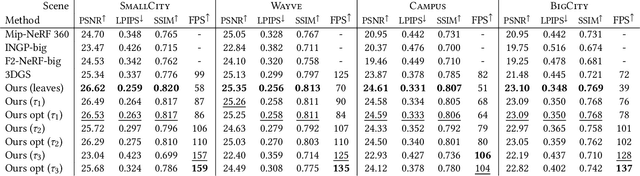
Novel view synthesis has seen major advances in recent years, with 3D Gaussian splatting offering an excellent level of visual quality, fast training and real-time rendering. However, the resources needed for training and rendering inevitably limit the size of the captured scenes that can be represented with good visual quality. We introduce a hierarchy of 3D Gaussians that preserves visual quality for very large scenes, while offering an efficient Level-of-Detail (LOD) solution for efficient rendering of distant content with effective level selection and smooth transitions between levels.We introduce a divide-and-conquer approach that allows us to train very large scenes in independent chunks. We consolidate the chunks into a hierarchy that can be optimized to further improve visual quality of Gaussians merged into intermediate nodes. Very large captures typically have sparse coverage of the scene, presenting many challenges to the original 3D Gaussian splatting training method; we adapt and regularize training to account for these issues. We present a complete solution, that enables real-time rendering of very large scenes and can adapt to available resources thanks to our LOD method. We show results for captured scenes with up to tens of thousands of images with a simple and affordable rig, covering trajectories of up to several kilometers and lasting up to one hour. Project Page: https://repo-sam.inria.fr/fungraph/hierarchical-3d-gaussians/
* Project Page: https://repo-sam.inria.fr/fungraph/hierarchical-3d-gaussians/
N-Dimensional Gaussians for Fitting of High Dimensional Functions
May 31, 2024In the wake of many new ML-inspired approaches for reconstructing and representing high-quality 3D content, recent hybrid and explicitly learned representations exhibit promising performance and quality characteristics. However, their scaling to higher dimensions is challenging, e.g. when accounting for dynamic content with respect to additional parameters such as material properties, illumination, or time. In this paper, we tackle these challenges for an explicit representations based on Gaussian mixture models. With our solutions, we arrive at efficient fitting of compact N-dimensional Gaussian mixtures and enable efficient evaluation at render time: For fast fitting and evaluation, we introduce a high-dimensional culling scheme that efficiently bounds N-D Gaussians, inspired by Locality Sensitive Hashing. For adaptive refinement yet compact representation, we introduce a loss-adaptive density control scheme that incrementally guides the use of additional capacity towards missing details. With these tools we can for the first time represent complex appearance that depends on many input dimensions beyond position or viewing angle within a compact, explicit representation optimized in minutes and rendered in milliseconds.
Improving NeRF Quality by Progressive Camera Placement for Unrestricted Navigation in Complex Environments
Sep 04, 2023
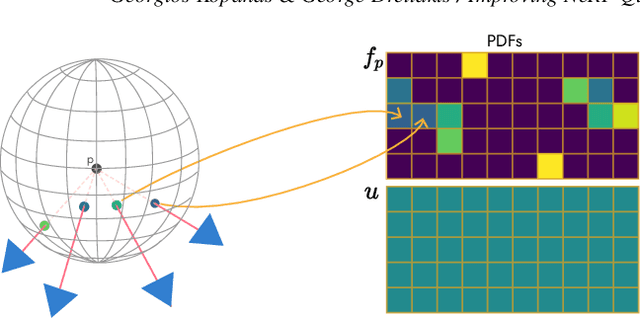
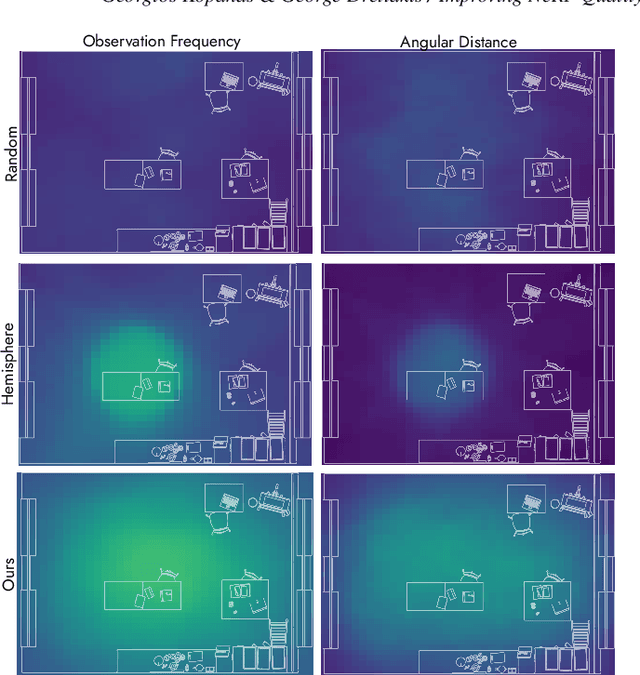
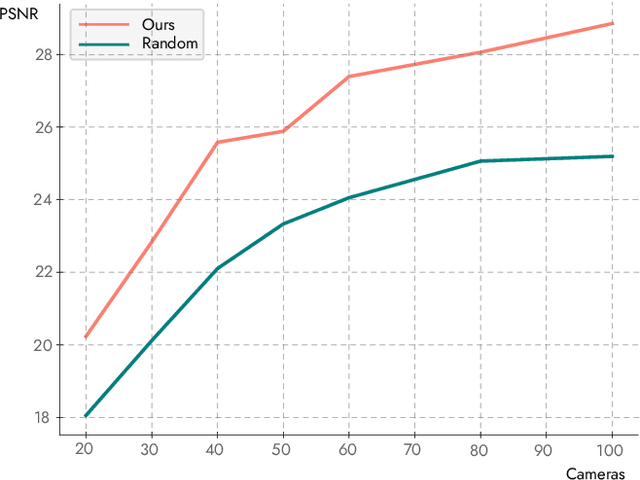
Neural Radiance Fields, or NeRFs, have drastically improved novel view synthesis and 3D reconstruction for rendering. NeRFs achieve impressive results on object-centric reconstructions, but the quality of novel view synthesis with free-viewpoint navigation in complex environments (rooms, houses, etc) is often problematic. While algorithmic improvements play an important role in the resulting quality of novel view synthesis, in this work, we show that because optimizing a NeRF is inherently a data-driven process, good quality data play a fundamental role in the final quality of the reconstruction. As a consequence, it is critical to choose the data samples -- in this case the cameras -- in a way that will eventually allow the optimization to converge to a solution that allows free-viewpoint navigation with good quality. Our main contribution is an algorithm that efficiently proposes new camera placements that improve visual quality with minimal assumptions. Our solution can be used with any NeRF model and outperforms baselines and similar work.
Dynamic 3D Gaussians: Tracking by Persistent Dynamic View Synthesis
Aug 18, 2023



We present a method that simultaneously addresses the tasks of dynamic scene novel-view synthesis and six degree-of-freedom (6-DOF) tracking of all dense scene elements. We follow an analysis-by-synthesis framework, inspired by recent work that models scenes as a collection of 3D Gaussians which are optimized to reconstruct input images via differentiable rendering. To model dynamic scenes, we allow Gaussians to move and rotate over time while enforcing that they have persistent color, opacity, and size. By regularizing Gaussians' motion and rotation with local-rigidity constraints, we show that our Dynamic 3D Gaussians correctly model the same area of physical space over time, including the rotation of that space. Dense 6-DOF tracking and dynamic reconstruction emerges naturally from persistent dynamic view synthesis, without requiring any correspondence or flow as input. We demonstrate a large number of downstream applications enabled by our representation, including first-person view synthesis, dynamic compositional scene synthesis, and 4D video editing.
3D Gaussian Splatting for Real-Time Radiance Field Rendering
Aug 08, 2023



Radiance Field methods have recently revolutionized novel-view synthesis of scenes captured with multiple photos or videos. However, achieving high visual quality still requires neural networks that are costly to train and render, while recent faster methods inevitably trade off speed for quality. For unbounded and complete scenes (rather than isolated objects) and 1080p resolution rendering, no current method can achieve real-time display rates. We introduce three key elements that allow us to achieve state-of-the-art visual quality while maintaining competitive training times and importantly allow high-quality real-time (>= 30 fps) novel-view synthesis at 1080p resolution. First, starting from sparse points produced during camera calibration, we represent the scene with 3D Gaussians that preserve desirable properties of continuous volumetric radiance fields for scene optimization while avoiding unnecessary computation in empty space; Second, we perform interleaved optimization/density control of the 3D Gaussians, notably optimizing anisotropic covariance to achieve an accurate representation of the scene; Third, we develop a fast visibility-aware rendering algorithm that supports anisotropic splatting and both accelerates training and allows realtime rendering. We demonstrate state-of-the-art visual quality and real-time rendering on several established datasets.
* https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
Neural Point Catacaustics for Novel-View Synthesis of Reflections
Jan 03, 2023



View-dependent effects such as reflections pose a substantial challenge for image-based and neural rendering algorithms. Above all, curved reflectors are particularly hard, as they lead to highly non-linear reflection flows as the camera moves. We introduce a new point-based representation to compute Neural Point Catacaustics allowing novel-view synthesis of scenes with curved reflectors, from a set of casually-captured input photos. At the core of our method is a neural warp field that models catacaustic trajectories of reflections, so complex specular effects can be rendered using efficient point splatting in conjunction with a neural renderer. One of our key contributions is the explicit representation of reflections with a reflection point cloud which is displaced by the neural warp field, and a primary point cloud which is optimized to represent the rest of the scene. After a short manual annotation step, our approach allows interactive high-quality renderings of novel views with accurate reflection flow. Additionally, the explicit representation of reflection flow supports several forms of scene manipulation in captured scenes, such as reflection editing, cloning of specular objects, reflection tracking across views, and comfortable stereo viewing. We provide the source code and other supplemental material on https://repo-sam.inria.fr/ fungraph/neural_catacaustics/
* SIGGRAPH Asia 2022 (ToG) https://repo-sam.inria.fr/fungraph/neural_catacaustics/
Point-Based Neural Rendering with Per-View Optimization
Sep 08, 2021There has recently been great interest in neural rendering methods. Some approaches use 3D geometry reconstructed with Multi-View Stereo (MVS) but cannot recover from the errors of this process, while others directly learn a volumetric neural representation, but suffer from expensive training and inference. We introduce a general approach that is initialized with MVS, but allows further optimization of scene properties in the space of input views, including depth and reprojected features, resulting in improved novel-view synthesis. A key element of our approach is our new differentiable point-based pipeline, based on bi-directional Elliptical Weighted Average splatting, a probabilistic depth test and effective camera selection. We use these elements together in our neural renderer, that outperforms all previous methods both in quality and speed in almost all scenes we tested. Our pipeline can be applied to multi-view harmonization and stylization in addition to novel-view synthesis.
* https://repo-sam.inria.fr/fungraph/differentiable-multi-view/