 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCGVQM+D: Computer Graphics Video Quality Metric and Dataset
Jun 13, 2025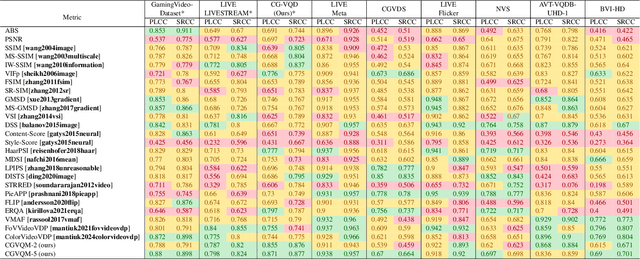



While existing video and image quality datasets have extensively studied natural videos and traditional distortions, the perception of synthetic content and modern rendering artifacts remains underexplored. We present a novel video quality dataset focused on distortions introduced by advanced rendering techniques, including neural supersampling, novel-view synthesis, path tracing, neural denoising, frame interpolation, and variable rate shading. Our evaluations show that existing full-reference quality metrics perform sub-optimally on these distortions, with a maximum Pearson correlation of 0.78. Additionally, we find that the feature space of pre-trained 3D CNNs aligns strongly with human perception of visual quality. We propose CGVQM, a full-reference video quality metric that significantly outperforms existing metrics while generating both per-pixel error maps and global quality scores. Our dataset and metric implementation is available at https://github.com/IntelLabs/CGVQM.
Image-GS: Content-Adaptive Image Representation via 2D Gaussians
Jul 02, 2024Neural image representations have recently emerged as a promising technique for storing, streaming, and rendering visual data. Coupled with learning-based workflows, these novel representations have demonstrated remarkable visual fidelity and memory efficiency. However, existing neural image representations often rely on explicit uniform data structures without content adaptivity or computation-intensive implicit models, limiting their adoption in real-time graphics applications. Inspired by recent advances in radiance field rendering, we propose Image-GS, a content-adaptive image representation. Using anisotropic 2D Gaussians as the basis, Image-GS shows high memory efficiency, supports fast random access, and offers a natural level of detail stack. Leveraging a tailored differentiable renderer, Image-GS fits a target image by adaptively allocating and progressively optimizing a set of 2D Gaussians. The generalizable efficiency and fidelity of Image-GS are validated against several recent neural image representations and industry-standard texture compressors on a diverse set of images. Notably, its memory and computation requirements solely depend on and linearly scale with the number of 2D Gaussians, providing flexible controls over the trade-off between visual fidelity and run-time efficiency. We hope this research offers insights for developing new applications that require adaptive quality and resource control, such as machine perception, asset streaming, and content generation.
N-Dimensional Gaussians for Fitting of High Dimensional Functions
May 31, 2024In the wake of many new ML-inspired approaches for reconstructing and representing high-quality 3D content, recent hybrid and explicitly learned representations exhibit promising performance and quality characteristics. However, their scaling to higher dimensions is challenging, e.g. when accounting for dynamic content with respect to additional parameters such as material properties, illumination, or time. In this paper, we tackle these challenges for an explicit representations based on Gaussian mixture models. With our solutions, we arrive at efficient fitting of compact N-dimensional Gaussian mixtures and enable efficient evaluation at render time: For fast fitting and evaluation, we introduce a high-dimensional culling scheme that efficiently bounds N-D Gaussians, inspired by Locality Sensitive Hashing. For adaptive refinement yet compact representation, we introduce a loss-adaptive density control scheme that incrementally guides the use of additional capacity towards missing details. With these tools we can for the first time represent complex appearance that depends on many input dimensions beyond position or viewing angle within a compact, explicit representation optimized in minutes and rendered in milliseconds.
Deep Appearance Prefiltering
Nov 08, 2022



Physically based rendering of complex scenes can be prohibitively costly with a potentially unbounded and uneven distribution of complexity across the rendered image. The goal of an ideal level of detail (LoD) method is to make rendering costs independent of the 3D scene complexity, while preserving the appearance of the scene. However, current prefiltering LoD methods are limited in the appearances they can support due to their reliance of approximate models and other heuristics. We propose the first comprehensive multi-scale LoD framework for prefiltering 3D environments with complex geometry and materials (e.g., the Disney BRDF), while maintaining the appearance with respect to the ray-traced reference. Using a multi-scale hierarchy of the scene, we perform a data-driven prefiltering step to obtain an appearance phase function and directional coverage mask at each scale. At the heart of our approach is a novel neural representation that encodes this information into a compact latent form that is easy to decode inside a physically based renderer. Once a scene is baked out, our method requires no original geometry, materials, or textures at render time. We demonstrate that our approach compares favorably to state-of-the-art prefiltering methods and achieves considerable savings in memory for complex scenes.
DONeRF: Towards Real-Time Rendering of Neural Radiance Fields using Depth Oracle Networks
Mar 11, 2021
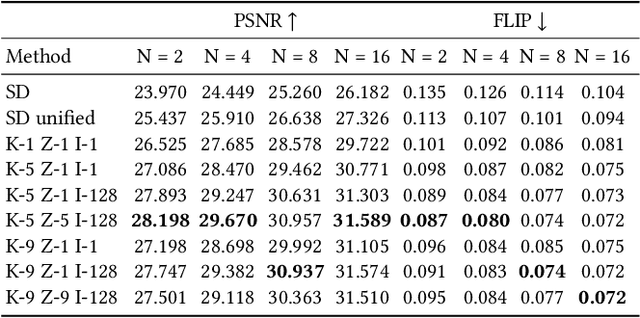
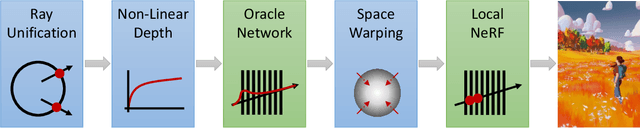
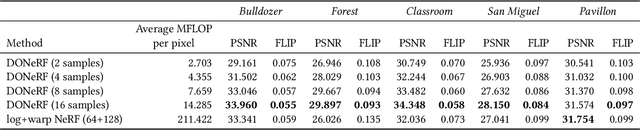
The recent research explosion around implicit neural representations, such as NeRF, shows that there is immense potential for implicitly storing high-quality scene and lighting information in neural networks. However, one major limitation preventing the use of NeRF in interactive and real-time rendering applications is the prohibitive computational cost of excessive network evaluations along each view ray, requiring dozens of petaFLOPS when aiming for real-time rendering on consumer hardware. In this work, we take a step towards bringing neural representations closer to practical rendering of synthetic content in interactive and real-time applications, such as games and virtual reality. We show that the number of samples required for each view ray can be significantly reduced when local samples are placed around surfaces in the scene. To this end, we propose a depth oracle network, which predicts ray sample locations for each view ray with a single network evaluation. We show that using a classification network around logarithmically discretized and spherically warped depth values is essential to encode surface locations rather than directly estimating depth. The combination of these techniques leads to DONeRF, a dual network design with a depth oracle network as a first step and a locally sampled shading network for ray accumulation. With our design, we reduce the inference costs by up to 48x compared to NeRF. Using an off-the-shelf inference API in combination with simple compute kernels, we are the first to render raymarching-based neural representations at interactive frame rates (15 frames per second at 800x800) on a single GPU. At the same time, since we focus on the important parts of the scene around surfaces, we achieve equal or better quality compared to NeRF to enable interactive high-quality rendering.
Inverse Path Tracing for Joint Material and Lighting Estimation
Mar 17, 2019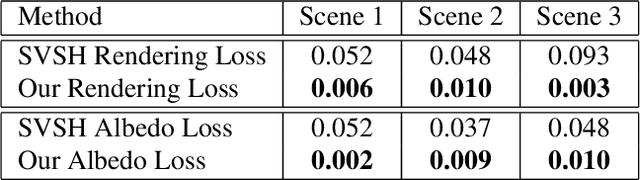

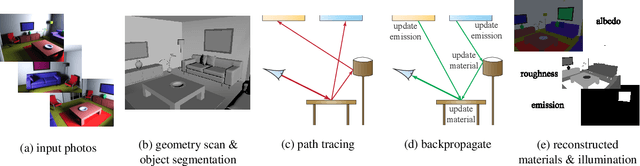

Modern computer vision algorithms have brought significant advancement to 3D geometry reconstruction. However, illumination and material reconstruction remain less studied, with current approaches assuming very simplified models for materials and illumination. We introduce Inverse Path Tracing, a novel approach to jointly estimate the material properties of objects and light sources in indoor scenes by using an invertible light transport simulation. We assume a coarse geometry scan, along with corresponding images and camera poses. The key contribution of this work is an accurate and simultaneous retrieval of light sources and physically based material properties (e.g., diffuse reflectance, specular reflectance, roughness, etc.) for the purpose of editing and re-rendering the scene under new conditions. To this end, we introduce a novel optimization method using a differentiable Monte Carlo renderer that computes derivatives with respect to the estimated unknown illumination and material properties. This enables joint optimization for physically correct light transport and material models using a tailored stochastic gradient descent.