 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Control for Geometry-Conditioned PBR Image Generation
Feb 20, 2024Current 3D content generation approaches build on diffusion models that output RGB images. Modern graphics pipelines, however, require physically-based rendering (PBR) material properties. We propose to model the PBR image distribution directly, avoiding photometric inaccuracies in RGB generation and the inherent ambiguity in extracting PBR from RGB. Existing paradigms for cross-modal fine-tuning are not suited for PBR generation due to both a lack of data and the high dimensionality of the output modalities: we overcome both challenges by retaining a frozen RGB model and tightly linking a newly trained PBR model using a novel cross-network communication paradigm. As the base RGB model is fully frozen, the proposed method does not risk catastrophic forgetting during fine-tuning and remains compatible with techniques such as IPAdapter pretrained for the base RGB model. We validate our design choices, robustness to data sparsity, and compare against existing paradigms with an extensive experimental section.
StopThePop: Sorted Gaussian Splatting for View-Consistent Real-time Rendering
Feb 01, 2024


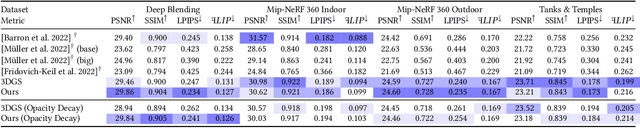
Gaussian Splatting has emerged as a prominent model for constructing 3D representations from images across diverse domains. However, the efficiency of the 3D Gaussian Splatting rendering pipeline relies on several simplifications. Notably, reducing Gaussian to 2D splats with a single view-space depth introduces popping and blending artifacts during view rotation. Addressing this issue requires accurate per-pixel depth computation, yet a full per-pixel sort proves excessively costly compared to a global sort operation. In this paper, we present a novel hierarchical rasterization approach that systematically resorts and culls splats with minimal processing overhead. Our software rasterizer effectively eliminates popping artifacts and view inconsistencies, as demonstrated through both quantitative and qualitative measurements. Simultaneously, our method mitigates the potential for cheating view-dependent effects with popping, ensuring a more authentic representation. Despite the elimination of cheating, our approach achieves comparable quantitative results for test images, while increasing the consistency for novel view synthesis in motion. Due to its design, our hierarchical approach is only 4% slower on average than the original Gaussian Splatting. Notably, enforcing consistency enables a reduction in the number of Gaussians by approximately half with nearly identical quality and view-consistency. Consequently, rendering performance is nearly doubled, making our approach 1.6x faster than the original Gaussian Splatting, with a 50% reduction in memory requirements.
Gradient-based Weight Density Balancing for Robust Dynamic Sparse Training
Nov 03, 2022Training a sparse neural network from scratch requires optimizing connections at the same time as the weights themselves. Typically, the weights are redistributed after a predefined number of weight updates, removing a fraction of the parameters of each layer and inserting them at different locations in the same layers. The density of each layer is determined using heuristics, often purely based on the size of the parameter tensor. While the connections per layer are optimized multiple times during training, the density of each layer remains constant. This leaves great unrealized potential, especially in scenarios with a high sparsity of 90% and more. We propose Global Gradient-based Redistribution, a technique which distributes weights across all layers - adding more weights to the layers that need them most. Our evaluation shows that our approach is less prone to unbalanced weight distribution at initialization than previous work and that it is able to find better performing sparse subnetworks at very high sparsity levels.
MotionDeltaCNN: Sparse CNN Inference of Frame Differences in Moving Camera Videos
Oct 18, 2022
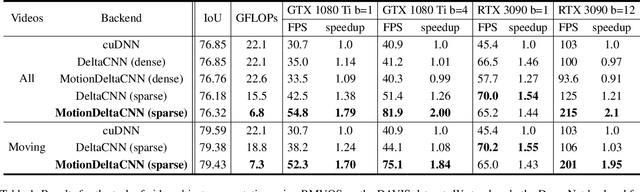

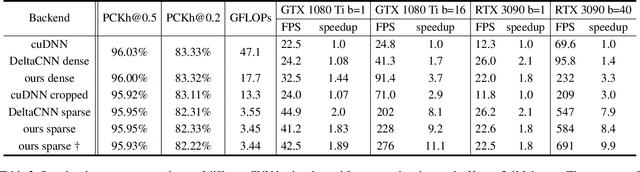
Convolutional neural network inference on video input is computationally expensive and has high memory bandwidth requirements. Recently, researchers managed to reduce the cost of processing upcoming frames by only processing pixels that changed significantly. Using sparse convolutions, the sparsity of frame differences can be translated to speedups on current inference devices. However, previous work was relying on static cameras. Moving cameras add new challenges in how to fuse newly unveiled image regions with already processed regions efficiently to minimize the update rate - without increasing memory overhead and without knowing the camera extrinsics of future frames. In this work, we propose MotionDeltaCNN, a CNN framework that supports moving cameras and variable resolution input. We propose a spherical buffer which enables seamless fusion of newly unveiled regions and previously processed regions - without increasing the memory footprint. Our evaluations show that we outperform previous work significantly by explicitly adding support for moving camera input.
DeltaCNN: End-to-End CNN Inference of Sparse Frame Differences in Videos
Mar 08, 2022
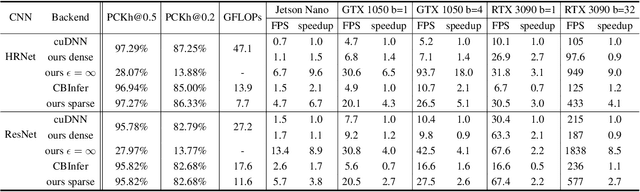


Convolutional neural network inference on video data requires powerful hardware for real-time processing. Given the inherent coherence across consecutive frames, large parts of a video typically change little. By skipping identical image regions and truncating insignificant pixel updates, computational redundancy can in theory be reduced significantly. However, these theoretical savings have been difficult to translate into practice, as sparse updates hamper computational consistency and memory access coherence; which are key for efficiency on real hardware. With DeltaCNN, we present a sparse convolutional neural network framework that enables sparse frame-by-frame updates to accelerate video inference in practice. We provide sparse implementations for all typical CNN layers and propagate sparse feature updates end-to-end - without accumulating errors over time. DeltaCNN is applicable to all convolutional neural networks without retraining. To the best of our knowledge, we are the first to significantly outperform the dense reference, cuDNN, in practical settings, achieving speedups of up to 7x with only marginal differences in accuracy.
DONeRF: Towards Real-Time Rendering of Neural Radiance Fields using Depth Oracle Networks
Mar 11, 2021
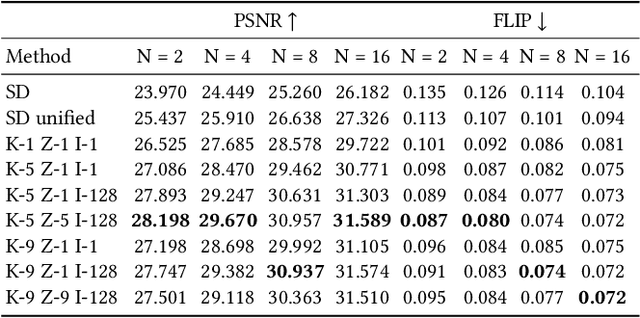
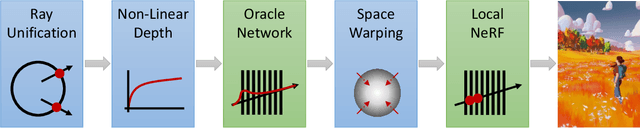
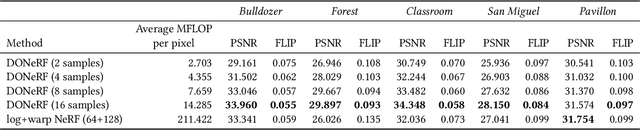
The recent research explosion around implicit neural representations, such as NeRF, shows that there is immense potential for implicitly storing high-quality scene and lighting information in neural networks. However, one major limitation preventing the use of NeRF in interactive and real-time rendering applications is the prohibitive computational cost of excessive network evaluations along each view ray, requiring dozens of petaFLOPS when aiming for real-time rendering on consumer hardware. In this work, we take a step towards bringing neural representations closer to practical rendering of synthetic content in interactive and real-time applications, such as games and virtual reality. We show that the number of samples required for each view ray can be significantly reduced when local samples are placed around surfaces in the scene. To this end, we propose a depth oracle network, which predicts ray sample locations for each view ray with a single network evaluation. We show that using a classification network around logarithmically discretized and spherically warped depth values is essential to encode surface locations rather than directly estimating depth. The combination of these techniques leads to DONeRF, a dual network design with a depth oracle network as a first step and a locally sampled shading network for ray accumulation. With our design, we reduce the inference costs by up to 48x compared to NeRF. Using an off-the-shelf inference API in combination with simple compute kernels, we are the first to render raymarching-based neural representations at interactive frame rates (15 frames per second at 800x800) on a single GPU. At the same time, since we focus on the important parts of the scene around surfaces, we achieve equal or better quality compared to NeRF to enable interactive high-quality rendering.
UNOC: Understanding Occlusion for Embodied Presence in Virtual Reality
Nov 12, 2020
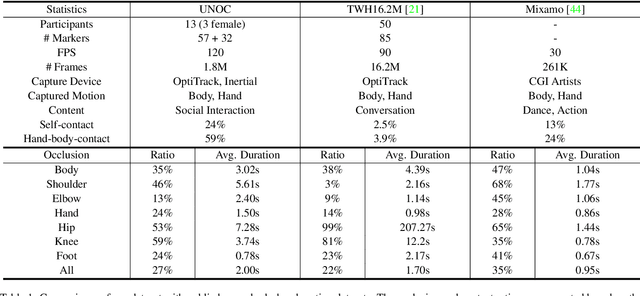


Tracking body and hand motions in the 3D space is essential for social and self-presence in augmented and virtual environments. Unlike the popular 3D pose estimation setting, the problem is often formulated as inside-out tracking based on embodied perception (e.g., egocentric cameras, handheld sensors). In this paper, we propose a new data-driven framework for inside-out body tracking, targeting challenges of omnipresent occlusions in optimization-based methods (e.g., inverse kinematics solvers). We first collect a large-scale motion capture dataset with both body and finger motions using optical markers and inertial sensors. This dataset focuses on social scenarios and captures ground truth poses under self-occlusions and body-hand interactions. We then simulate the occlusion patterns in head-mounted camera views on the captured ground truth using a ray casting algorithm and learn a deep neural network to infer the occluded body parts. In the experiments, we show that our method is able to generate high-fidelity embodied poses by applying the proposed method on the task of real-time inside-out body tracking, finger motion synthesis, and 3-point inverse kinematics.