 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionDeltaCNN: Sparse CNN Inference of Frame Differences in Moving Camera Videos
Paper and Code
Oct 18, 2022
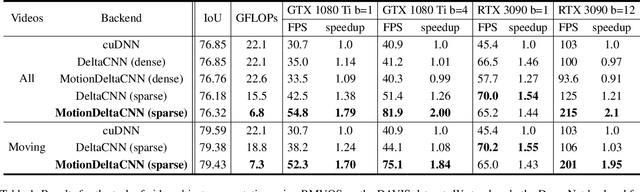

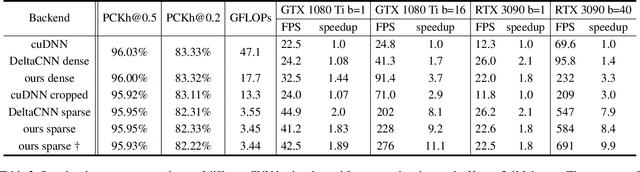
Convolutional neural network inference on video input is computationally expensive and has high memory bandwidth requirements. Recently, researchers managed to reduce the cost of processing upcoming frames by only processing pixels that changed significantly. Using sparse convolutions, the sparsity of frame differences can be translated to speedups on current inference devices. However, previous work was relying on static cameras. Moving cameras add new challenges in how to fuse newly unveiled image regions with already processed regions efficiently to minimize the update rate - without increasing memory overhead and without knowing the camera extrinsics of future frames. In this work, we propose MotionDeltaCNN, a CNN framework that supports moving cameras and variable resolution input. We propose a spherical buffer which enables seamless fusion of newly unveiled regions and previously processed regions - without increasing the memory footprint. Our evaluations show that we outperform previous work significantly by explicitly adding support for moving camera input.