 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Estimation of Fingertip Pressure on Diverse Surfaces using Easily Captured Data
Jan 05, 2023


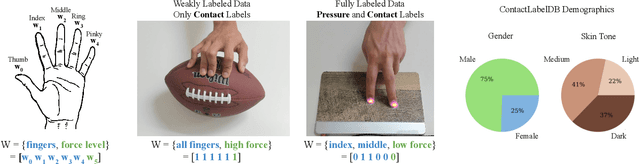
Prior research has shown that deep models can estimate the pressure applied by a hand to a surface based on a single RGB image. Training these models requires high-resolution pressure measurements that are difficult to obtain with physical sensors. Additionally, even experts cannot reliably annotate pressure from images. Thus, data collection is a critical barrier to generalization and improved performance. We present a novel approach that enables training data to be efficiently captured from unmodified surfaces with only an RGB camera and a cooperative participant. Our key insight is that people can be prompted to perform actions that correspond with categorical labels (contact labels) describing contact pressure, such as using a specific fingertip to make low-force contact. We present ContactLabelNet, which visually estimates pressure applied by fingertips. With the use of contact labels, ContactLabelNet achieves improved performance, generalizes to novel surfaces, and outperforms models from prior work.
MotionDeltaCNN: Sparse CNN Inference of Frame Differences in Moving Camera Videos
Oct 18, 2022
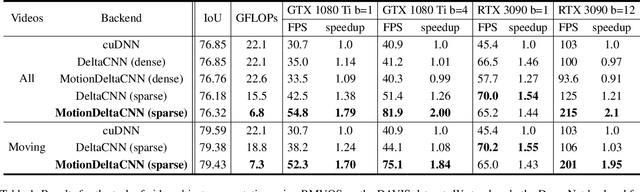

Convolutional neural network inference on video input is computationally expensive and has high memory bandwidth requirements. Recently, researchers managed to reduce the cost of processing upcoming frames by only processing pixels that changed significantly. Using sparse convolutions, the sparsity of frame differences can be translated to speedups on current inference devices. However, previous work was relying on static cameras. Moving cameras add new challenges in how to fuse newly unveiled image regions with already processed regions efficiently to minimize the update rate - without increasing memory overhead and without knowing the camera extrinsics of future frames. In this work, we propose MotionDeltaCNN, a CNN framework that supports moving cameras and variable resolution input. We propose a spherical buffer which enables seamless fusion of newly unveiled regions and previously processed regions - without increasing the memory footprint. Our evaluations show that we outperform previous work significantly by explicitly adding support for moving camera input.
Visual Pressure Estimation and Control for Soft Robotic Grippers
Apr 14, 2022



Soft robotic grippers facilitate contact-rich manipulation, including robust grasping of varied objects. Yet the beneficial compliance of a soft gripper also results in significant deformation that can make precision manipulation challenging. We present visual pressure estimation & control (VPEC), a method that uses a single RGB image of an unmodified soft gripper from an external camera to directly infer pressure applied to the world by the gripper. We present inference results for a pneumatic gripper and a tendon-actuated gripper making contact with a flat surface. We also show that VPEC enables precision manipulation via closed-loop control of inferred pressure. We present results for a mobile manipulator (Stretch RE1 from Hello Robot) using visual servoing to do the following: achieve target pressures when making contact; follow a spatial pressure trajectory; and grasp small objects, including a microSD card, a washer, a penny, and a pill. Overall, our results show that VPEC enables grippers with high compliance to perform precision manipulation.
PressureVision: Estimating Hand Pressure from a Single RGB Image
Mar 19, 2022

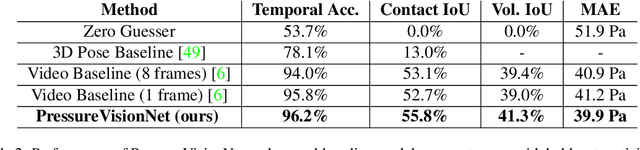

People often interact with their surroundings by applying pressure with their hands. Machine perception of hand pressure has been limited by the challenges of placing sensors between the hand and the contact surface. We explore the possibility of using a conventional RGB camera to infer hand pressure. The central insight is that the application of pressure by a hand results in informative appearance changes. Hands share biomechanical properties that result in similar observable phenomena, such as soft-tissue deformation, blood distribution, hand pose, and cast shadows. We collected videos of 36 participants with diverse skin tone applying pressure to an instrumented planar surface. We then trained a deep model (PressureVisionNet) to infer a pressure image from a single RGB image. Our model infers pressure for participants outside of the training data and outperforms baselines. We also show that the output of our model depends on the appearance of the hand and cast shadows near contact regions. Overall, our results suggest the appearance of a previously unobserved human hand can be used to accurately infer applied pressure.
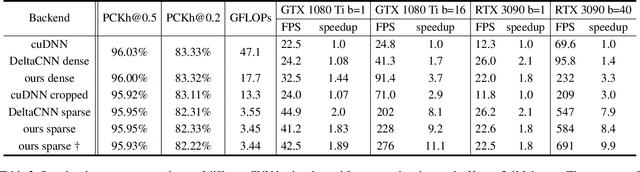
DeltaCNN: End-to-End CNN Inference of Sparse Frame Differences in Videos
Mar 08, 2022
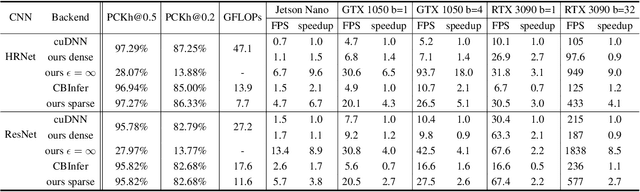


Convolutional neural network inference on video data requires powerful hardware for real-time processing. Given the inherent coherence across consecutive frames, large parts of a video typically change little. By skipping identical image regions and truncating insignificant pixel updates, computational redundancy can in theory be reduced significantly. However, these theoretical savings have been difficult to translate into practice, as sparse updates hamper computational consistency and memory access coherence; which are key for efficiency on real hardware. With DeltaCNN, we present a sparse convolutional neural network framework that enables sparse frame-by-frame updates to accelerate video inference in practice. We provide sparse implementations for all typical CNN layers and propagate sparse feature updates end-to-end - without accumulating errors over time. DeltaCNN is applicable to all convolutional neural networks without retraining. To the best of our knowledge, we are the first to significantly outperform the dense reference, cuDNN, in practical settings, achieving speedups of up to 7x with only marginal differences in accuracy.
Identity-Disentangled Neural Deformation Model for Dynamic Meshes
Oct 04, 2021
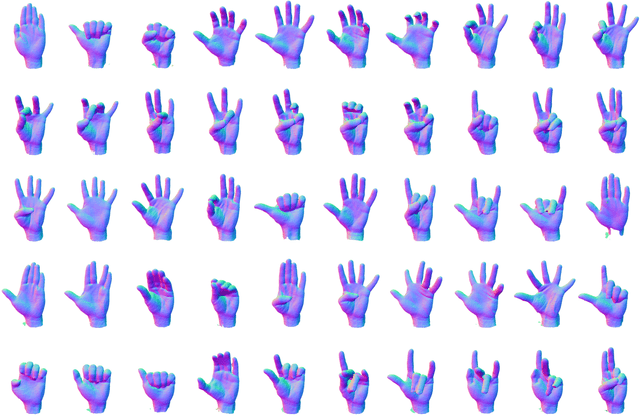


Neural shape models can represent complex 3D shapes with a compact latent space. When applied to dynamically deforming shapes such as the human hands, however, they would need to preserve temporal coherence of the deformation as well as the intrinsic identity of the subject. These properties are difficult to regularize with manually designed loss functions. In this paper, we learn a neural deformation model that disentangles the identity-induced shape variations from pose-dependent deformations using implicit neural functions. We perform template-free unsupervised learning on 3D scans without explicit mesh correspondence or semantic correspondences of shapes across subjects. We can then apply the learned model to reconstruct partial dynamic 4D scans of novel subjects performing unseen actions. We propose two methods to integrate global pose alignment with our neural deformation model. Experiments demonstrate the efficacy of our method in the disentanglement of identities and pose. Our method also outperforms traditional skeleton-driven models in reconstructing surface details such as palm prints or tendons without limitations from a fixed template.
ContactOpt: Optimizing Contact to Improve Grasps
Apr 15, 2021
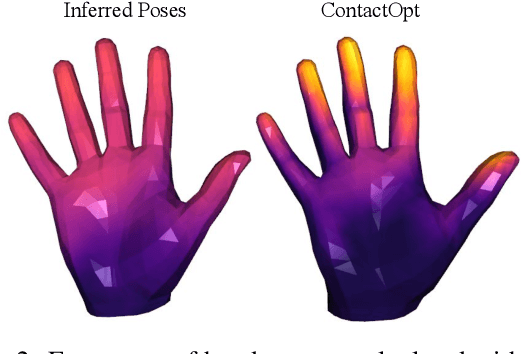
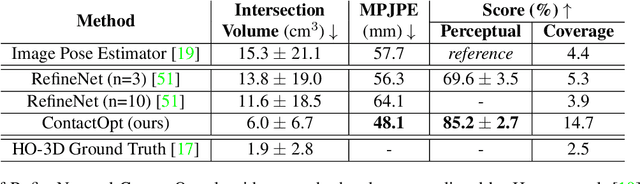

Physical contact between hands and objects plays a critical role in human grasps. We show that optimizing the pose of a hand to achieve expected contact with an object can improve hand poses inferred via image-based methods. Given a hand mesh and an object mesh, a deep model trained on ground truth contact data infers desirable contact across the surfaces of the meshes. Then, ContactOpt efficiently optimizes the pose of the hand to achieve desirable contact using a differentiable contact model. Notably, our contact model encourages mesh interpenetration to approximate deformable soft tissue in the hand. In our evaluations, our methods result in grasps that better match ground truth contact, have lower kinematic error, and are significantly preferred by human participants. Code and models are available online.
ContactPose: A Dataset of Grasps with Object Contact and Hand Pose
Jul 19, 2020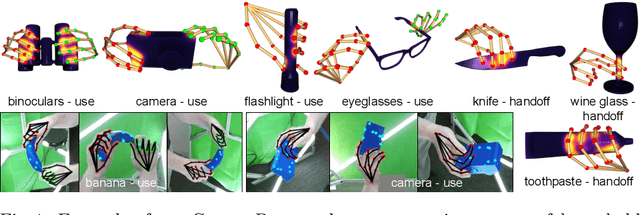
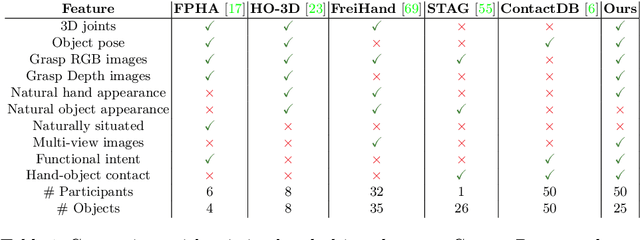
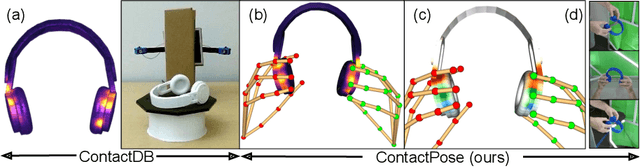
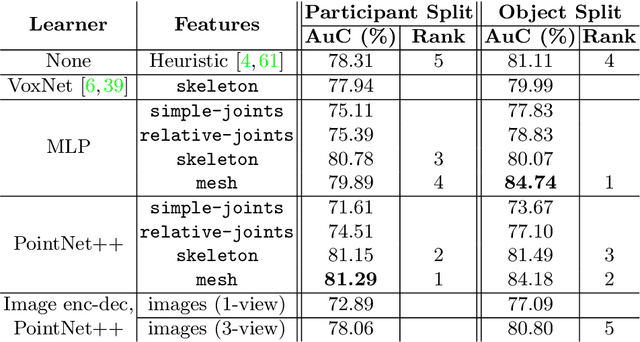
Grasping is natural for humans. However, it involves complex hand configurations and soft tissue deformation that can result in complicated regions of contact between the hand and the object. Understanding and modeling this contact can potentially improve hand models, AR/VR experiences, and robotic grasping. Yet, we currently lack datasets of hand-object contact paired with other data modalities, which is crucial for developing and evaluating contact modeling techniques. We introduce ContactPose, the first dataset of hand-object contact paired with hand pose, object pose, and RGB-D images. ContactPose has 2306 unique grasps of 25 household objects grasped with 2 functional intents by 50 participants, and more than 2.9 M RGB-D grasp images. Analysis of ContactPose data reveals interesting relationships between hand pose and contact. We use this data to rigorously evaluate various data representations, heuristics from the literature, and learning methods for contact modeling. Data, code, and trained models are available at https://contactpose.cc.gatech.edu.