 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOET: Prompt Offset Tuning for Continual Human Action Adaptation
Apr 25, 2025As extended reality (XR) is redefining how users interact with computing devices, research in human action recognition is gaining prominence. Typically, models deployed on immersive computing devices are static and limited to their default set of classes. The goal of our research is to provide users and developers with the capability to personalize their experience by adding new action classes to their device models continually. Importantly, a user should be able to add new classes in a low-shot and efficient manner, while this process should not require storing or replaying any of user's sensitive training data. We formalize this problem as privacy-aware few-shot continual action recognition. Towards this end, we propose POET: Prompt-Offset Tuning. While existing prompt tuning approaches have shown great promise for continual learning of image, text, and video modalities; they demand access to extensively pretrained transformers. Breaking away from this assumption, POET demonstrates the efficacy of prompt tuning a significantly lightweight backbone, pretrained exclusively on the base class data. We propose a novel spatio-temporal learnable prompt offset tuning approach, and are the first to apply such prompt tuning to Graph Neural Networks. We contribute two new benchmarks for our new problem setting in human action recognition: (i) NTU RGB+D dataset for activity recognition, and (ii) SHREC-2017 dataset for hand gesture recognition. We find that POET consistently outperforms comprehensive benchmarks. Source code at https://github.com/humansensinglab/POET-continual-action-recognition.
* ECCV 2024 (Oral), webpage https://humansensinglab.github.io/POET-continual-action-recognition/
PressureVision: Estimating Hand Pressure from a Single RGB Image
Mar 19, 2022

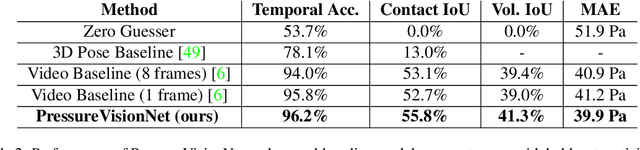

People often interact with their surroundings by applying pressure with their hands. Machine perception of hand pressure has been limited by the challenges of placing sensors between the hand and the contact surface. We explore the possibility of using a conventional RGB camera to infer hand pressure. The central insight is that the application of pressure by a hand results in informative appearance changes. Hands share biomechanical properties that result in similar observable phenomena, such as soft-tissue deformation, blood distribution, hand pose, and cast shadows. We collected videos of 36 participants with diverse skin tone applying pressure to an instrumented planar surface. We then trained a deep model (PressureVisionNet) to infer a pressure image from a single RGB image. Our model infers pressure for participants outside of the training data and outperforms baselines. We also show that the output of our model depends on the appearance of the hand and cast shadows near contact regions. Overall, our results suggest the appearance of a previously unobserved human hand can be used to accurately infer applied pressure.
Dual Grid Net: hand mesh vertex regression from single depth maps
Jul 24, 2019


We present a method for recovering the dense 3D surface of the hand by regressing the vertex coordinates of a mesh model from a single depth map. To this end, we use a two-stage 2D fully convolutional network architecture. In the first stage, the network estimates a dense correspondence field for every pixel on the depth map or image grid to the mesh grid. In the second stage, we design a differentiable operator to map features learned from the previous stage and regress a 3D coordinate map on the mesh grid. Finally, we sample from the mesh grid to recover the mesh vertices, and fit it an articulated template mesh in closed form. During inference, the network can predict all the mesh vertices, transformation matrices for every joint and the joint coordinates in a single forward pass. When given supervision on the sparse key-point coordinates, our method achieves state-of-the-art accuracy on NYU dataset for key point localization while recovering mesh vertices and a dense correspondence map. Our framework can also be learned through self-supervision by minimizing a set of data fitting and kinematic prior terms. With multi-camera rig during training to resolve self-occlusion, it can perform competitively with strongly supervised methods Without any human annotation.
Dense 3D Regression for Hand Pose Estimation
Nov 24, 2017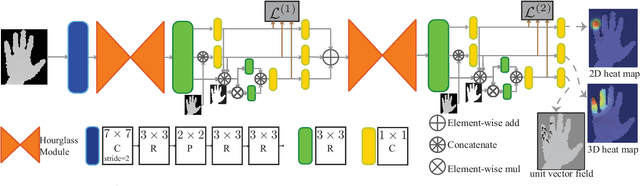



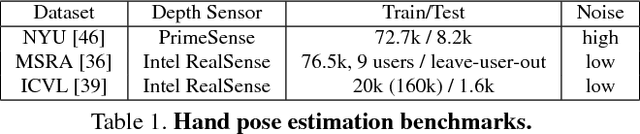
We present a simple and effective method for 3D hand pose estimation from a single depth frame. As opposed to previous state-of-the-art methods based on holistic 3D regression, our method works on dense pixel-wise estimation. This is achieved by careful design choices in pose parameterization, which leverages both 2D and 3D properties of depth map. Specifically, we decompose the pose parameters into a set of per-pixel estimations, i.e., 2D heat maps, 3D heat maps and unit 3D directional vector fields. The 2D/3D joint heat maps and 3D joint offsets are estimated via multi-task network cascades, which is trained end-to-end. The pixel-wise estimations can be directly translated into a vote casting scheme. A variant of mean shift is then used to aggregate local votes while enforcing consensus between the the estimated 3D pose and the pixel-wise 2D and 3D estimations by design. Our method is efficient and highly accurate. On MSRA and NYU hand dataset, our method outperforms all previous state-of-the-art approaches by a large margin. On the ICVL hand dataset, our method achieves similar accuracy compared to the currently proposed nearly saturated result and outperforms various other proposed methods. Code is available $\href{"https://github.com/melonwan/denseReg"}{\text{online}}$.
Crossing Nets: Combining GANs and VAEs with a Shared Latent Space for Hand Pose Estimation
Jul 18, 2017
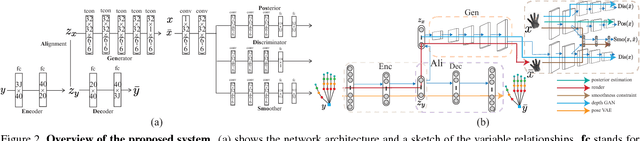

State-of-the-art methods for 3D hand pose estimation from depth images require large amounts of annotated training data. We propose to model the statistical relationships of 3D hand poses and corresponding depth images using two deep generative models with a shared latent space. By design, our architecture allows for learning from unlabeled image data in a semi-supervised manner. Assuming a one-to-one mapping between a pose and a depth map, any given point in the shared latent space can be projected into both a hand pose and a corresponding depth map. Regressing the hand pose can then be done by learning a discriminator to estimate the posterior of the latent pose given some depth maps. To improve generalization and to better exploit unlabeled depth maps, we jointly train a generator and a discriminator. At each iteration, the generator is updated with the back-propagated gradient from the discriminator to synthesize realistic depth maps of the articulated hand, while the discriminator benefits from an augmented training set of synthesized and unlabeled samples. The proposed discriminator network architecture is highly efficient and runs at 90 FPS on the CPU with accuracies comparable or better than state-of-art on 3 publicly available benchmarks.
Deep Learning on Lie Groups for Skeleton-based Action Recognition
Apr 11, 2017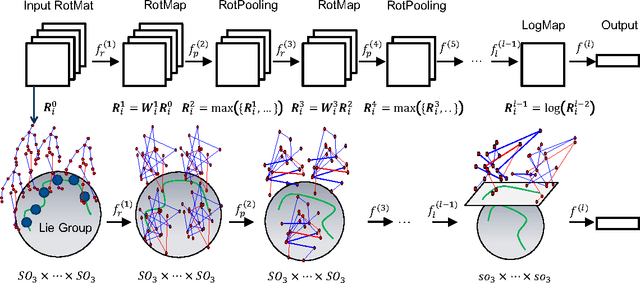
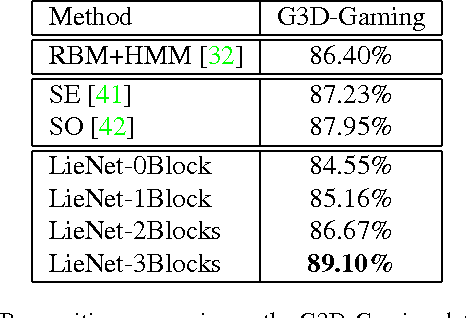
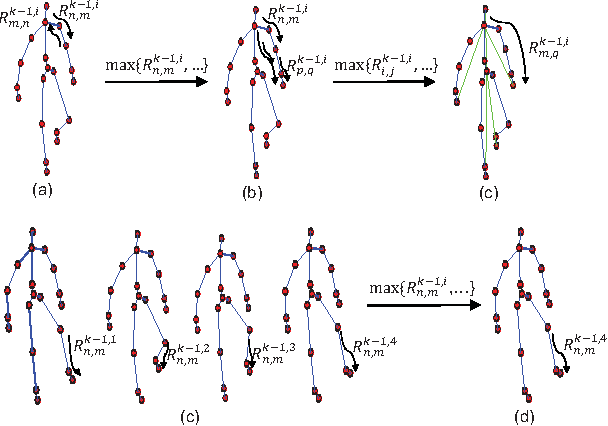
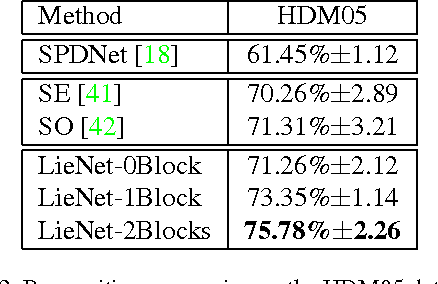
In recent years, skeleton-based action recognition has become a popular 3D classification problem. State-of-the-art methods typically first represent each motion sequence as a high-dimensional trajectory on a Lie group with an additional dynamic time warping, and then shallowly learn favorable Lie group features. In this paper we incorporate the Lie group structure into a deep network architecture to learn more appropriate Lie group features for 3D action recognition. Within the network structure, we design rotation mapping layers to transform the input Lie group features into desirable ones, which are aligned better in the temporal domain. To reduce the high feature dimensionality, the architecture is equipped with rotation pooling layers for the elements on the Lie group. Furthermore, we propose a logarithm mapping layer to map the resulting manifold data into a tangent space that facilitates the application of regular output layers for the final classification. Evaluations of the proposed network for standard 3D human action recognition datasets clearly demonstrate its superiority over existing shallow Lie group feature learning methods as well as most conventional deep learning methods.
Direction matters: hand pose estimation from local surface normals
Apr 10, 2016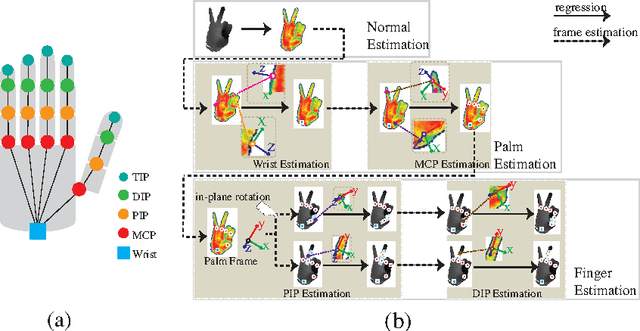
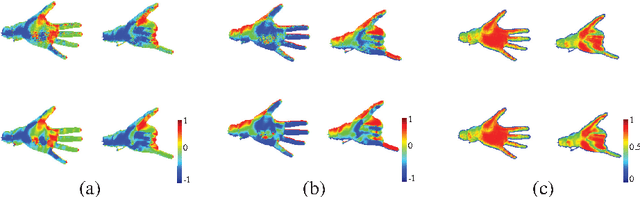
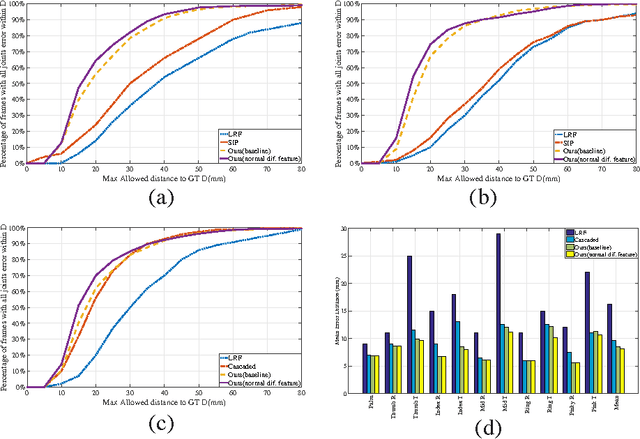

We present a hierarchical regression framework for estimating hand joint positions from single depth images based on local surface normals. The hierarchical regression follows the tree structured topology of hand from wrist to finger tips. We propose a conditional regression forest, i.e., the Frame Conditioned Regression Forest (FCRF) which uses a new normal difference feature. At each stage of the regression, the frame of reference is established from either the local surface normal or previously estimated hand joints. By making the regression with respect to the local frame, the pose estimation is more robust to rigid transformations. We also introduce a new efficient approximation to estimate surface normals. We verify the effectiveness of our method by conducting experiments on two challenging real-world datasets and show consistent improvements over previous discriminative pose estimation methods.
Towards Predicting the Likeability of Fashion Images
Nov 23, 2015

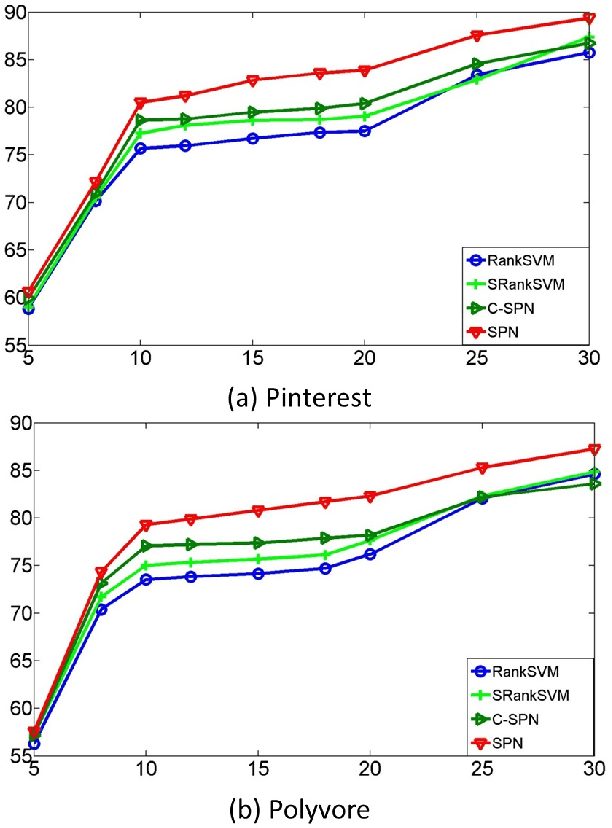
In this paper, we propose a method for ranking fashion images to find the ones which might be liked by more people. We collect two new datasets from image sharing websites (Pinterest and Polyvore). We represent fashion images based on attributes: semantic attributes and data-driven attributes. To learn semantic attributes from limited training data, we use an algorithm on multi-task convolutional neural networks to share visual knowledge among different semantic attribute categories. To discover data-driven attributes unsupervisedly, we propose an algorithm to simultaneously discover visual clusters and learn fashion-specific feature representations. Given attributes as representations, we propose to learn a ranking SPN (sum product networks) to rank pairs of fashion images. The proposed ranking SPN can capture the high-order correlations of the attributes. We show the effectiveness of our method on our two newly collected datasets.